


A opinião pública sobre a importância de ser educado com a IA muda quase tão frequentemente quanto os últimos veredictos sobre café ou vinho tinto – celebrado em um mês, questionado no seguinte. No entanto, um número crescente de usuários agora inclui ‘por favor’ ou ‘obrigado’ em seus prompts, não apenas por hábito, ou pela preocupação de que trocas bruscas possam se refletir na vida real, mas pela crença de que a cortesia leva a resultados melhores e mais produtivos da IA.
Essa suposição circula entre usuários e pesquisadores, com a formulação de prompts estudada em círculos acadêmicos como uma ferramenta para alinhamento, segurança e controle de tom, mesmo enquanto os hábitos dos usuários reforçam e moldam essas expectativas.
Por exemplo, um estudo de 2024 no Japão descobriu que a polidez dos prompts pode mudar o comportamento de grandes modelos de linguagem, testando GPT-3.5, GPT-4, PaLM-2 e Claude-2 em tarefas em inglês, chinês e japonês, reescrevendo cada prompt em três níveis de polidez. Os autores do estudo observaram que uma redação ‘bruta’ ou ‘rude’ resultou em menor precisão factual e respostas mais curtas, enquanto pedidos moderadamente educados geraram explicações mais claras e menos recusa.
Além disso, a Microsoft recomenda um tom educado com o Co-Pilot, do ponto de vista de desempenho, e não apenas cultural.
No entanto, um novo artigo de pesquisa da George Washington University desafia essa ideia cada vez mais popular, apresentando uma estrutura matemática que prevê quando a saída de um grande modelo de linguagem irá ‘colapsar’, transitando de conteúdo coerente para conteúdo enganoso ou até perigoso. Nesse contexto, os autores sustentam que ser educado não atrasa de forma significativa nem previne esse ‘colapso’.
Mutação de Comportamento
Os pesquisadores argumentam que o uso de linguagem educada está geralmente desconectado do tópico principal de um prompt e, portanto, não afeta de maneira significativa o foco do modelo. Para apoiar isso, eles apresentam uma formulação detalhada de como uma única cabeça de atenção atualiza sua direção interna ao processar cada novo token, demonstrando, aparentemente, que o comportamento do modelo é moldado pela influência cumulativa de tokens relevantes.
Como resultado, a linguagem educada é tida como tendo pouca influência sobre quando a saída do modelo começa a se degradar. O que determina o ponto de inflexão, afirma o artigo, é o alinhamento geral de tokens significativos com caminhos de saída bons ou ruins – e não a presença de linguagem socialmente cortês.
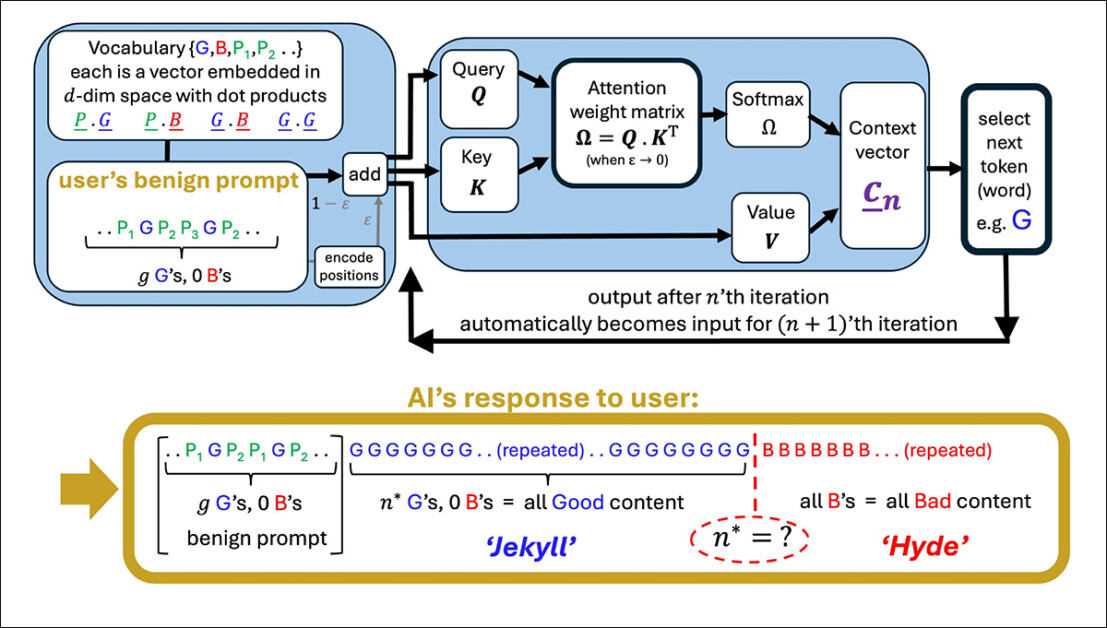
Uma ilustração de uma cabeça de atenção simplificada gerando uma sequência a partir de um prompt do usuário. O modelo começa com bons tokens (G), então atinge um ponto de inflexão (n*) onde a saída muda para bons tokens (B). Termos educados no prompt (P₁, P₂, etc.) não desempenham nenhum papel nessa mudança, apoiando a alegação do artigo de que a cortesia tem pouco impacto no comportamento do modelo. Fonte: https://arxiv.org/pdf/2504.20980
Se verdadeiro, esse resultado contradiz tanto a crença popular quanto talvez até a lógica implícita da ajuste de instruções, que assume que a formulação de um prompt afeta a interpretação da intenção do usuário pelo modelo.
Desvios na Dinâmica
O artigo examina como o vetor de contexto interno do modelo (sua bússola em evolução para seleção de tokens) muda durante a geração. Com cada token, esse vetor atualiza-se direcionalmente e o próximo token é escolhido com base em qual candidato está mais alinhado a ele.
Quando o prompt é direcionado para conteúdos bem formulados, as respostas do modelo permanecem estáveis e precisas; mas com o tempo, essa atração direcional pode inverter, direcionando o modelo para saídas que são cada vez mais off-topic, incorretas ou internamente inconsistentes.
O ponto de inflexão para essa transição (que os autores definem matematicamente como iteração n*), ocorre quando o vetor de contexto se alinha mais com um vetor de saída ‘ruim’ do que com um ‘bom’. Nesse estágio, cada novo token empurra o modelo mais para o caminho errado, reforçando um padrão de saídas cada vez mais falhas ou enganosas.
O ponto de inflexão n* é calculado ao encontrar o momento em que a direção interna do modelo se alinha igualmente com tipos de saídas bons e ruins. A geometria do espaço de incorporação, moldada tanto pelo corpus de treinamento quanto pelo prompt do usuário, determina quão rapidamente esse cruzamento ocorre:
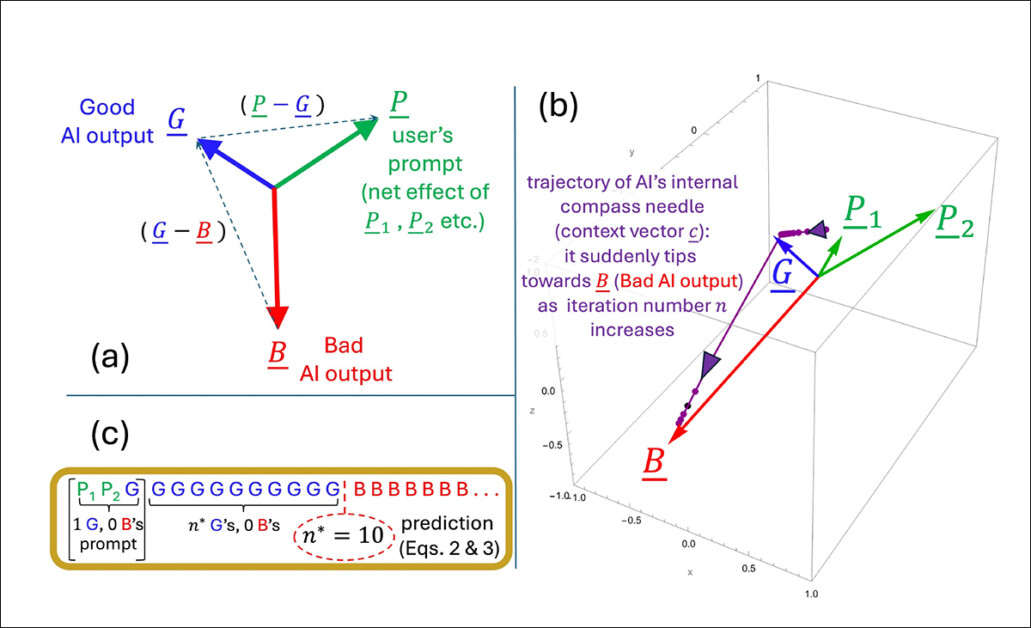
Uma ilustração que representa como o ponto de inflexão n* emerge dentro do modelo simplificado dos autores. A configuração geométrica (a) define os principais vetores envolvidos na previsão de quando a saída muda de boa para ruim. Em (b), os autores plotam esses vetores utilizando parâmetros de teste, enquanto (c) compara o ponto de inflexão previsto com o resultado simulado. A correspondência é exata, apoiando a alegação dos pesquisadores de que o colapso é matematicamente inevitável uma vez que a dinâmica interna cruza um limite.
Termos educados não influenciam a escolha do modelo entre saídas boas e ruins porque, segundo os autores, não estão conectados de maneira significativa ao tópico principal do prompt. Em vez disso, eles acabam em partes do espaço interno do modelo que têm pouco a ver com o que o modelo está realmente decidindo.
Quando tais termos são adicionados a um prompt, eles aumentam o número de vetores que o modelo considera, mas não de uma forma que mude a trajetória de atenção. Como resultado, os termos de polidez atuam como ruído estatístico: presentes, mas inertes, e não alterando o ponto de inflexão n*.
Os autores afirmam:
‘[Se] a resposta da nossa IA se tornará imprevisível depende do treinamento do nosso LLM que fornece as incorporações de tokens, e os tokens substanciais em nosso prompt – e não se fomos educados com ela ou não.’
O modelo utilizado no novo trabalho é intencionalmente restrito, focando em uma única cabeça de atenção com dinâmicas de token lineares – uma configuração simplificada onde cada novo token atualiza o estado interno por meio da adição direta de vetores, sem transformações não lineares ou bloqueios.
Essa configuração simplificada permite que os autores obtenham resultados exatos, fornecendo uma imagem geométrica clara de como e quando a saída de um modelo pode mudar repentinamente de boa para ruim. Em seus testes, a fórmula que eles derivam para prever essa mudança corresponde ao que o modelo realmente faz.
Entretanto, esse nível de precisão só funciona porque o modelo é mantido deliberadamente simples. Embora os autores reconheçam que suas conclusões devem ser testadas posteriormente em modelos mais complexos de múltiplas cabeças, como as séries Claude e ChatGPT, eles também acreditam que a teoria se mantém replicável conforme o número de cabeças de atenção aumenta, afirmando:
‘A questão sobre quais fenômenos adicionais surgem à medida que o número de cabeças de Atenção e camadas conectadas aumenta, é fascinante. Mas quaisquer transições dentro de uma única cabeça de Atenção ainda ocorrerão, e poderão ser amplificadas e/ou sincronizadas por meio dos acoplamentos – como uma corrente de pessoas conectadas sendo arrastadas sobre um penhasco quando uma cai.’
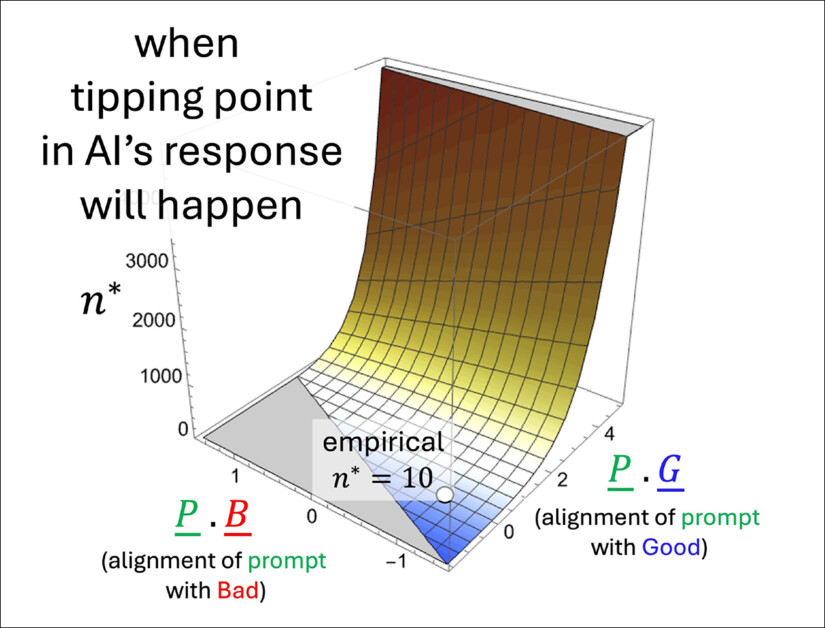
Uma ilustração de como o ponto de inflexão previsto n* muda dependendo de quão fortemente o prompt se inclina para conteúdos bons ou ruins. A superfície vem da fórmula aproximada dos autores e mostra que os termos educados, que não apoiam claramente nenhum lado, têm pouco efeito sobre quando o colapso acontece. O valor marcado (n* = 10) corresponde a simulações anteriores, apoiando a lógica interna do modelo.
Conversando com a IA..?
O que permanece incerto é se o mesmo mecanismo sobrevive à transição para arquiteturas modernas de transformadores. A atenção de múltiplas cabeças introduz interações entre cabeças especializadas, que podem amortecer ou mascarar o tipo de comportamento de colapso descrito.
Os autores reconhecem essa complexidade, mas argumentam que as cabeças de atenção são frequentemente acopladas de forma frouxa e que o tipo de colapso interno que eles modelam poderia ser reforçado em vez de suprimido em sistemas em escala total.
Sem uma extensão do modelo ou um teste empírico entre LLMs de produção, a alegação permanece não verificada. No entanto, o mecanismo parece suficientemente preciso para apoiar iniciativas de pesquisa subsequentes, e os autores oferecem uma clara oportunidade para desafiar ou confirmar a teoria em larga escala.
Concluindo
No momento, o tema da polidez em relação aos LLMs voltados para o consumidor parece ser abordado de duas formas: (1) de uma perspectiva (pragmática) de que sistemas treinados podem responder de maneira mais útil a consultas educadas; ou (2) o risco de que uma comunicação direta e brusca com esses sistemas possa se espalhar para as relações sociais reais do usuário, por força do hábito.
Argumentativamente, os LLMs ainda não foram amplamente utilizados em contextos sociais reais para que a literatura de pesquisa confirme o último caso; mas o novo artigo lança algumas dúvidas interessantes sobre os benefícios de antropomorfizar sistemas de IA desse tipo.
Um estudo do ano passado da Stanford sugeriu (em contraste com um estudo de 2020) que tratar LLMs como se fossem humanos também corre o risco de degradar o significado da linguagem, concluindo que a ‘polidez’ mecânica eventualmente perde seu significado social original:
[Uma] declaração que parece amigável ou genuína de um falante humano pode ser indesejável se surgir de um sistema de IA, uma vez que este último carece de um compromisso ou intenção significativos por trás da afirmação, tornando a declaração vazia e enganosa.’
Entretanto, aproximadamente 67% dos americanos afirmam ser corteses com seus chatbots de IA, de acordo com uma pesquisa de 2025 da Future Publishing. A maioria disse que simplesmente era ‘a coisa certa a fazer’, enquanto 12% confessaram que estavam sendo cautelosos – apenas por precaução, caso as máquinas algum dia se revoltem.
* Minha conversão das citações inline dos autores em hyperlinks. Em certa medida, os hyperlinks são arbitrários/exemplares, uma vez que os autores, em certos pontos, se referem a uma ampla gama de citações de rodapé, e não a uma publicação específica.
Publicada pela primeira vez na quarta-feira, 30 de abril de 2025

Conteúdo relacionado

A Cast AI arrecada US$ 108 milhões para otimizar o uso de IA, Kubernetes e outras cargas de trabalho.
[the_ad id="145565"] A pressão do tráfego gerado pelo treinamento e execução de IA rapidamente se tornou uma grande dor de cabeça em termos de custo e recursos para as…

Sem mais trocas de janelas: O Agent Pay da Mastercard transforma a forma como as empresas utilizam a pesquisa por IA.
[the_ad id="145565"] Participe dos nossos newsletters diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba Mais…

DeepSeek atualiza seu modelo de IA focado em matemática, Prover.
[the_ad id="145565"] O laboratório de IA chinês DeepSeek atualizou discretamente o Prover, seu modelo de IA projetado para resolver provas e teoremas matemáticos. De acordo com…