


Uma nova colaboração entre a Universidade da Califórnia Merced e a Adobe apresenta um avanço no state-of-the-art em completação de imagens humanas – a tarefa amplamente estudada de ‘desobstruir’ partes ocultas ou escondidas de imagens de pessoas, com propósitos como experimentação virtual, animação e edição de fotos.

Além de reparar imagens danificadas ou alterá-las conforme o desejo do usuário, sistemas de completamento de imagem humana como o CompleteMe podem impor novas roupas (via uma imagem de referência adjunta, como na coluna do meio nestes dois exemplos) em imagens existentes. Esses exemplos são da extensa PDF suplementar para o novo artigo. Fonte: https://liagm.github.io/CompleteMe/pdf/supp.pdf
A nova abordagem, intitulado CompleteMe: Completação de Imagem Humana Baseada em Referência, utiliza imagens de entrada suplementares para ‘sugerir’ ao sistema qual conteúdo deve substituir a seção oculta ou ausente da representação humana (daí a aplicabilidade em estruturas de experimentação de moda):

O sistema CompleteMe pode conformar o conteúdo de referência à parte obscured ou oculta de uma imagem humana.
O novo sistema utiliza uma arquitetura U-Net dual e um bloco Atenção Focada em Região (RFA) que direciona recursos à área pertinente da instância de restauração da imagem.
Os pesquisadores também oferecem um novo e desafiador sistema de benchmark projetado para avaliar tarefas de completamento baseadas em referência (já que o CompleteMe faz parte de uma linha de pesquisa existente e em andamento em visão computacional, embora não tenha tido nenhum esquema de benchmark até agora).
Em testes, e em um estudo de usuário bem escalonado, o novo método superou a maioria das métricas e teve um desempenho geral superior. Em certos casos, métodos rivais foram completamente confundidos pela abordagem baseada em referência:

Do material suplementar: o método AnyDoor tem dificuldade particular em decidir como interpretar uma imagem de referência.
O artigo afirma:
‘Experimentos extensivos em nosso benchmark demonstram que o CompleteMe supera métodos state-of-the-art, tanto baseados em referência quanto não baseados em referência, em termos de métricas quantitativas, resultados qualitativos e estudos de usuário.’
‘Particularmente em cenários desafiadores envolvendo poses complexas, padrões intrincados de roupas e acessórios distintos, nosso modelo atinge consistentemente uma fidelidade visual superior e coerência semântica.’
Infelizmente, a presença do projeto no GitHub não contém código, nem promete algum, e a iniciativa, que também possui uma modesta página do projeto, parece estar enquadrada como uma arquitetura proprietária.

Outro exemplo do desempenho subjetivo do novo sistema em comparação com métodos anteriores. Mais detalhes adiante no artigo.
Método
O framework CompleteMe é fundamentado por um U-Net de Referência, que lida com a integração do material auxiliar no processo, e um U-Net coeso, que acomoda uma gama mais ampla de processos para obter o resultado final, como ilustrado no esquema conceitual abaixo:
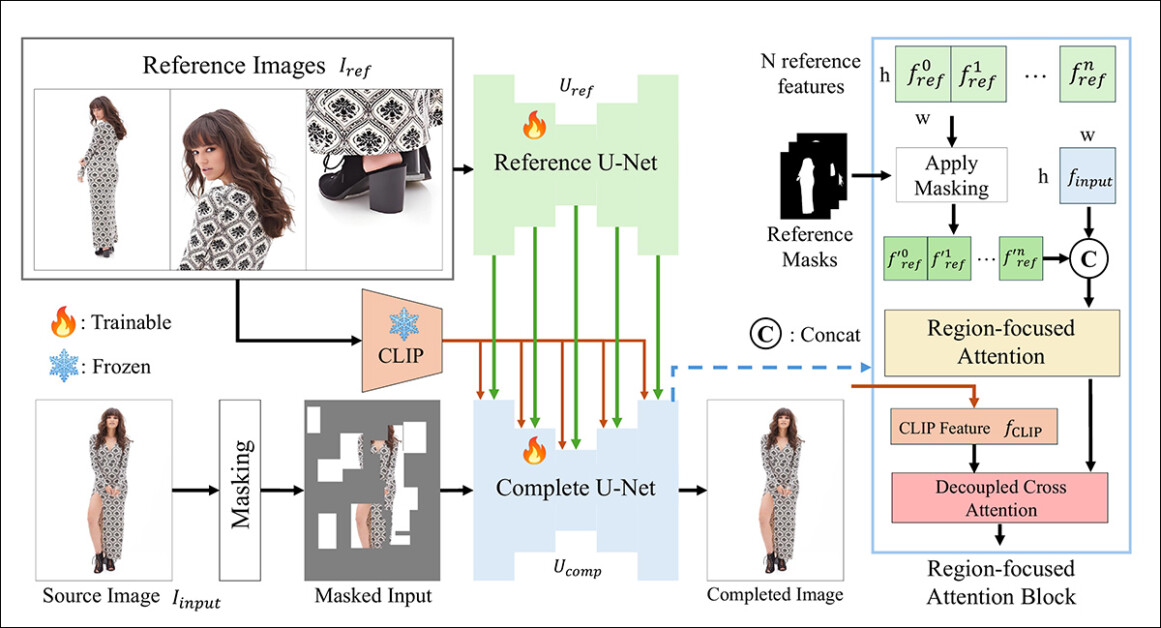
O esquema conceitual para o CompleteMe. Fonte: https://arxiv.org/pdf/2504.20042
O sistema primeiro codifica a imagem de entrada mascarada em uma representação latente. Ao mesmo tempo, o U-Net de Referência processa múltiplas imagens de referência – cada uma mostrando diferentes regiões do corpo – para extrair detalhes espaciais características.
Essas características passam por um bloco de Atenção Focada em Região incorporado no U-Net ‘completo’, onde são mascaradas seletivamente usando as máscaras de região correspondentes, garantindo que o modelo atenda apenas às áreas relevantes nas imagens de referência.
As características mascaradas são então integradas com características semânticas globais derivadas do CLIP por meio de uma atenção cruzada desacoplada, permitindo que o modelo reconstrua o conteúdo ausente com tanto detalhe fino quanto coerência semântica.
Para melhorar o realismo e a robustez, o processo de mascaramento de entrada combina oclusões aleatórias baseadas em grade com máscaras de forma do corpo humano, cada uma aplicada com igual probabilidade, aumentando a complexidade das regiões ausentes que o modelo deve completar.
Para Referência Apenas
Métodos anteriores para inpainting de imagem baseado em referência geralmente dependiam de encoders de nível semântico. Projetos desse tipo incluem o próprio CLIP e DINOv2, que extraem características globais de imagens de referência, mas muitas vezes perdem os detalhes espaciais finos necessários para a preservação precisa da identidade.

Do artigo de lançamento para a abordagem mais antiga DINOV2, que está incluída em testes de comparação no novo estudo: Os sobreposições coloridas mostram os três primeiros componentes principais da Análise de Componentes Principais (PCA), aplicada a patches de imagem dentro de cada coluna, destacando como o DINOv2 agrupa partes de objetos semelhantes em imagens variadas. Apesar das diferenças em pose, estilo ou renderização, as regiões correspondentes (como asas, membros ou rodas) são consistentemente combinadas, ilustrando a capacidade do modelo de aprender a estrutura baseada em partes sem supervisão. Fonte: https://arxiv.org/pdf/2304.07193
O CompleteMe aborda esse aspecto através de um U-Net de Referência especializado, inicializado a partir do Stable Diffusion 1.5, operando sem o passo de ruído de difusão.
Cada imagem de referência, cobrindo diferentes regiões do corpo, é codificada em características latentes detalhadas através deste U-Net. As características semânticas globais também são extraídas separadamente usando o CLIP, e ambos os conjuntos de características são armazenados para uso eficiente durante a integração baseada em atenção. Assim, o sistema pode acomodar múltiplas entradas de referência de forma flexível, enquanto preserva informações de aparência de alta resolução.
Orquestração
O U-Net coeso gerencia as etapas finais do processo de completamento. Adaptado da variável de inpainting do Stable Diffusion 1.5, ele recebe como entrada a imagem de origem mascarada em forma latente, juntamente com características espaciais detalhadas extraídas das imagens de referência e características semânticas globais extraídas pelo codificador CLIP.
Essas várias entradas são reunidas através do bloco RFA, que desempenha um papel crítico em direcionar o foco do modelo para as áreas mais relevantes do material de referência.
Antes de entrar no mecanismo de atenção, as características de referência são explicitamente mascaradas para remover regiões não relacionadas e, em seguida, concatenadas com a representação latente da imagem de origem, garantindo que a atenção seja direcionada de forma mais precisa possível.
Para melhorar essa integração, o CompleteMe incorpora um mecanismo de atenção cruzada desacoplada adaptado do IP-Adapter:

IP-Adapter, parte do qual é incorporado ao CompleteMe, é um dos projetos mais bem-sucedidos e frequentemente aproveitados dos últimos três anos agitados de desenvolvimento em arquiteturas de modelos de difusão latente. Fonte: https://ip-adapter.github.io/
Isso permite que o modelo processe características visuais detalhadas espacialmente e um contexto semântico mais amplo por meio de fluxos de atenção separados, que são posteriormente combinados, resultando em uma reconstrução coerente que, segundo os autores, preserva tanto a identidade quanto os detalhes finos.
Benchmarking
Na ausência de um conjunto de dados apropriado para completamento humano baseado em referência, os pesquisadores propuseram o seu próprio. O benchmark (sem nome) foi construído curando pares de imagens selecionadas do conjunto de dados WPose, concebido para o projeto UniHuman da Adobe Research de 2023.

Exemplos de poses do projeto UniHuman de 2023 da Adobe Research. Fonte: https://github.com/adobe-research/UniHuman?tab=readme-ov-file#data-prep
Os pesquisadores desenharam manualmente máscaras de origem para indicar as áreas de inpainting, obtendo, ao todo, 417 grupos de imagens tripartites constituindo uma imagem de origem, máscara e imagem de referência.

Dois exemplos de grupos derivados inicialmente do conjunto de dados de referência WPose, e criteriosamente curados pelos pesquisadores do novo artigo.
Os autores utilizaram o modelo de linguagem grande (LLM) LLaVA para gerar prompts de texto descrevendo as imagens de origem.
Métricas usadas foram mais extensas do que o habitual; além do habitual Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM) e Learned Perceptual Image Patch Similarity (LPIPS, neste caso para avaliar regiões mascaradas), os pesquisadores usaram DINO para pontuações de similaridade; DreamSim para avaliação do resultado da geração; e CLIP.
Dados e Testes
Para testar o trabalho, os autores utilizaram tanto o modelo padrão Stable Diffusion V1.5 quanto o modelo de inpainting 1.5. O codificador de imagem do sistema usou o modelo Vision do CLIP junto com camadas de projeção – redes neurais modestas que remodelam ou alinham as saídas do CLIP para corresponder às dimensões de características internas usadas pelo modelo.
O treinamento ocorreu por 30.000 iterações em oito GPUs NVIDIA A100†, supervisionado por Mean Squared Error (MSE) loss, com um tamanho de lote de 64 e uma taxa de aprendizado de 2×10-5. Vários elementos foram descartados aleatoriamente ao longo do treinamento, para evitar que o sistema overfittasse nos dados.
O conjunto de dados foi modificado a partir do conjunto de dados Parts to Whole, que por sua vez se baseia no conjunto DeepFashion-MultiModal.

Exemplos do conjunto de dados Parts to Whole, usados no desenvolvimento dos dados curados para o CompleteMe. Fonte: https://huanngzh.github.io/Parts2Whole/
Os autores afirmam:
‘Para atender aos nossos requisitos, nós [reconstruímos] os pares de treinamento usando imagens ocluídas com múltiplas imagens de referência que capturam vários aspectos da aparência humana junto com seus rótulos textuais curtos.’
‘Cada amostra em nossos dados de treinamento inclui seis tipos de aparência: roupas da parte superior, roupas da parte inferior, roupas de corpo inteiro, cabelo ou chapéus, rosto e sapatos. Para a estratégia de mascaramento, aplicamos uma máscara de grade aleatória de 50% entre 1 a 30 vezes, enquanto para os outros 50%, usamos uma máscara de forma do corpo humano para aumentar a complexidade do mascaramento.’
‘Após o pipeline de construção, obtivemos 40.000 pares de imagens para treinamento.’
Métodos rivais não baseados em referência testados foram Completação de Imagem Humana com Grandes Oclusões (LOHC) e o modelo de inpainting de plug-and-play BrushNet; modelos baseados em referência testados foram Paint-by-Example; AnyDoor; LeftRefill; e MimicBrush.
Os autores iniciaram uma comparação quantitativa nas métricas mencionadas anteriormente:
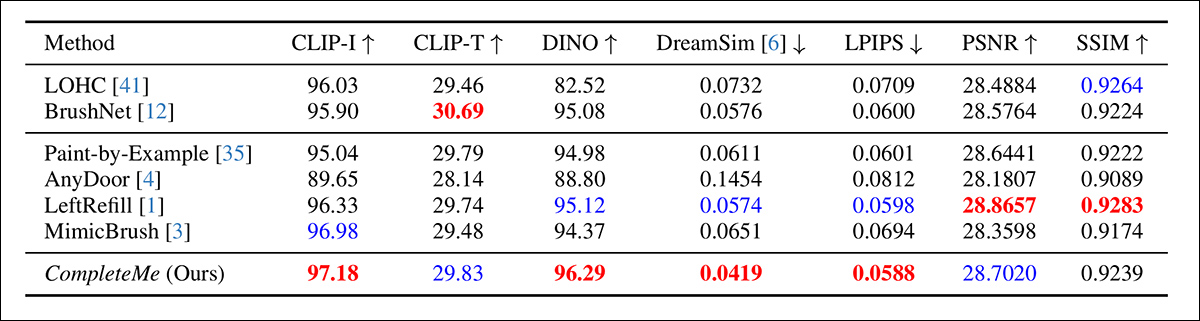
Resultados para a comparação quantitativa inicial.
Em relação à avaliação quantitativa, os autores observam que o CompleteMe alcança as melhores pontuações na maioria das métricas perceptuais, incluindo CLIP-I, DINO, DreamSim e LPIPS, que visam capturar o alinhamento semântico e a fidelidade de aparência entre a saída e a imagem de referência.
No entanto, o modelo não supera todas as linhas de base em todos os aspectos. Notavelmente, o BrushNet pontua mais alto no CLIP-T, o LeftRefill lidera em SSIM e PSNR, e o MimicBrush ligeiramente supera no CLIP-I.
Embora o CompleteMe mostre resultados consistentemente fortes em geral, as diferenças de desempenho são modestas em alguns casos, e certas métricas continuam a ser lideradas por métodos anteriores concorrentes. Talvez não de forma injusta, os autores enquadram esses resultados como evidência da força equilibrada do CompleteMe em ambas as dimensões estruturais e perceptuais.
As ilustrações para os testes qualitativos realizados para o estudo são numerosas demais para serem reproduzidas aqui, e recomendamos ao leitor não apenas o artigo fonte, mas também o extenso PDF suplementar, que contém muitos exemplos qualitativos adicionais.
Destacamos os principais exemplos qualitativos apresentados no artigo principal, juntamente com uma seleção de casos adicionais retirados do conjunto de imagens suplementares introduzido anteriormente neste artigo:
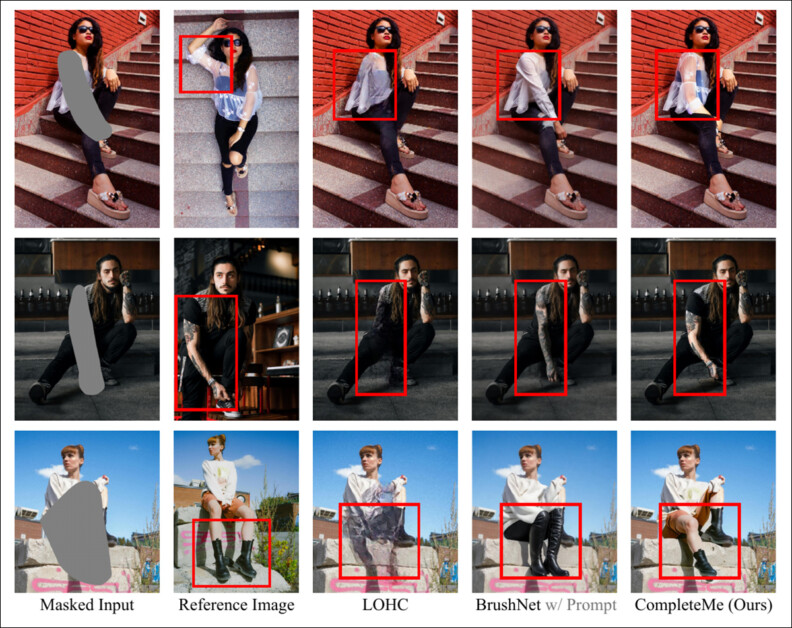
Resultados qualitativos iniciais apresentados no artigo principal. Consulte o artigo fonte para melhor resolução.
Dos resultados qualitativos exibidos acima, os autores comentam:
‘Dadas entradas mascaradas, esses métodos não baseados em referência geram conteúdo plausível para as regiões mascaradas usando priors de imagem ou prompts de texto.’
‘No entanto, como indicado na caixa vermelha, eles não conseguem reproduzir detalhes específicos, como tatuagens ou padrões de roupas únicos, uma vez que carecem de imagens de referência para guiar a reconstrução de informações idênticas.’
Uma segunda comparação, parte da qual é mostrada abaixo, foca nos quatro métodos baseados em referência Paint-by-Example, AnyDoor, LeftRefill e MimicBrush. Aqui, apenas uma imagem de referência e um prompt de texto foram fornecidos.
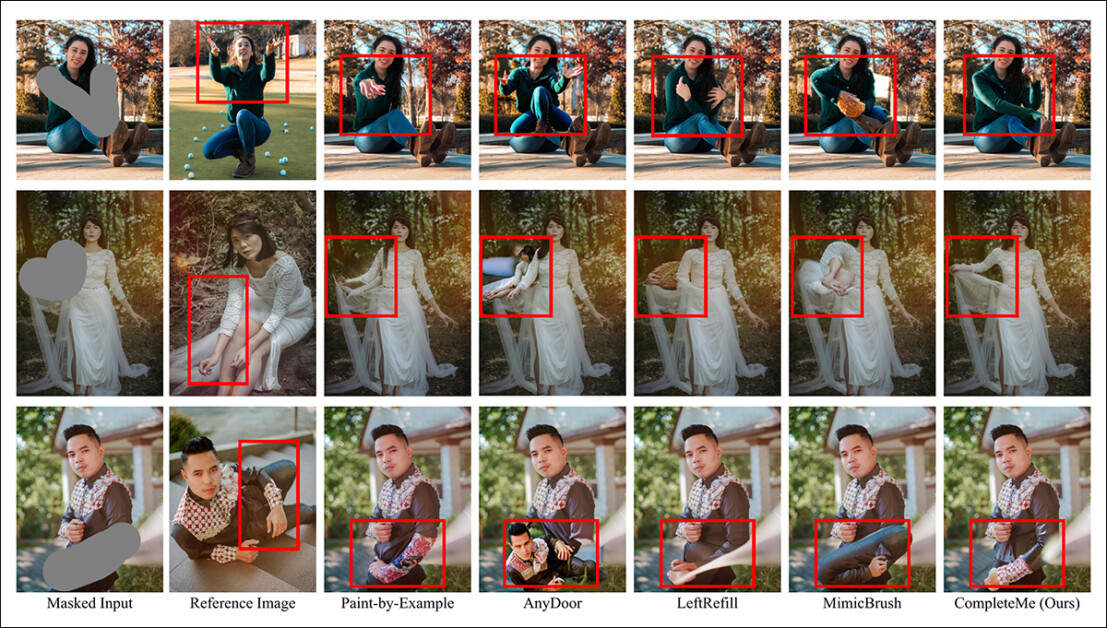
Comparação qualitativa com métodos baseados em referência. O CompleteMe produz preenchimentos mais realistas e preserva melhor detalhes específicos da imagem de referência. As caixas vermelhas destacam áreas de particular interesse.
Os autores afirmam:
‘Dada uma imagem humana mascarada e uma imagem de referência, outros métodos podem gerar conteúdo plausível, mas frequentemente não conseguem preservar com precisão a informação contextual da referência.’
‘Em alguns casos, eles geram conteúdo irrelevante ou mapeiam incorretamente partes correspondentes da imagem de referência. Em contraste, o CompleteMe completa efetivamente a região mascarada, preservando com precisão informações idênticas e mapeando corretamente partes correspondentes do corpo humano da imagem de referência.’
Para avaliar quão bem os modelos se alinham com a percepção humana, os autores realizaram um estudo de usuário envolvendo 15 anotadores e 2.895 pares de amostras. Cada par comparava a saída do CompleteMe contra uma das quatro linhas de base baseadas em referência: Paint-by-Example, AnyDoor, LeftRefill ou MimicBrush.
Os anotadores avaliaram cada resultado com base na qualidade visual da região completada e na medida em que preservou características de identidade da referência – e aqui, ao avaliar a qualidade geral e a identidade, o CompleteMe obteve um resultado mais definitivo:
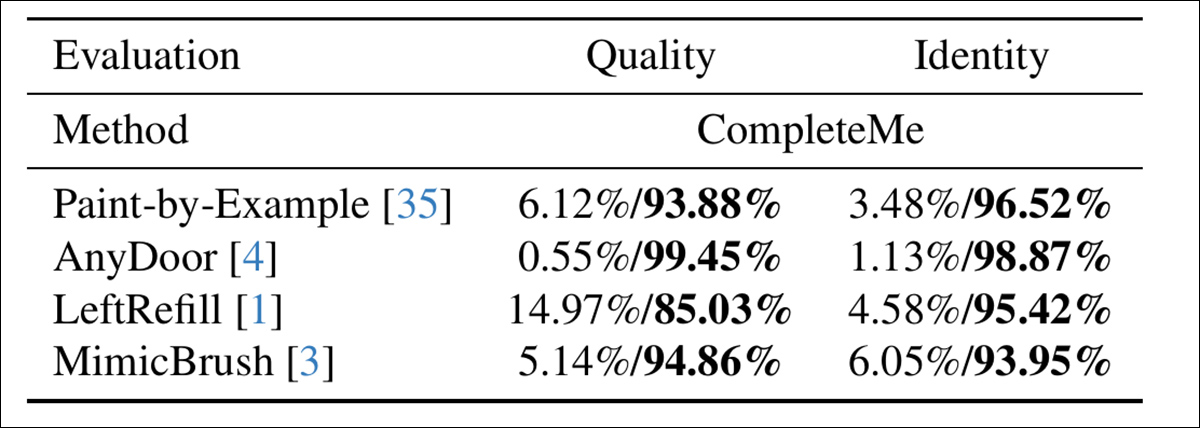
Resultados do estudo de usuário.
Conclusão
Seja como for, os resultados qualitativos neste estudo são prejudicados pelo seu volume, já que uma análise mais próxima indica que o novo sistema é uma entrada muito eficaz nesta área relativamente nichada, mas bastante perseguida, de edição de imagem neural.
No entanto, é necessário um cuidado adicional e um zoom no PDF original para apreciar como bem o sistema adapta o material de referência à área ocluída em comparação (na quase totalidade dos casos) com métodos anteriores.

Recomendamos fortemente ao leitor examinar cuidadosamente a avalanche inicialmente confusa, se não opressora, de resultados apresentados no material suplementar.
* É interessante notar como a agora severamente ultrapassada versão V1.5 continua sendo a favorita dos pesquisadores – em parte devido a testes relacionados, mas também porque é a menos censurada e, possivelmente, a mais facilmente treinável de todas as iterações do Stable Diffusion, e não compartilha da censura inibidora das versões FOSS Flux.
† Especificação VRAM não dada – poderia ser de 40GB ou 80GB por placa.
Publicado pela primeira vez na terça-feira, 29 de abril de 2025.

Conteúdo relacionado

Google lança ferramentas de IA para praticar idiomas por meio de lições personalizadas
[the_ad id="145565"] Na terça-feira, o Google anunciou o lançamento de três novas experiências com IA, destinadas a ajudar as pessoas a aprender a falar um novo idioma de forma…

Google’s NotebookLM Expands AI Podcast Feature to Additional Languages in Portuguese
[the_ad id="145565"] O assistente de anotações e pesquisa baseado em IA do Google, NotebookLM, está disponibilizando sua funcionalidade de Visões Gerais em Áudio em 76 novos…

Ex-CEO da OpenAI e usuários poderosos soam o alarme sobre a bajulação e a adulação a usuários da IA
[the_ad id="145565"] Here's the rewritten content in Portuguese, maintaining the HTML structure: <div> <div id="boilerplate_2682874" class="post-boilerplate…