


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura líder de indústria em IA. Saiba mais
Meta anunciou hoje uma parceria com Cerebras Systems para impulsionar sua nova Llama API, oferecendo aos desenvolvedores acesso a velocidades de inferência até 18 vezes mais rápidas que as soluções tradicionais baseadas em GPU.
A anúncio, feito na conferência de desenvolvedores inaugural da Meta, LlamaCon, em Menlo Park, posiciona a empresa para competir diretamente com OpenAI, Anthropic e Google no crescente mercado de serviços de inferência em IA, onde os desenvolvedores compram tokens por bilhões para impulsionar suas aplicações.
“A Meta escolheu a Cerebras para colaborar e entregar a inferência ultra-rápida que eles precisam para atender os desenvolvedores por meio de sua nova Llama API,” disse Julie Shin Choi, diretora de marketing da Cerebras, durante uma coletiva de imprensa. “Nós, da Cerebras, estamos realmente muito empolgados em anunciar nossa primeira parceria de CSP hyperscaler para fornecer inferência ultra-rápida a todos os desenvolvedores.”
A parceria marca a entrada formal da Meta no negócio de venda de computação em IA, transformando seus populares modelos Llama em um serviço comercial. Embora os modelos Llama da Meta tenham acumulado mais de um bilhão de downloads, até agora a empresa não havia oferecido uma infraestrutura de nuvem de primeira parte para que os desenvolvedores construíssem aplicações com eles.
“Isso é muito empolgante, mesmo sem falar sobre a Cerebras especificamente,” disse James Wang, um executivo sênior da Cerebras. “OpenAI, Anthropic, Google — eles construíram um novo negócio de IA do zero, que é o negócio de inferência em IA. Desenvolvedores que estão criando aplicativos de IA irão comprar tokens por milhões, às vezes bilhões. E esses são como as novas instruções de computação que as pessoas precisam para construir aplicações de IA.”
Quebrando a barreira da velocidade: Como a Cerebras potencializa os modelos Llama
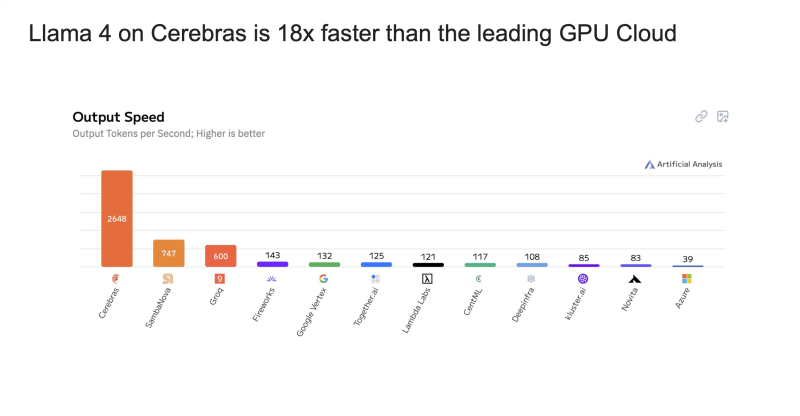
O que diferencia a oferta da Meta é o aumento dramático de velocidade proporcionado pelos chips de IA especializados da Cerebras. O sistema Cerebras entrega mais de 2.600 tokens por segundo para o Llama 4 Scout, em comparação com aproximadamente 130 tokens por segundo para o ChatGPT e cerca de 25 tokens por segundo para DeepSeek, de acordo com benchmarks da Artificial Analysis.
“Se você comparar apenas na base de API para API, Gemini e GPT, todos são ótimos modelos, mas todos rodam em velocidades de GPU, que é de aproximadamente 100 tokens por segundo,” explicou Wang. “E 100 tokens por segundo é aceitável para bate-papo, mas é muito lento para raciocínio. É muito lento para agentes. E as pessoas estão lutando com isso hoje.”
Essa vantagem de velocidade permite novas categorias de aplicações que eram anteriormente impraticáveis, incluindo agentes em tempo real, sistemas de voz de baixa latência conversacional, geração de código interativa e raciocínio instantâneo em múltiplas etapas — todos os quais requerem encadeamento de múltiplas chamadas de modelos de linguagem grande que agora podem ser completadas em segundos ao invés de minutos.
A Llama API representa uma mudança significativa na estratégia de IA da Meta, transitando de ser principalmente um fornecedor de modelos para se tornar uma empresa de infraestrutura de IA de serviço completo. Ao oferecer um serviço de API, a Meta está criando uma fonte de receita de seus investimentos em IA, enquanto mantém seu compromisso com modelos abertos.
“A Meta agora está no negócio de venda de tokens, e é ótimo para o ecossistema de IA americano,” observou Wang durante a coletiva de imprensa. “Eles trazem muito à mesa.”
A API oferecerá ferramentas para ajuste fino e avaliação, começando com o modelo Llama 3.3 8B, permitindo que desenvolvedores gerem dados, treinem sobre eles e testem a qualidade de seus modelos personalizados. A Meta enfatiza que não usará dados dos clientes para treinar seus próprios modelos, e modelos construídos usando a Llama API podem ser transferidos para outros hosts — uma clara diferenciação em relação a abordagens mais fechadas de alguns concorrentes.
A Cerebras alimentará o novo serviço da Meta por meio de sua rede de centros de dados localizados em toda a América do Norte, incluindo instalações em Dallas, Oklahoma, Minnesota, Montreal e Califórnia.
“Todos os nossos centros de dados que servem inferência estão na América do Norte neste momento,” explicou Choi. “Estaremos servindo a Meta com toda a capacidade da Cerebras. A carga de trabalho será balanceada entre todos esses diferentes centros de dados.”
O arranjo comercial segue o que Choi descreveu como o modelo “clássico de provedor de computação para um hyperscaler,” semelhante a como a Nvidia fornece hardware aos principais provedores de nuvem. “Eles estão reservando blocos de nossa computação que podem servir a sua população de desenvolvedores,” disse ela.
Além da Cerebras, a Meta também anunciou uma parceria com a Groq para fornecer opções de inferência rápidas, dando aos desenvolvedores múltiplas alternativas de alto desempenho além da inferência baseada em GPU tradicional.
A entrada da Meta no mercado de APIs de inferência com métricas de desempenho superiores pode potencialmente desestabilizar a ordem estabelecida dominada por OpenAI, Google e Anthropic. Ao combinar a popularidade de seus modelos de código aberto com capacidades de inferência dramaticamente mais rápidas, a Meta está se posicionando como um competidor formidável no espaço comercial de IA.
“A Meta está em uma posição única com 3 bilhões de usuários, datacenters de hiperescala e um enorme ecossistema de desenvolvedores,” de acordo com os materiais de apresentação da Cerebras. A integração da tecnologia da Cerebras “ajuda a Meta a superar a OpenAI e o Google em desempenho em aproximadamente 20x.”
Para a Cerebras, essa parceria representa um importante marco e validação de sua abordagem de hardware especializado em IA. “Estivemos construindo esse motor em escala de wafer por anos, e sempre soubemos que a tecnologia é de primeira linha, mas, em última instância, ela precisa fazer parte da nuvem hyperscale de outra pessoa. Esse foi o alvo final de uma perspectiva de estratégia comercial, e finalmente alcançamos esse marco,” disse Wang.
A Llama API está atualmente disponível como uma prévia limitada, com a Meta planejando um lançamento mais amplo nas próximas semanas e meses. Desenvolvedores interessados em acessar a inferência ultra-rápida do Llama 4 podem solicitar acesso antecipado selecionando a Cerebras nas opções de modelo dentro da Llama API.
“Se você imaginar um desenvolvedor que não sabe nada sobre a Cerebras porque somos uma empresa relativamente pequena, ele pode clicar em dois botões no SDK padrão de software da Meta, gerar uma chave de API, selecionar a opção da Cerebras, e então, de repente, seus tokens estão sendo processados em um gigantesco motor em escala de wafer,” explicou Wang. “Esse tipo de ter-nos no backend de todo o ecossistema de desenvolvedores da Meta é simplesmente tremendo para nós.”
A escolha da Meta por silício especializado sinaliza algo profundo: na próxima fase da IA, não é apenas o que seus modelos sabem, mas quão rapidamente eles podem pensar. Nesse futuro, a velocidade não é apenas uma característica — é o foco total.


Conteúdo relacionado

Quebrando o ‘gargalo intelectual’: Como a IA está computando o anteriormente incomputável na saúde.
[the_ad id="145565"] Sure! Here is your content rewritten in Portuguese while keeping the HTML tags intact: Junte-se aos nossos boletins diários e semanais para receber as…

OpenAI explica por que o ChatGPT se tornou excessivamente bajulador
[the_ad id="145565"] A OpenAI publicou um postmortem sobre os recentes problemas de bajulação com o modelo padrão que alimenta o ChatGPT, o GPT-4o — questões que forçaram a…

Structify capta R$ 4,1 milhões em seed para transformar dados não estruturados da web em conjuntos de dados prontos para empresas.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder do setor. Saiba mais…