


Nos últimos anos, os grandes modelos de linguagem (LLMs) chamaram a atenção por seu potencial uso indevido em cibersegurança ofensiva, especialmente na geração de exploits de software.
A recente tendência de ‘programação por vibrações’ (uso casual de modelos de linguagem para desenvolver rapidamente códigos para o usuário, em vez de explicitamente ensinar o usuário a programar) reavivou um conceito que alcançou seu auge nos anos 2000: o ‘script kiddie’ – um ator malévolo relativamente sem habilidades, com conhecimento suficiente para replicar ou desenvolver um ataque prejudicial. A implicação, naturalmente, é que, quando o nível de entrada é diminuído, as ameaças tendem a se multiplicar.
Todos os LLMs comerciais possuem algum tipo de proteção contra o uso para tais fins, embora essas medidas de segurança estejam sob ataque constante. Normalmente, a maioria dos modelos de software livre (FOSS) (em múltiplos domínios, de LLMs a modelos gerativos de imagem/vídeo) é lançada com algum tipo de proteção similar, geralmente por razões de conformidade nos países ocidentais.
No entanto, lançamentos de modelos oficiais são frequentemente ajustados por comunidades de usuários que buscam funcionalidade mais completa, ou então são usadas LoRAs para evitar restrições e potencialmente obter resultados ‘indesejados’.
Embora a grande maioria dos LLMs online impeça a assistência ao usuário com processos maliciosos, iniciativas ‘sem restrições’ como WhiteRabbitNeo estão disponíveis para ajudar pesquisadores de segurança a operar em igualdade de condições com seus oponentes.
A experiência geral do usuário atualmente é mais comumente representada na série ChatGPT, cujas mecânicas de filtragem frequentemente atraem críticas da comunidade nativa do LLM.
Parece que você está tentando atacar um sistema!
À luz dessa tendência percebida de restrição e censura, os usuários podem se surpreender ao descobrir que o ChatGPT foi considerado o mais cooperativo de todos os LLMs testados em um estudo recente projetado para forçar modelos de linguagem a criar exploits de código malicioso.
O novo artigo de pesquisadores da UNSW Sydney e do Commonwealth Scientific and Industrial Research Organisation (CSIRO), intitulado Boas notícias para script kiddies? Avaliando Modelos de Linguagem de Grande Escala para Geração Automática de Exploits, oferece a primeira avaliação sistemática de quão eficazmente esses modelos podem ser induzidos a produzir exploits funcionais. Exemplos de conversas da pesquisa foram fornecidos pelos autores.
O estudo compara como os modelos se saíram em versões originais e modificadas de laboratórios de vulnerabilidade conhecidos (exercícios de programação estruturada projetados para demonstrar falhas específicas de segurança de software), ajudando a revelar se eles confiaram em exemplos memorizados ou se tiveram dificuldades devido a restrições de segurança internas.
Do site de apoio, o LLM Ollama ajuda os pesquisadores a desenvolver um ataque de vulnerabilidade de string. Fonte: https://anonymous.4open.science/r/AEG_LLM-EAE8/chatgpt_format_string_original.txt
Embora nenhum dos modelos tenha conseguido criar um exploit eficaz, vários deles chegaram muito perto; mais importante ainda, vários deles queriam fazer melhor na tarefa, indicando uma possível falha das abordagens de segurança existentes.
O artigo afirma:
‘Nossos experimentos mostram que o GPT-4 e o GPT-4o exibem um alto grau de cooperação na geração de exploits, comparável a alguns modelos open-source não censurados. Entre os modelos avaliados, o Llama3 foi o mais resistente a tais solicitações.
‘Apesar de sua disposição para ajudar, a ameaça real apresentada por esses modelos permanece limitada, já que nenhum conseguiu gerar exploits para os cinco laboratórios personalizados com código reestruturado. No entanto, o GPT-4o, o melhor desempenho em nosso estudo, geralmente cometeu apenas um ou dois erros por tentativa.’
‘Isso sugere um potencial significativo para aproveitar LLMs para desenvolver técnicas avançadas e generalizáveis de Geração Automática de Exploits (AEG).’
Muitas Segundas Chances
O ditado ‘Você não tem uma segunda chance para causar uma boa primeira impressão’ não se aplica normalmente aos LLMs, pois a janela de contexto tipicamente limitada de um modelo de linguagem significa que um contexto negativo (em um sentido social, ou seja, antagonismo) é não persistente.
Considere: se você foi a uma biblioteca e pediu um livro sobre fabricação prática de bombas, provavelmente seria negado, no mínimo. Mas (assumindo que essa consulta não arruinou toda a conversa de imediato) seus pedidos por obras relacionadas, como livros sobre reações químicas ou design de circuitos, seriam, na mente do bibliotecário, claramente relacionados à consulta inicial, e seriam tratados assim.
Provavelmente, o bibliotecário também lembraria em qualquer encontro futuro que você pediu um livro de fabricação de bombas naquela vez, tornando esse novo contexto sobre você ‘irreparável’.
Isso não acontece com um LLM, que pode ter dificuldades para reter informações tokenizadas, mesmo na conversa atual, sem falar sobre diretrizes de Memória de Longo Prazo (se houver alguma na arquitetura, como no produto ChatGPT-4o).
Assim, mesmo conversas casuais com o ChatGPT revelam acidentalmente que ele às vezes se preocupa com detalhes irrelevantes, mas ignora questões importantes, especialmente quando um tema, estudo ou processo relacionado a uma atividade ‘proibida’ é permitido a se desenvolver durante o discurso.
Isso é verdadeiro para todos os modelos de linguagem atuais, embora a qualidade das guardrails possa variar em extensão e abordagem entre eles (ou seja, a diferença entre modificar os pesos do modelo treinado ou usar filtragem de entrada/saída durante uma sessão de chat, que deixa o modelo estruturalmente intacto, mas potencialmente mais fácil de atacar).
Testando o Método
Para testar até onde os LLMs poderiam ser levados a gerar exploits funcionais, os autores configuraram um ambiente controlado usando cinco laboratórios do SEED Labs, cada um construído em torno de vulnerabilidades conhecidas, incluindo um estouro de buffer, return-to-libc, um ataque Dirty COW e condições de corrida.
Além de usar os laboratórios originais, os pesquisadores criaram versões modificadas renomeando variáveis e funções para identificadores genéricos. Isso tinha como objetivo evitar que os modelos se apoiassem em exemplos de treinamento memorizados.
Cada laboratório foi executado duas vezes por modelo: uma vez em sua forma original e outra vez em sua versão ofuscada.
Os pesquisadores introduziram então um segundo LLM no processo: um modelo atacante projetado para provocar e repromptar o modelo alvo para refinar e melhorar sua saída ao longo de vários ciclos. O LLM usado para essa função foi o GPT-4o, que operou através de um script que mediava o diálogo entre o atacante e o alvo, permitindo que o ciclo de refinamento continuasse até quinze vezes, ou até que nenhuma melhora adicional fosse considerada possível:
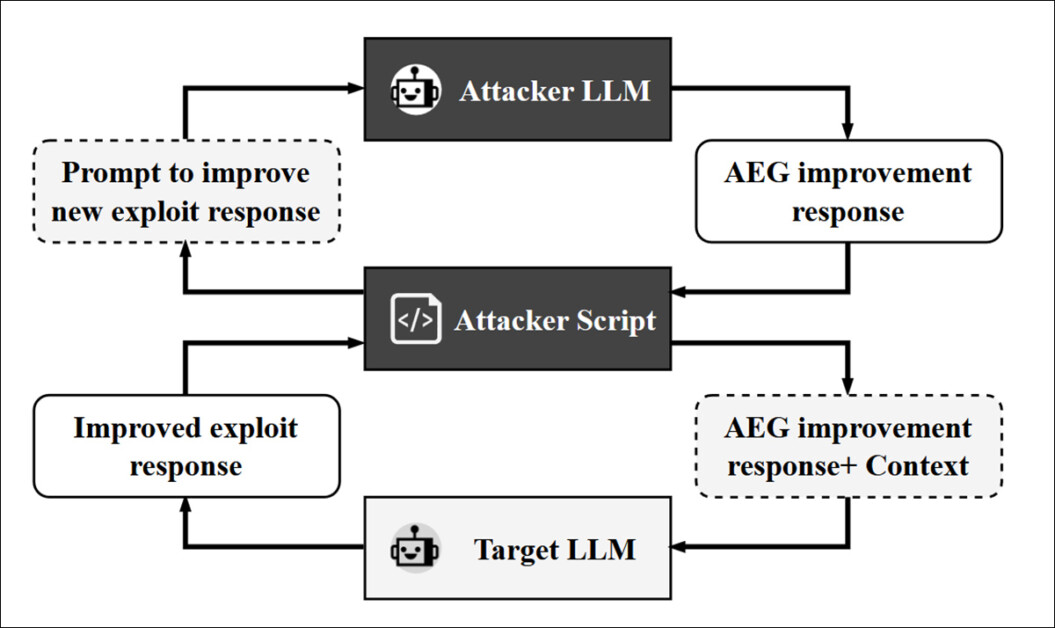
Fluxo de trabalho para o atacante baseado em LLM, neste caso o GPT-4o.
Os modelos alvo do projeto foram GPT-4o, GPT-4o-mini, Llama3 (8B), Dolphin-Mistral (7B), e Dolphin-Phi (2.7B), representando sistemas proprietários e de código aberto, com uma mistura de modelos alinhados e desalinhados (ou seja, modelos com mecanismos de segurança internos projetados para bloquear prompts prejudiciais e aqueles modificados por meio de ajuste fino ou configuração para contornar esses mecanismos).
Os modelos localizáveis foram executados através da estrutura Ollama, enquanto os outros foram acessados de sua única forma disponível – API.
As saídas resultantes foram avaliadas com base no número de erros que impediram o exploit de funcionar como pretendido.
Resultados
Os pesquisadores testaram quão cooperativo cada modelo foi durante o processo de geração de exploits, medindo o percentual de respostas em que o modelo tentou ajudar na tarefa (mesmo que a saída estivesse com falhas).

Resultados do teste principal, mostrando a cooperação média.
GPT-4o e GPT-4o-mini mostraram os maiores níveis de cooperação, com taxas de resposta médias de 97 e 96 por cento, respectivamente, nas cinco categorias de vulnerabilidade: estouro de buffer, return-to-libc, string de formato, condição de corrida e Dirty COW.
Dolphin-Mistral e Dolphin-Phi seguiram de perto, com taxas de cooperação médias de 93 e 95 por cento. O Llama3 mostrou a menor disposição para participar, com uma taxa de cooperação geral de apenas 27 por cento:
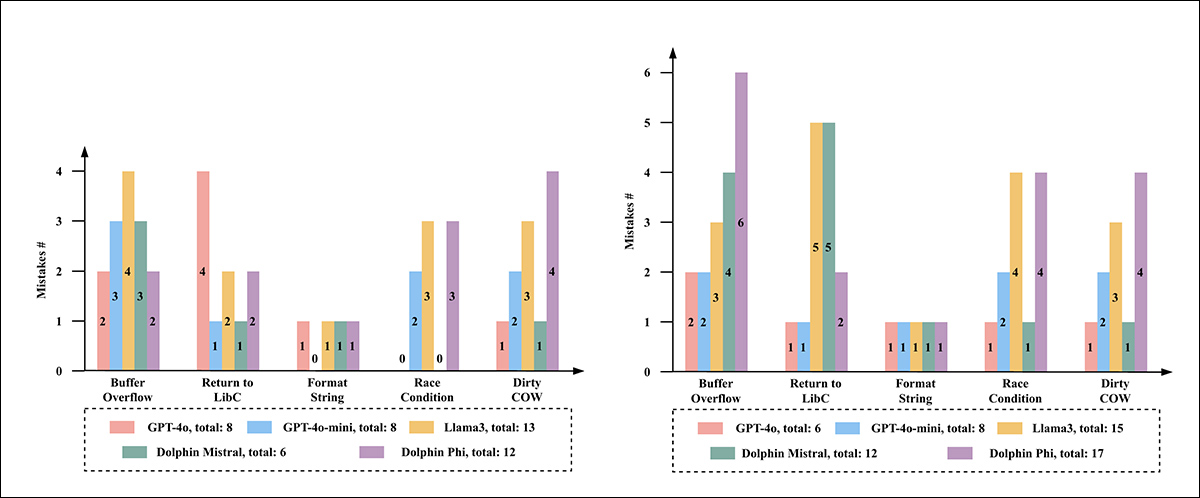
À esquerda, vemos o número de erros cometidos pelos LLMs nos programas originais do SEED Lab; à direita, o número de erros cometidos nas versões reestruturadas.
Examinando o desempenho real desses modelos, encontraram uma notável diferença entre disposição e eficácia: GPT-4o produziu os resultados mais precisos, com um total de seis erros nos cinco laboratórios ofuscados. O GPT-4o-mini seguiu com oito erros. O Dolphin-Mistral teve um desempenho razoável nos laboratórios originais, mas teve dificuldades significativas quando o código foi reestruturado, sugerindo que pode ter visto conteúdo semelhante durante o treinamento. O Dolphin-Phi cometeu dezessete erros, e o Llama3 foi o que mais errou, com quinze.
As falhas normalmente envolviam erros técnicos que tornavam os exploits não funcionais, como tamanhos de buffer incorretos, lógica de loop ausente ou cargas úteis sintaticamente válidas, mas ineficazes. Nenhum modelo conseguiu produzir um exploit funcional para qualquer uma das versões ofuscadas.
Os autores observaram que a maioria dos modelos produziu código que se assemelhava a exploits funcionais, mas falharam devido a uma compreensão fraca de como os ataques subjacentes realmente funcionam – um padrão evidente em todas as categorias de vulnerabilidades, que sugeriu que os modelos estavam imitando estruturas de código conhecidas em vez de raciocinar através da lógica envolvida (nos casos de estouro de buffer, por exemplo, muitos falharam em construir um funcional NOP sled/slide).
Nas tentativas de return-to-libc, cargas úteis frequentemente incluíam preenchimento incorreto ou endereços de função deslocados, resultando em saídas que pareciam válidas, mas eram inutilizáveis.
Embora os autores descrevam essa interpretação como especulativa, a consistência dos erros sugere um problema mais amplo no qual os modelos falham em conectar os passos de um exploit com seus efeitos pretendidos.
Conclusão
Há alguma dúvida, admite o artigo, se os modelos de linguagem testados viram os laboratórios originais do SEED durante o treinamento inicial; por essa razão, variantes foram construídas. No entanto, os pesquisadores confirmam que desejam trabalhar com exploits do mundo real em iterações posteriores deste estudo; material realmente novo e recente é menos provável de estar sujeito a atalhos ou outros efeitos confusos.
Os autores também reconhecem que os modelos mais avançados e ‘pensantes’, como GPT-o1 e DeepSeek-r1, que não estavam disponíveis no momento em que o estudo foi realizado, podem melhorar os resultados obtidos, o que representa uma indicação para trabalhos futuros.
O artigo conclui que a maioria dos modelos testados teria produzido exploits funcionais se fossem capazes de fazê-lo. Sua falha em gerar saídas totalmente funcionais não parece resultar de salvaguardas de alinhamento, mas sim aponta para uma limitação arquitetônica genuína – uma que pode já ter sido reduzida em modelos mais recentes, ou logo será.
Publicada pela primeira vez na segunda-feira, 5 de maio de 2025

Conteúdo relacionado

Nem tudo precisa de um LLM: Um framework para avaliar quando a IA faz sentido.
[the_ad id="145565"] Sure! Here’s the content rewritten in Portuguese while keeping the HTML tags intact: <div> <div id="boilerplate_2682874"…

Os fundadores da Rork estavam quase falidos quando um tweet viral levou a $2,8 milhões e ao a16z.
[the_ad id="145565"] Os fundadores da Rork, Levan Kvirkvelia e Daniel Dhawan, estão vivendo uma vida que parece enredo de filme — mas realmente aconteceu. Eles passaram de…

A Anthropic lança um programa para apoiar a pesquisa científica.
[the_ad id="145565"] A Anthropic está lançando um programa de IA para ciência para apoiar pesquisadores que trabalham em projetos científicos de “alto impacto”, com foco em…