


Participe de nossos boletins diários e semanais para as atualizações mais recentes e conteúdo exclusivo sobre a cobertura líder da indústria em IA. Saiba mais
Pesquisadores da UCLA e da Meta AI introduziram d1, uma nova estrutura que utiliza aprendizado por reforço (RL) para aprimorar significativamente as capacidades de raciocínio de modelos de linguagem baseados em difusão (dLLMs). Enquanto a maioria das atenções tem se concentrado em modelos autoregressivos como o GPT, os dLLMs oferecem vantagens únicas. Equipá-los com habilidades de raciocínio poderia desbloquear novas eficiências e aplicações para empresas.
Os dLLMs representam uma abordagem distinta para gerar texto em comparação com modelos autoregressivos padrão, oferecendo potenciais benefícios em eficiência e processamento de informações, o que poderia ser valioso para diversas aplicações do mundo real.
Compreendendo modelos de linguagem por difusão
A maioria dos grandes modelos de linguagem (LLMs), como GPT-4o e Llama, são autoregressivos (AR). Eles geram texto sequencialmente, prevendo o próximo token com base apenas nos tokens anteriores.
Os modelos de linguagem por difusão (dLLMs) funcionam de maneira diferente. Modelos de difusão foram inicialmente utilizados em modelos de geração de imagens como DALL-E 2, Midjourney e Stable Diffusion. A ideia central envolve adicionar ruído gradualmente a uma imagem até que se torne um estático puro, e então treinar um modelo para reverter meticulosamente esse processo, começando do ruído e refinando-o progressivamente em uma imagem coerente.
Adaptar esse conceito diretamente para a linguagem foi complicado, porque o texto é feito de unidades discretas (tokens), ao contrário dos valores contínuos de pixels em imagens. Os pesquisadores superaram isso desenvolvendo modelos de linguagem por difusão mascarados. Em vez de adicionar ruído contínuo, esses modelos trabalham mascarando aleatoriamente tokens em uma sequência e treinando o modelo para prever os tokens originais.
Isso resulta em um processo de geração diferente em comparação com modelos autoregressivos. Os dLLMs começam com uma versão fortemente mascarada do texto de entrada e gradualmente “desmascaram” ou refinam ao longo de várias etapas até que a saída final, coerente, emerja. Essa geração “bruta-fina” permite que os dLLMs considerem todo o contexto simultaneamente em cada etapa, ao contrário de se concentrar apenas no próximo token.
Essa diferença oferece aos dLLMs potenciais vantagens, como um aprimoramento do processamento paralelo durante a geração, que pode levar a uma inferência mais rápida, especialmente para sequências mais longas. Exemplos desse tipo de modelo incluem o LLaDA de código aberto e o modelo Mercury, de fonte fechada, da Inception Labs.
“Embora os LLMs autoregressivos possam usar raciocínio para melhorar a qualidade, essa melhoria vem a um custo computacional severo, com LLMs de raciocínio de ponta incurtindo mais de 30 segundos de latência para gerar uma única resposta”, disse Aditya Grover, professor assistente de ciência da computação na UCLA e coautor do artigo sobre d1, ao VentureBeat. “Em contraste, um dos principais benefícios dos dLLMs é sua eficiência computacional. Por exemplo, dLLMs de ponta como Mercury podem superar os melhores LLMs autoregressivos otimizados em termos de velocidade de laboratórios de fronteira em 10x em termos de throughput de usuários.”
Aprendizado por reforço para dLLMs
Apesar de suas vantagens, os dLLMs ainda ficam atrás dos modelos autoregressivos em habilidades de raciocínio. O aprendizado por reforço se tornou crucial para ensinar LLMs habilidades complexas de raciocínio. Ao treinar modelos com base em sinais de recompensa (basicamente, recompensando-os por passos de raciocínio corretos ou respostas finais), o RL tem direcionado os LLMs a um melhor seguimento de instruções e raciocínio.
Algoritmos como Proximal Policy Optimization (PPO) e o mais recente Group Relative Policy Optimization (GRPO) têm sido centrais para aplicar o RL efetivamente a modelos autoregressivos. Esses métodos normalmente se baseiam no cálculo da probabilidade (ou log-probabilidade) da sequência de texto gerada sob a política atual do modelo para guiar o processo de aprendizado.
Esse cálculo é simples para modelos autoregressivos devido à sua geração sequencial, token por token. No entanto, para os dLLMs, com seu processo de geração iterativo e não sequencial, calcular diretamente essa probabilidade de sequência é difícil e computacionalmente caro. Isso tem sido um grande obstáculo para aplicar técnicas de RL estabelecidas para melhorar o raciocínio dos dLLMs.
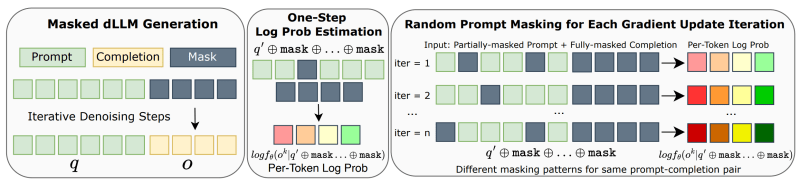
A estrutura d1 aborda esse desafio com um processo de pós-treinamento em duas etapas projetado especificamente para dLLMs mascarados:
- Aperfeiçoamento supervisionado (SFT): Primeiro, o dLLM pré-treinado é aprimorado em um conjunto de dados de exemplos de raciocínio de alta qualidade. O artigo usa o conjunto de dados “s1k”, que contém soluções detalhadas passo a passo para problemas, incluindo exemplos de autocorreção e retrocesso quando ocorrem erros. Esta etapa visa incutir padrões e comportamentos de raciocínio fundamentais no modelo.
- Aprendizado por reforço com diffu-GRPO: Após SFT, o modelo passa por um treinamento de RL usando um novo algoritmo chamado diffu-GRPO. Este algoritmo adapta os princípios do GRPO para dLLMs. Introduz um método eficiente para estimar log-probabilidades enquanto evita os cálculos onerosos anteriormente exigidos. Também incorpora uma técnica inteligente chamada “mascaramento aleatório de prompts.”
Durante o treinamento de RL, partes do prompt de entrada são mascaradas aleatoriamente em cada etapa de atualização. Isso age como uma forma de regularização e aumento de dados, permitindo que o modelo aprenda de maneira mais eficaz a partir de cada lote de dados.
d1 em aplicações do mundo real
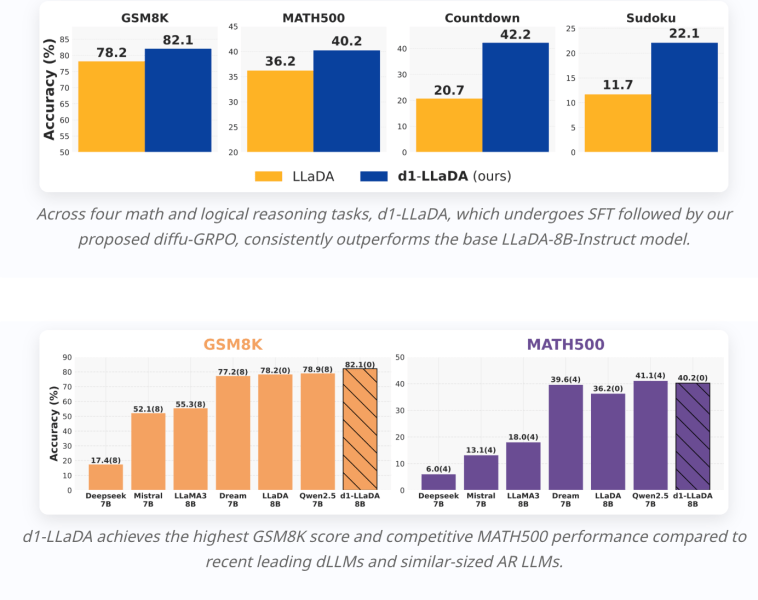
Os pesquisadores aplicaram a estrutura d1 ao LLaDA-8B-Instruct, um dLLM de código aberto. Eles o aprimoraram usando o conjunto de dados de raciocínio s1k para a etapa de SFT. Em seguida, compararam várias versões: o modelo base LLaDA, LLaDA com apenas SFT, LLaDA com apenas diffu-GRPO e o d1-LLaDA completo (SFT seguido de diffu-GRPO).
Esses modelos foram testados em benchmarks de raciocínio matemático (GSM8K, MATH500) e tarefas de raciocínio lógico (Sudoku 4×4, jogo de números Countdown).
Os resultados mostraram que o d1-LLaDA completo alcançou consistentemente o melhor desempenho em todas as tarefas. Impressionantemente, o diffu-GRPO aplicado isoladamente também superou significativamente o SFT sozinho e o modelo base.
“Modelos dLLM aprimorados em raciocínio como o d1 podem impulsionar diferentes tipos de agentes para cargas de trabalho empresariais,” disse Grover. “Isso inclui agentes de codificação para engenharia de software instantânea, bem como pesquisas profundas ultrarrápidas para estratégia em tempo real e consultoria… Com agentes d1, os fluxos de trabalho digitais diários podem se tornar automatizados e acelerados ao mesmo tempo.”
Curiosamente, os pesquisadores observaram melhorias qualitativas, especialmente ao gerar respostas mais longas. Os modelos começaram a exibir “momentos de clareza”, demonstrando comportamentos de autocorreção e retrocesso aprendidos a partir dos exemplos no conjunto de dados s1k. Isso sugere que o modelo não está apenas memorizando respostas, mas aprendendo estratégias de resolução de problemas mais robustas.
Modelos autoregressivos têm uma vantagem de primeiro movimento em termos de adoção. No entanto, Grover acredita que os avanços em dLLMs podem mudar a dinâmica do cenário. Para uma empresa, uma forma de decidir entre os dois é verificar se sua aplicação está atualmente travada por limitações de latência ou custo.
De acordo com Grover, dLLMs de difusão aprimorados em raciocínio, como o d1, podem ajudar de duas maneiras complementares:
- Se uma empresa não pode migrar atualmente para um modelo de raciocínio baseado em um LLM autoregressivo, dLLMs aprimorados em raciocínio oferecem uma alternativa plug-and-play que permite que empresas experimentem a qualidade superior de modelos de raciocínio na mesma velocidade que um dLLM autoregressivo não raciocinador.
- Se a aplicação empresarial permite um maior orçamento de latência e custo, o d1 pode gerar rastros de raciocínio mais longos utilizando o mesmo orçamento, melhorando ainda mais a qualidade.
“Em outras palavras, dLLMs ao estilo d1 podem dominar os LLMs autoregressivos nos eixos de qualidade, velocidade e custo,” disse Grover.


Conteúdo relacionado

Alibaba apresenta o Qwen3, uma família de modelos de raciocínio “híbridos” de IA.
[the_ad id="145565"] A empresa chinesa de tecnologia Alibaba anunciou na segunda-feira o lançamento do Qwen3, uma família de modelos de IA que a empresa afirma igualar e, em…
Escritor lança Palmyra X5, oferecendo desempenho próximo ao GPT-4.1 com 75% de custo reduzido.
[the_ad id="145565"] Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura líder da indústria em IA. Saiba mais…