


É um fato bem conhecido que diferentes famílias de modelos podem usar diferentes tokenizadores. No entanto, houve uma análise limitada sobre como o processo de “tokenização” em si varia entre esses tokenizadores. Todos os tokenizadores resultam no mesmo número de tokens para um determinado texto de entrada? Se não, quão diferentes são os tokens gerados? Quão significativas são as diferenças?
Neste artigo, exploramos essas questões e examinamos as implicações práticas da variabilidade da tokenização. Apresentamos uma história comparativa de duas famílias de modelos de ponta: ChatGPT da Anthropic. Embora suas tarifas anunciadas de “custo por token” sejam altamente competitivas, experiências revelam que os modelos da Anthropic podem ser de 20 a 30% mais caros do que os modelos da GPT.
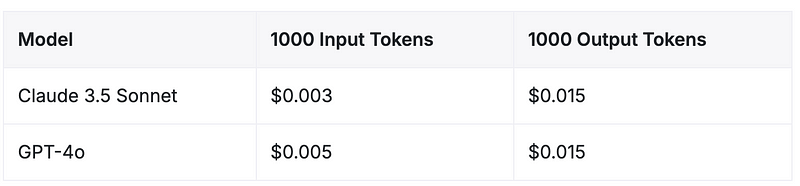
Precificação da API — Claude 3.5 Sonnet vs GPT-4o
A partir de junho de 2024, a estrutura de preços para esses dois modelos de ponta é altamente competitiva. Tanto o Claude 3.5 Sonnet da Anthropic quanto o GPT-4o da OpenAI têm custos idênticos para tokens de saída, enquanto o Claude 3.5 Sonnet oferece um custo 40% mais baixo para tokens de entrada.
Fonte: Vantage
A “ineficiência do tokenizador” oculta
Apesar das taxas de token de entrada mais baixas do modelo da Anthropic, observamos que os custos totais de execução de experimentos (em um conjunto fixo de prompts) com o GPT-4o são muito mais baratos em comparação com o Claude Sonnet-3.5.
Por quê?
O tokenizador da Anthropic tende a dividir a mesma entrada em mais tokens em comparação com o tokenizador da OpenAI. Isso significa que, para prompts idênticos, os modelos da Anthropic produzem significativamente mais tokens do que seus equivalentes da OpenAI. Como resultado, embora o custo por token para a entrada do Claude 3.5 Sonnet possa ser menor, o aumento na tokenização pode anular essas economias, levando a custos totais mais elevados em casos de uso práticos.
Esse custo oculto decorre da maneira como o tokenizador da Anthropic codifica as informações, frequentemente utilizando mais tokens para representar o mesmo conteúdo. A inflação no número de tokens tem um impacto significativo nos custos e na utilização da janela de contexto.
Ineficiência na tokenização dependente do domínio
Diferentes tipos de conteúdo de domínio são tokenizados de forma diferente pelo tokenizador da Anthropic, levando a níveis variados de aumento no número de tokens em comparação com os modelos da OpenAI. A comunidade de pesquisa em IA observou diferenças semelhantes na tokenização aqui. Testamos nossas descobertas em três domínios populares, a saber: artigos em inglês, código (Python) e matemática.
| Domínio | Entrada do Modelo | Tokens GPT | Tokens Claude | % de Sobrecarga de Tokens |
| Artigos em Inglês | 77 | 89 | ~16% | |
| Código (Python) | 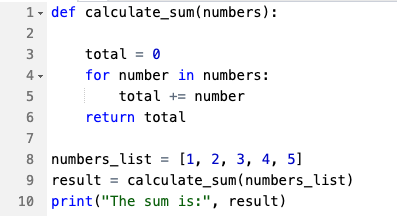 |
60 | 78 | ~30% |
| Matemática | 114 | 138 | ~21% |
% Sobrecarga de Tokens do Tokenizador do Claude 3.5 Sonnet (relativo ao GPT-4o) Fonte: Lavanya Gupta
Ao comparar o Claude 3.5 Sonnet com o GPT-4o, o grau de ineficiência do tokenizador varia significativamente entre os domínios de conteúdo. Para artigos em inglês, o tokenizador do Claude produz aproximadamente 16% mais tokens do que o GPT-4o para o mesmo texto de entrada. Esta sobrecarga aumenta consideravelmente com conteúdos mais estruturados ou técnicos: para equações matemáticas, a sobrecarga está em 21%, e para código em Python, o Claude gera 30% mais tokens.
Essa variação surge porque alguns tipos de conteúdo, como documentos técnicos e código, frequentemente contêm padrões e símbolos que o tokenizador da Anthropic fragmenta em pedaços menores, levando a um número maior de tokens. Em contraste, conteúdos de linguagem natural tendem a exibir uma sobrecarga de tokens menor.
Outras implicações práticas da ineficiência do tokenizador
Além da implicação direta nos custos, há também um impacto indireto na utilização da janela de contexto. Embora os modelos da Anthropic afirmem ter uma janela de contexto maior de 200K tokens, em comparação com os 128K da OpenAI, devido à verbosidade, o espaço de token utilizável efetivo pode ser menor para os modelos da Anthropic. Assim, pode haver potencialmente uma pequena ou grande diferença entre os tamanhos “anunciados” da janela de contexto e os tamanhos “efetivos”.
Implementação dos tokenizadores
Os modelos GPT utilizam Codificação de Pares de Bytes (BPE), que combina pares de caracteres que ocorrem com frequência para formar tokens. Especificamente, os últimos modelos GPT usam o tokenizador open-source o200k_base. Os tokens reais usados pelo GPT-4o (no tokenizador tiktoken) podem ser visualizados aqui.
JSON
{
#raciocínio
"o1-xxx": "o200k_base",
"o3-xxx": "o200k_base",
# chat
"chatgpt-4o-": "o200k_base",
"gpt-4o-xxx": "o200k_base", # e.g., gpt-4o-2024-05-13
"gpt-4-xxx": "cl100k_base", # e.g., gpt-4-0314, etc., mais gpt-4-32k
"gpt-3.5-turbo-xxx": "cl100k_base", # e.g, gpt-3.5-turbo-0301, -0401, etc.
}
Infelizmente, não se pode dizer muito sobre os tokenizadores da Anthropic, pois seu tokenizador não é tão diretamente e facilmente disponível quanto o da GPT. A Anthropic lançou sua API de Contagem de Tokens em dezembro de 2024. No entanto, ela foi logo descontinuada nas versões de 2025.
Latenode relata que “a Anthropic usa um tokenizador único com apenas 65.000 variações de tokens, em comparação com as 100.261 variações de tokens da OpenAI para o GPT-4.” Este notebook do Colab contém código Python para analisar as diferenças de tokenização entre os modelos GPT e Claude. Outra ferramenta que permite interagir com alguns tokenizadores públicos comuns valida nossas descobertas.
A capacidade de estimar proativamente as contagens de tokens (sem invocar a API real do modelo) e orçar custos é crucial para empresas de IA.
Pontos-Chave
- O preço competitivo da Anthropic vem com custos ocultos:
Enquanto o Claude 3.5 Sonnet da Anthropic oferece custos de tokens de entrada 40% mais baixos em comparação com o GPT-4o da OpenAI, essa aparente vantagem de custo pode ser enganosa devido às diferenças na forma como o texto de entrada é tokenizado. - “Ineficiência do tokenizador” oculta:
Os modelos da Anthropic são inerentemente mais verbosos. Para empresas que processam grandes volumes de texto, entender essa discrepância é crucial ao avaliar o verdadeiro custo de implantação dos modelos. - Ineficiência de tokenização dependente do domínio:
Ao escolher entre modelos da OpenAI e da Anthropic, avalie a natureza do seu texto de entrada. Para tarefas de linguagem natural, a diferença de custo pode ser mínima, mas domínios técnicos ou estruturados podem levar a custos significativamente mais altos com os modelos da Anthropic. - Janela de contexto efetiva:
Devido à verbosidade do tokenizador da Anthropic, sua maior janela de contexto anunciada de 200K pode oferecer menos espaço utilizável efetivo do que os 128K da OpenAI, levando a um potencial gap entre a janela de contexto anunciada e a real.
A Anthropic não respondeu aos pedidos de comentário da VentureBeat até o fechamento deste artigo. Atualizaremos a história se eles responderem.


Conteúdo relacionado

Apple e Anthropic supostamente se uniram para criar uma plataforma de codificação de IA.
[the_ad id="145565"] A Apple e a Anthropic estão se unindo para criar uma plataforma de software chamada “vibe-coding” que utilizará inteligência artificial generativa para…

Um dos modelos recentes de IA Gemini do Google apresenta pior desempenho em segurança.
[the_ad id="145565"] Um modelo de IA recém-lançado pela Google obteve pontuação pior em certos testes de segurança em comparação ao seu predecessor, de acordo com a avaliação…

O Google em breve permitirá que crianças menores de 13 anos usem seu chatbot Gemini.
[the_ad id="145565"] Na próxima semana, o Google começará a permitir que crianças menores de 13 anos com contas do Google gerenciadas por pais utilizem seu chatbot Gemini, de…