


Um novo artigo do laboratório de IA Cohere, Stanford, MIT e Ai2 acusa a LM Arena, a organização por trás do popular benchmark de IA crowdsourced Chatbot Arena, de ajudar um grupo seleto de empresas de IA a obter melhores pontuações na tabela de classificação em detrimento de concorrentes.
De acordo com os autores, a LM Arena permitiu que algumas das principais empresas de IA, como Meta, OpenAI, Google e Amazon, testassem em privado várias variantes de modelos de IA, sem publicar as pontuações dos piores desempenhos. Isso facilitou para essas empresas alcançar uma posição de destaque no ranking da plataforma, embora essa oportunidade não tenha sido oferecida a todas as empresas, dizem os autores.
“Apenas um punhado de [empresas] foi informado que esse teste privado estava disponível, e a quantidade de testes privados que algumas [empresas] receberam é muito maior do que outras,” disse Sara Hooker, VP de pesquisa em IA da Cohere e co-autora do estudo, em uma entrevista à TechCrunch. “Isso é gamificação.”
Criado em 2023 como um projeto de pesquisa acadêmica da UC Berkeley, o Chatbot Arena se tornou um benchmark de referência para empresas de IA. Ele funciona colocando respostas de dois modelos de IA diferentes lado a lado em uma “batalha”, pedindo aos usuários que escolham a melhor. Não é incomum ver modelos não lançados competindo na arena sob um pseudônimo.
Os votos ao longo do tempo contribuem para a pontuação de um modelo — e, consequentemente, sua classificação na tabela de classificação do Chatbot Arena. Embora muitos atores comerciais participem do Chatbot Arena, a LM Arena sempre manteve que seu benchmark é imparcial e justo.
No entanto, isso não é o que os autores do artigo dizem ter descoberto.
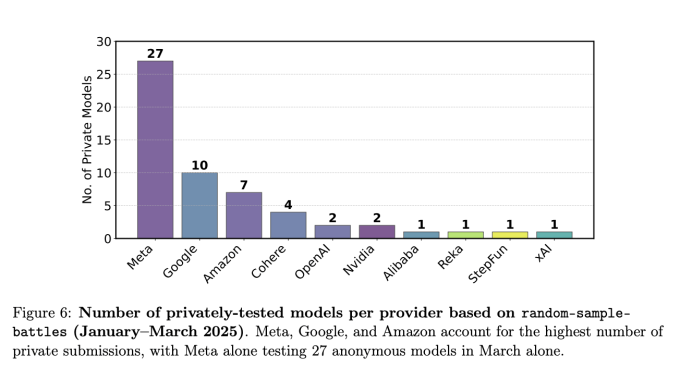
Uma empresa de IA, a Meta, conseguiu testar em privado 27 variantes de modelos no Chatbot Arena entre janeiro e março, levando ao lançamento do Llama 4 do gigante da tecnologia, alegam os autores. No lançamento, a Meta apenas revelou publicamente a pontuação de um único modelo — um modelo que curiosamente classificou-se perto do topo da tabela de classificação do Chatbot Arena.
Evento Techcrunch
Berkeley, CA
|
5 de junho
RESERVE AGORA
Em um e-mail para a TechCrunch, o cofundador da LM Arena e professor da UC Berkeley, Ion Stoica, disse que o estudo estava repleto de “imprecisões” e “análises questionáveis.”
“Estamos comprometidos com avaliações justas e orientadas pela comunidade e convidamos todos os provedores de modelos a submeterem mais modelos para testes e melhorar seu desempenho em preferência humana,” disse a LM Arena em uma declaração fornecida à TechCrunch. “Se um provedor de modelo optar por submeter mais testes do que outro, isso não significa que o segundo provedor de modelo seja tratado de forma injusta.”
Laboratórios supostamente favorecidos
Os autores do artigo começaram sua pesquisa em novembro de 2024 após saber que algumas empresas de IA estavam possivelmente recebendo acesso preferencial ao Chatbot Arena. No total, eles mediram mais de 2,8 milhões de batalhas no Chatbot Arena durante um período de cinco meses.
Os autores afirmam ter encontrado evidências de que a LM Arena permitiu que certas empresas de IA, incluindo Meta, OpenAI e Google, coletassem mais dados do Chatbot Arena, fazendo com que seus modelos aparecessem em um maior número de “batalhas” de modelos. Essa taxa de amostragem aumentada deu a essas empresas uma vantagem desleal, alegam os autores.
Usar dados adicionais da LM Arena poderia melhorar o desempenho de um modelo no Arena Hard, outro benchmark mantido pela LM Arena, em 112%. No entanto, a LM Arena declarou em um post no X que o desempenho no Arena Hard não se correlaciona diretamente com o desempenho no Chatbot Arena.
Hooker afirmou que não está claro como certas empresas de IA poderiam ter recebido acesso prioritário, mas que é incumbente à LM Arena aumentar a sua transparência, independentemente disso.
Em um post no X, a LM Arena afirmou que várias das alegações no artigo não refletem a realidade. A organização apontou para um postagem em seu blog que publicou no início desta semana, indicando que modelos de laboratórios não principais aparecem em mais batalhas no Chatbot Arena do que o estudo sugere.
Uma limitação importante do estudo é que ele se baseou na “autoidentificação” para determinar quais modelos de IA estavam em teste privado no Chatbot Arena. Os autores perguntaram várias vezes aos modelos de IA sobre sua empresa de origem e confiaram nas respostas dos modelos para classificá-los — um método que não é infalível.
No entanto, Hooker disse que quando os autores contataram a LM Arena para compartilhar suas descobertas preliminares, a organização não as contestou.
A TechCrunch entrou em contato com a Meta, Google, OpenAI e Amazon — todas mencionadas no estudo — para comentários. Nenhuma respondeu imediatamente.
LM Arena em apuros
No artigo, os autores pedem à LM Arena que implemente uma série de mudanças destinadas a tornar o Chatbot Arena mais “justo.” Por exemplo, dizem os autores, a LM Arena poderia estabelecer um limite claro e transparente sobre o número de testes privados que os laboratórios de IA podem realizar e divulgar publicamente as pontuações desses testes.
Em um post no X, a LM Arena rejeitou essas sugestões, alegando que publicou informações sobre testes pré-lançamento desde março de 2024. A organização de benchmark também afirmou que “não faz sentido mostrar pontuações para modelos pré-lançamento que não estão disponíveis publicamente,” porque a comunidade de IA não pode testá-los por conta própria.
Os pesquisadores também afirmam que a LM Arena poderia ajustar a taxa de amostragem do Chatbot Arena para garantir que todos os modelos na arena apareçam no mesmo número de batalhas. A LM Arena tem sido receptiva a essa recomendação publicamente, e indicou que criará um novo algoritmo de amostragem.
O artigo aparece semanas depois que a Meta foi pega manipulando benchmarks no Chatbot Arena em torno do lançamento de seus mencionados modelos Llama 4. A Meta otimizou um dos modelos Llama 4 para “conversacionalidade,” o que ajudou a alcançar uma pontuação impressionante na tabela de classificação do Chatbot Arena. Mas a empresa nunca lançou o modelo otimizado — e a versão padrão acabou apresentando um desempenho muito pior no Chatbot Arena.
Na época, a LM Arena disse que a Meta deveria ter sido mais transparente em sua abordagem de benchmarking.
No início deste mês, a LM Arena anunciou que estava lançando uma empresa, com planos de levantar capital de investidores. O estudo aumenta o escrutínio sobre as organizações de benchmark privadas — e se elas podem ser confiáveis para avaliar modelos de IA sem a influência corporativa nublando o processo.
Atualização em 30/04/25 às 21:35 PT: Uma versão anterior desta história incluía comentários de um engenheiro do Google DeepMind que disse que parte do estudo da Cohere estava imprecisa. O pesquisador não contestou que o Google enviou 10 modelos para a LM Arena para testes pré-lançamento de janeiro a março, conforme alega a Cohere, mas simplesmente observou que a equipe de código aberto da empresa, que trabalha no Gemma, enviou apenas um.

Conteúdo relacionado

IA Enfrenta Dificuldades para Emular a Linguagem Histórica
[the_ad id="145565"] Uma colaboração entre pesquisadores dos Estados Unidos e do Canadá descobriu que modelos de linguagem grandes (LLMs) como o ChatGPT enfrentam dificuldades…

Fivetran adquire Census para se tornar uma plataforma de movimentação de dados de ponta a ponta.
[the_ad id="145565"] Após quase 13 anos de operação, Fivetran agora poderá oferecer aos seus clientes uma solução completa de movimentação de dados. A Fivetran, que auxilia…

Anthropic permite que usuários conectem mais aplicativos ao Claude
[the_ad id="145565"] A Anthropic lançou na quinta-feira uma nova maneira de conectar aplicativos e ferramentas ao seu chatbot de IA, Claude, além de uma capacidade de “pesquisa…