


Este artigo discute um novo lançamento de um modelo multimodal Hunyuan Video chamado ‘HunyuanCustom’. A amplitude de cobertura do novo artigo, combinada com várias questões em muitos dos vídeos de exemplo fornecidos na página do projeto*, nos restringem a uma cobertura mais geral do que o habitual, e a uma reprodução limitada da enorme quantidade de material de vídeo que acompanha este lançamento (uma vez que muitos dos vídeos exigem uma reedição e processamento significativos para melhorar a legibilidade do layout).
Por favor, note também que o artigo refere-se ao sistema generativo baseado em API Kling como ‘Keling’. Para esclarecimento, eu me referirei a ‘Kling’ a partir de agora.
A Tencent está em processo de lançamento de uma nova versão de seu modelo Hunyuan Video, intitulado HunyuanCustom. O novo lançamento é aparentemente capaz de tornar os modelos Hunyuan LoRA redundantes, permitindo ao usuário criar personalizações em vídeo no estilo ‘deepfake’ através de uma única imagem:
Clique para tocar. Prompt: ‘Um homem está ouvindo música e cozinhando noodles de caracol na cozinha’. O novo método foi comparado tanto a métodos de código fechado quanto de código aberto, incluindo Kling, que é um concorrente significativo neste espaço.Fonte: https://hunyuancustom.github.io/ (aviso: site intensivo em CPU/memória!)
Na coluna mais à esquerda do vídeo acima, vemos a única imagem fonte fornecida para o HunyuanCustom, seguida pela interpretação do prompt pelo novo sistema na segunda coluna ao lado. As colunas restantes mostram os resultados de vários sistemas proprietários e de FOSS: Kling; Vidu; Pika; Hailuo; e o Wan-baseado SkyReels-A2.
No vídeo abaixo, vemos renders de três cenários essenciais para este lançamento: respectivamente, pessoa + objeto; emulação de personagem único; e prova virtual (pessoa + roupas):
Clique para tocar. Três exemplos editados a partir do material no site de apoio ao Hunyuan Video.
Podemos notar algumas coisas a partir desses exemplos, principalmente relacionadas ao sistema que depende de uma única imagem fonte, em vez de múltiplas imagens do mesmo sujeito.
No primeiro clipe, o homem está essencialmente virado para a câmera. Ele abaixa a cabeça e inclina-se para os lados em não mais do que 20-25 graus de rotação, mas, com uma inclinação além disso, o sistema realmente teria que começar a adivinhar como ele se parece de perfil. Isso é difícil, provavelmente impossível de avaliar com precisão a partir de uma única imagem frontal.
No segundo exemplo, vemos que a menina está sorrindo no vídeo renderizado, assim como na imagem fonte estática única. Novamente, com essa imagem única como referência, o HunyuanCustom teria que fazer uma adivinhação relativamente desinformada sobre como seria seu ‘rosto em repouso’. Além disso, seu rosto não se desvia da posição voltada para a câmera mais do que no exemplo anterior (‘homem comendo batatas fritas’).
No último exemplo, vemos que, uma vez que o material fonte – a mulher e as roupas que ela é instruída a usar – não são imagens completas, o renderizou o cenário para se ajustar – o que, na verdade, é uma boa solução para um problema de dados!
A questão é que, embora o novo sistema possa lidar com múltiplas imagens (como pessoa + batatas fritas, ou pessoa + roupas), ele aparentemente não permite múltiplos ângulos ou visões alternativas de um único personagem, de modo que expressões diversas ou ângulos incomuns poderiam ser acomodados. Nesse sentido, o sistema pode, portanto, ter dificuldades para substituir o crescente ecossistema de modelos LoRA que surgiram em torno do HunyuanVideo desde seu lançamento em dezembro passado, uma vez que estes podem ajudar o HunyuanVideo a produzir personagens consistentes de qualquer ângulo e com qualquer expressão facial representada no conjunto de dados de treinamento (20-60 imagens é típico).
Preparados para o Som
Para áudio, o HunyuanCustom utiliza o sistema LatentSync (notoriamente difícil de configurar e obter bons resultados para os hobistas) para obter movimentos labiais que estão alinhados com áudio e texto que o usuário fornece:
Funciona com áudio. Clique para tocar.Vários exemplos de sincronização labial do site suplementar do HunyuanCustom, editados juntos.
No momento da redação, não há exemplos em inglês, mas parecem ser bastante bons – ainda mais se o método de criação deles for facilmente instalável e acessível.
Edição de Vídeo Existente
O novo sistema oferece resultados muito impressionantes para edição de vídeo-para-vídeo (V2V, ou Vid2Vid), no qual um segmento de um vídeo existente (real) é mascarado e substituído inteligentemente por um sujeito dado em uma única imagem de referência. Abaixo está um exemplo do site de materiais suplementares:
Clique para tocar. Somente o objeto central é alvo, mas o que permanece ao redor também é alterado em uma passagem vid2vid do HunyuanCustom.
Como podemos ver, e como é padrão em um cenário vid2vid, o vídeo inteiro é de certa forma alterado pelo processo, embora a maior parte da alteração ocorra na região alvo, ou seja, o brinquedo de pelúcia. Presumivelmente, pipelines poderiam ser desenvolvidos para criar tais transformações sob uma abordagem de garbage matte que deixa a maior parte do conteúdo do vídeo idêntico ao original. É isso que o Adobe Firefly faz nos bastidores, e faz bastante bem – mas é um processo pouco estudado na cena generativa de FOSS.
Isso dito, a maioria dos exemplos alternativos fornecidos faz um trabalho melhor ao apontar essas integrações, como podemos ver na compilação montada abaixo:
Clique para tocar.Diversos exemplos de conteúdo intercalado usando vid2vid no HunyuanCustom, exibindo notável respeito pelo material não-alvo.
Um Novo Começo?
Esta iniciativa é um desenvolvimento do projeto Hunyuan Video, não uma mudança abrupta nesse fluxo de desenvolvimento. As melhorias do projeto são introduzidas como inserções arquitetônicas discretas, em vez de mudanças estruturais abrangentes, visando permitir que o modelo mantenha a fidelidade da identidade entre os quadros sem depender de ajustes específicos do sujeito, como com LoRA ou abordagens de inversão textual.
Para ser claro, portanto, o HunyuanCustom não é treinado do zero, mas sim um ajuste fino do modelo base HunyuanVideo de dezembro de 2024.
Aqueles que desenvolveram LoRAs para HunyuanVideo podem se perguntar se ainda funcionarão com esta nova edição, ou se terão que reinventar a roda LoRA mais uma vez se desejarem mais capacidades de personalização do que são construídas neste novo lançamento.
De modo geral, um lançamento finamente ajustado de um modelo hiperescalar altera os pesos do modelo o suficiente para que LoRAs criadas para o modelo anterior não funcionem corretamente, ou de forma alguma, com o modelo recém-refinado.
Às vezes, no entanto, a popularidade de um ajuste fino pode desafiar suas origens: um exemplo de um ajuste fino se tornando um efetivo fork, com um ecossistema e seguidores dedicados, é a afinação Pony Diffusion de Stable Diffusion XL (SDXL). Pony atualmente tem mais de 592.000 downloads no domínio em constante mudança CivitAI, com uma vasta gama de LoRAs que usaram Pony (e não SDXL) como o modelo base, e que requerem Pony na hora da inferência.
Lançamento
A página do projeto para o novo artigo (que se intitula HunyuanCustom: Uma Arquitetura Orientada por Múltiplas Modalidades para Geração de Vídeos Personalizados) apresenta links para um site do GitHub que, enquanto escrevo, acaba de se tornar funcional e parece conter todo o código e pesos necessários para implementação local, juntamente com um cronograma proposto (onde a única coisa importante que ainda está por vir é a integração do ComfyUI).
No momento da redação, a presença do projeto no Hugging Face ainda é um 404. No entanto, há uma versão baseada em API onde aparentemente se pode demonstrar o sistema, desde que você possa fornecer um código QR do WeChat.
Raramente vi um uso tão elaborado e extenso de uma tão ampla variedade de projetos em uma única montagem, como é evidente no HunyuanCustom – e presumivelmente algumas das licenças obrigariam, de qualquer forma, um lançamento completo.
Dois modelos foram anunciados na página do GitHub: uma versão de 720px1280px que requer 8 GB de Memória de Pico de GPU, e uma versão de 512px896px que requer 60 GB de Memória de Pico de GPU.
O repositório declara que ‘A memória mínima de GPU necessária é de 24 GB para 720px1280px129f, mas muito lenta… Recomendamos usar uma GPU com 80 GB de memória para uma melhor qualidade de geração’ – e reiterou que o sistema foi testado apenas até agora no Linux.
O modelo anterior Hunyuan Video foi, desde o lançamento oficial, quantizado em tamanhos onde pode ser executado com menos de 24 GB de VRAM, e parece razoável supor que o novo modelo será igualmente adaptado em formas mais amigáveis para consumidores pela comunidade, e que rapidamente será adaptado para uso em sistemas Windows também.
Devido a restrições de tempo e à quantidade esmagadora de informações que acompanham este lançamento, só podemos dar uma olhada mais ampla, e não tão aprofundada, neste lançamento. No entanto, vamos levantar um pouco a tampa do HunyuanCustom.
Uma Olhada no Artigo
A pipeline de dados para o HunyuanCustom, aparentemente em conformidade com o quadro GDPR, incorpora tanto conjuntos de dados de vídeo sintetizados quanto de código aberto, incluindo OpenHumanVid, com oito categorias centrais representadas: humanos, animais, plantas, paisagens, veículos, objetos, arquitetura, e anime.

Do artigo de lançamento, uma visão geral dos diversos pacotes contribuintes na pipeline de construção de dados do HunyuanCustom. Fonte: https://arxiv.org/pdf/2505.04512
A filtragem inicial começa com PySceneDetect, que segmenta vídeos em clipes de planos únicos. O TextBPN-Plus-Plus é então usado para remover vídeos que contêm excesso de texto na tela, legendas, marcas d’água ou logotipos.
Para abordar inconsistências em resolução e duração, os clipes são padronizados para cinco segundos de duração e redimensionados para 512 ou 720 pixels no lado curto. A filtragem estética é gerida usando Koala-36M, com um limiar personalizado de 0,06 aplicado para o conjunto de dados personalizado, elaborado pelos pesquisadores do novo artigo.
O processo de extração de sujeito combina o Qwen7B Large Language Model (LLM), a estrutura de reconhecimento de objetos YOLO11X, e a popular arquitetura InsightFace, para identificar e validar identidades humanas.
Para sujeitos não humanos, QwenVL e Grounded SAM 2 são usados para extrair caixas delimitadoras relevantes, que são descartadas se muito pequenas.

Exemplos de segmentação semântica com Grounded SAM 2, usado no projeto Hunyuan Control. Fonte: https://github.com/IDEA-Research/Grounded-SAM-2
A extração de múltiplos sujeitos utiliza Florence2 para anotação de caixas delimitadoras e Grounded SAM 2 para segmentação, seguida por agrupamento e segmentação temporal dos quadros de treinamento.
Os clipes processados são ainda aprimorados por meio de anotação, utilizando um sistema de rotulagem estruturada proprietário desenvolvido pela equipe Hunyuan, que fornece metadados em camadas, como descrições e indicadores de movimento de câmera.
Estratégias de data augmentation, incluindo a conversão em caixas delimitadoras, foram aplicadas durante o treinamento para reduzir overfitting e garantir que o modelo se adapte a diversas formas de objetos.
Os dados de áudio foram sincronizados usando o mencionado LatentSync, e clipes descartados se as pontuações de sincronização caírem abaixo de um limiar mínimo.
O framework de avaliação de qualidade de imagem cega HyperIQA foi usado para excluir vídeos pontuando abaixo de 40 (na escala personalizada do HyperIQA). As trilhas de áudio válidas foram então processadas com Whisper para extrair características para tarefas posteriores.
Os autores incorporam o modelo assistente de linguagem LLaVA durante a fase de anotação, e enfatizam a posição central que esse framework tem no HunyuanCustom. O LLaVA é usado para gerar legendas de imagens e ajudar a alinhar o conteúdo visual com prompts textuais, apoiando a construção de um sinal de treinamento coerente entre as modalidades:
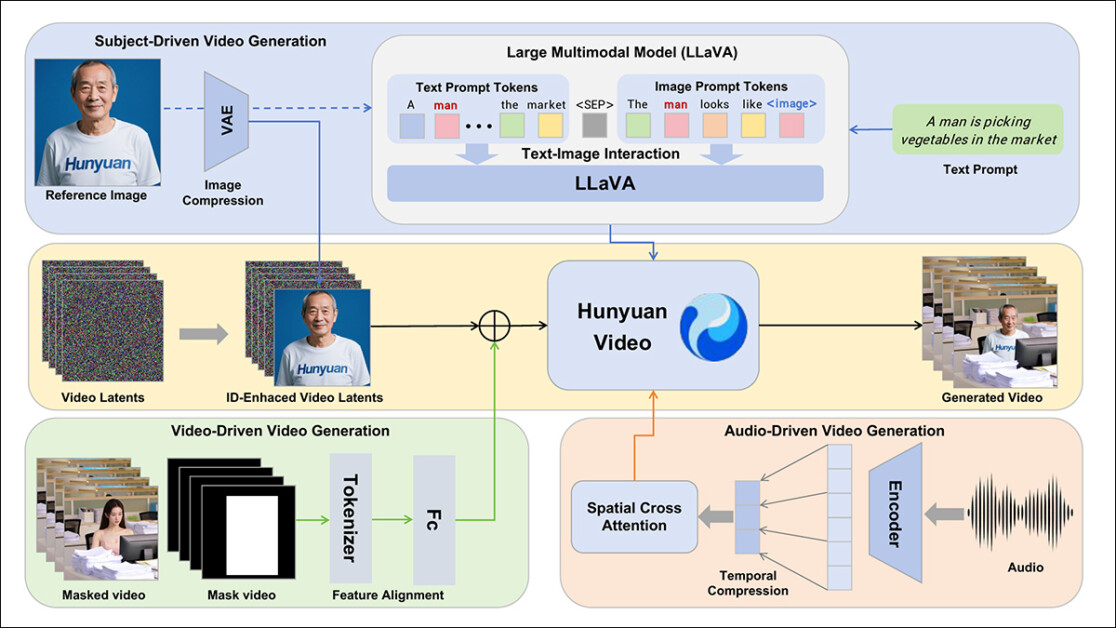
A estrutura HunyuanCustom apoia a geração de vídeo consistente em identidade condicionada a entradas de texto, imagem, áudio e vídeo.
Aproveitando as capacidades de alinhamento de linguagem-visual do LLaVA, a pipeline ganha uma camada adicional de consistência semântica entre elementos visuais e suas descrições textuais – especialmente valiosa em cenários com múltiplos sujeitos ou cenas complexas.
Vídeo Personalizado
Para permitir a geração de vídeo com base em uma imagem de referência e um prompt, os dois módulos centrados no LLaVA foram criados, adaptando primeiro a estrutura de entrada do HunyuanVideo para que ele pudesse aceitar uma imagem junto com o texto.
Isso envolveu formatar o prompt de uma maneira que incorpora a imagem diretamente ou a marca com uma breve descrição de identidade. Um token separador foi usado para impedir que a incorporação da imagem sobrecarregasse o conteúdo do prompt.
Uma vez que o codificador visual do LLaVA tende a comprimir ou descartar detalhes espaciais finos durante o alinhamento das características de imagem e texto (particularmente ao traduzir uma única imagem de referência em uma incorporação semântica geral), um módulo de aprimoramento de identidade foi incorporado. Uma vez que quase todos os modelos de difusão latente de vídeo têm alguma dificuldade em manter uma identidade sem um LoRA, mesmo em um clipe de cinco segundos, o desempenho desse módulo em testes comunitários pode se provar significativo.
De qualquer forma, a imagem de referência é então redimensionada e codificada usando o VAE 3D causal do modelo HunyuanVideo original, e sua latência inserida na latência de vídeo ao longo do eixo temporal, com um deslocamento espacial aplicado para evitar que a imagem seja reproduzida diretamente na saída, enquanto ainda orienta a geração.
O modelo foi treinado usando Flow Matching, com amostras de ruído retiradas de uma distribuição logit-normal – e a rede foi treinada para recuperar o vídeo correto a partir dessas latências ruidosas. O LLaVA e o gerador de vídeo foram ajustados finamente juntos para que a imagem e o prompt pudessem guiar a saída de maneira mais fluida e manter a consistência da identidade do sujeito.
Para prompts de múltiplos sujeitos, cada par imagem-texto foi inserido separadamente e atribuído a uma posição temporal distinta, permitindo que identidades fossem diferenciadas e apoiando a geração de cenas envolvendo múltiplos sujeitos interagindo.
Som e Visão
O HunyuanCustom condiciona a geração de áudio/fala usando tanto áudio de entrada do usuário quanto um prompt textual, permitindo que os personagens falem dentro de cenas que refletem o cenário descrito.
Para suportar isso, um módulo AudioNet desvinculado de identidade introduz características de áudio sem perturbar os sinais de identidade incorporados a partir da imagem e do prompt de referência. Essas características são alinhadas com a linha do tempo de vídeo comprimido, dividida em segmentos de nível de quadro, e injetadas usando um mecanismo de atenção cruzada multi-camada que mantém cada quadro isolado, preservando a consistência do sujeito e evitando a interferência temporal.
Um segundo módulo de injeção temporal fornece controle mais fino sobre tempo e movimento, trabalhando em conjunto com o AudioNet, mapeando características de áudio para regiões específicas da sequência latente, e usando uma Rede de Perceptron de Múltiplas Camadas (MLP) para convertê-las em deslocamentos de movimento em nível de token. Isso permite que gestos e movimentos faciais sigam o ritmo e a ênfase do áudio falado com maior precisão.
O HunyuanCustom permite que sujeitos em vídeos existentes sejam editados diretamente, substituindo ou inserindo pessoas ou objetos em uma cena sem precisar reconstruir todo o clipe do zero. Isso o torna útil para tarefas que envolvem alteração de aparência ou movimento de maneira direcionada.
Clique para tocar. Um exemplo adicional do site suplementar.
Para facilitar a substituição eficiente de sujeitos em vídeos existentes, o novo sistema evita a abordagem intensiva em recursos de métodos recentes, como o atualmente popular VACE, ou aqueles que mesclam sequências de vídeo inteiras, optando em vez disso pela compressão de um vídeo de referência usando o VAE 3D causal pré-treinado – alinhando-o com as latências de vídeo internas do pipeline de geração e, em seguida, adicionando os dois. Isso mantém o processo relativamente leve, enquanto ainda permite que o conteúdo externo guie a saída.
Uma pequena rede neural manipula o alinhamento entre o vídeo de entrada limpo e as latências ruidosas usadas na geração. O sistema testa duas maneiras de injetar essa informação: mesclando os dois conjuntos de características antes de comprimi-los novamente; e adicionando as características quadro a quadro. O segundo método funciona melhor, descobriram os autores, e evita perda de qualidade enquanto mantém a carga computacional inalterada.
Dados e Testes
Nos testes, as métricas utilizadas foram: o módulo de consistência de identidade em ArcFace, que extrai incorporações faciais tanto da imagem de referência quanto de cada quadro do vídeo gerado, e então calcula a média de similaridade cosseno entre elas; similaridade de sujeito, enviando segmentos do YOLO11x para Dino 2 para comparação; CLIP-B, alinhamento texto-vídeo, que mede similaridade entre o prompt e o vídeo gerado; CLIP-B novamente, para calcular similaridade entre cada quadro e tanto seus quadros vizinhos quanto o primeiro quadro, bem como consistência temporal; e grau dinâmico, conforme definido por VBench.
Como indicado anteriormente, os concorrentes fechados foram Hailuo; Vidu 2.0; Kling (1.6); e Pika. Os frameworks FOSS concorrentes foram VACE e SkyReels-A2.
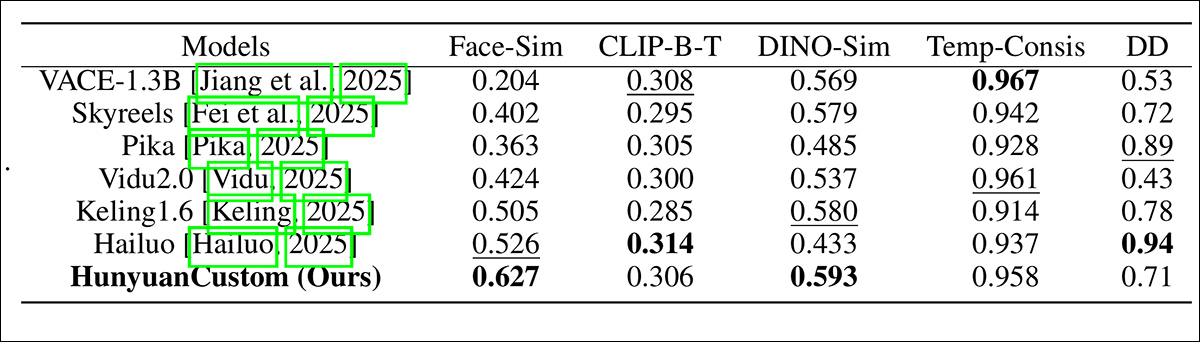
Avaliação de desempenho do modelo comparando HunyuanCustom com métodos de personalização de vídeo líderes em consistência de ID (Face-Sim), similaridade de sujeito (DINO-Sim), alinhamento texto-vídeo (CLIP-B-T), consistência temporal (Temp-Consis), e intensidade de movimento (DD). Resultados óptimos e sub-ótimos são mostrados em negrito e sublinhado, respectivamente.
Dos resultados, os autores afirmam:
‘Nosso [HunyuanCustom] alcança a melhor consistência de ID e similaridade de sujeito. Ele também alcança resultados comparáveis em seguir o prompt e consistência temporal. [Hailuo] tem a melhor pontuação de clipe porque pode seguir bem as instruções de texto com apenas consistência de ID, sacrificando a consistência de sujeitas não humanas (a pior DINO-Sim). Em termos de grau dinâmico, [Vidu] e [VACE] apresentam desempenho ruim, o que pode ser devido ao pequeno tamanho do modelo.’
Embora o site do projeto esteja saturado com vídeos de comparação (cuja disposição parece ter sido projetada para estética do site em vez de fácil comparação), não apresenta atualmente um vídeo equivalente aos resultados estáticos espremidos juntos no PDF, em relação aos testes qualitativos iniciais. Embora eu inclua aqui, encorajo o leitor a realizar uma inspeção atenta dos vídeos no site do projeto, pois eles oferecem uma impressão melhor dos resultados:

Do artigo, uma comparação na personalização de vídeo centrada em objetos. Embora o espectador deva (como sempre) consultar o PDF de origem para melhor resolução, os vídeos no site do projeto podem ser um recurso mais iluminador neste caso.
Os autores comentam aqui:
‘Pode-se ver que [Vidu], [Skyreels A2] e nosso método alcançam resultados relativamente bons em alinhamento de prompt e consistência de sujeito, mas nossa qualidade de vídeo é melhor do que a do Vidu e Skyreels, graças ao bom desempenho de geração de vídeo do nosso modelo base, ou seja, [Hunyuanvideo-13B].
‘Entre os produtos comerciais, embora [Kling] tenha uma boa qualidade de vídeo, o primeiro quadro do vídeo apresenta um problema de cópia e colagem [e], às vezes, o sujeito se move rápido demais e [desfoca], levando a uma experiência de visualização ruim.’
Os autores comentam ainda que o Pika apresenta desempenho ruim em termos de consistência temporal, introduzindo artefatos de legenda (efeitos de uma má curadoria de dados, onde elementos de texto em clipes de vídeo foram permitidos poluir os conceitos centrais).
O Hailuo mantém a identidade facial, afirmam, mas falha em preservar a consistência do corpo inteiro. Entre os métodos de código aberto, o VACE, os pesquisadores afirmam, não consegue manter a consistência de identidade, enquanto eles sustentam que o HunyuanCustom produz vídeos com forte preservação de identidade, enquanto mantém qualidade e diversidade.
Em seguida, foram realizados testes para personalização de vídeo de múltiplos sujeitos, contra os mesmos concorrentes. Assim como no exemplo anterior, os resultados achatados do PDF não são equivalentes a vídeos disponíveis no site do projeto, mas são únicos entre os resultados apresentados:

Comparações usando personalizações de vídeo de múltiplos sujeitos. Por favor, veja o PDF para melhor detalhe e resolução.
O artigo afirma:
‘[Pika] pode gerar os sujeitos especificados, mas apresenta instabilidade nos quadros de vídeo, com instâncias de um homem desaparecendo em um cenário e uma mulher falhando em abrir uma porta conforme solicitado. [Vidu] e [VACE] capturam parcialmente a identidade humana, mas perdem detalhes significativos de objetos não humanos, indicando uma limitação em representar sujeitos não humanos.
‘[SkyReels A2] apresenta instabilidade severa de quadro, com mudanças notáveis em batatas fritas e numerosos artefatos no cenário à direita.
‘Em contraste, nosso HunyuanCustom captura efetivamente tanto as identidades de sujeitos humanos quanto não humanos, gera vídeos que seguem os prompts dados e mantém alta qualidade visual e estabilidade.’
Um experimento adicional foi a ‘publicidade de humanos virtuais’, onde as estruturas foram incumbidas de integrar um produto com uma pessoa:

Na rodada de testes qualitativos, exemplos de ‘colocação de produtos’ neural. Por favor, veja o PDF para melhor detalhe e resolução.
Para esta rodada, os autores afirmam:
‘Os [resultados] demonstram que HunyuanCustom mantém efetivamente a identidade do humano enquanto preserva os detalhes do produto-alvo, incluindo o texto nele.
‘Além disso, a interação entre o humano e o produto parece natural, e o vídeo se adere de perto ao prompt dado, destacando o potencial substancial do HunyuanCustom na geração de vídeos publicitários.’
Uma área onde resultados em vídeo teriam sido muito úteis foi a rodada qualitativa para personalização de sujeito baseada em áudio, onde o personagem fala o áudio correspondente de uma cena descrita em texto e postura.

Resultados parciais dados para a rodada de áudio – embora resultados em vídeo possam ter sido preferíveis neste caso. Apenas a metade superior da figura PDF é reproduzida aqui, pois é grande e difícil de acomodar neste artigo. Por favor, consulte o PDF de origem para melhor detalhe e resolução.
Os autores afirmam:
‘Métodos anteriores de animação humana baseada em áudio inserem uma imagem de humano e um áudio, onde a postura, vestuário e ambiente humano permanecem consistentes com a imagem dada e não podem gerar vídeos em outros gestos e ambientes, o que pode [restrigir] sua aplicação.
‘… [O nosso] HunyuanCustom permite a personalização de humanos baseada em áudio, onde o personagem fala o áudio correspondente em uma cena e postura descritas em texto, permitindo uma animação humana baseada em áudio mais flexível e controlável.’
Novos testes (consultar PDF para todos os detalhes) incluíram uma rodada colocando o novo sistema contra VACE e Kling 1.6 para substituição de sujeito em vídeo:

Testando a substituição de sujeito no modo vídeo-para-vídeo. Por favor, consulte o PDF de origem para melhor detalhe e resolução.
Desses, os últimos testes apresentados no novo artigo, os pesquisadores opinam:
‘O VACE sofre de artefatos de borda devido à estrita adesão às máscaras de entrada, resultando em formas de sujeito não naturais e continuidade de movimento interrompida. [Kling], em contraste, apresenta um efeito de cópia e colagem, onde os sujeitos são sobrepostos diretamente ao vídeo, levando a uma má integração com o fundo.
‘Em comparação, o HunyuanCustom evita efetivamente artefatos de borda, alcança integração perfeita com o fundo do vídeo e mantém forte preservação de identidade – demonstrando seu desempenho superior em tarefas de edição de vídeo.’
Conclusão
Este é um lançamento fascinante, não menos porque aborda algo que a cena dos hobistas sempre descontentes tem reclamado mais recentemente – a falta de sincronização labial, de modo que o aumento do realismo possível em sistemas como Hunyuan Video e Wan 2.1 possa receber uma nova dimensão de autenticidade.
Ainda que a disposição da maioria dos exemplos de vídeos comparativos no site do projeto dificulte a comparação das capacidades do HunyuanCustom contra contendores anteriores, deve ser notado que muito, muito poucos projetos no espaço de síntese de vídeo têm a coragem de se submeter a testes contra o Kling, a API de difusão de vídeo comercial que está sempre rondando ou perto do topo das tabelas de classificação; a Tencent parece ter avançado contra este incumbente de uma forma bastante impressionante.
* A questão é que alguns dos vídeos são tão largos, curtos e de alta resolução que não tocarão em reprodutores de vídeo padrão, como VLC ou Windows Media Player, mostrando telas pretas.
Publicada pela primeira vez na quinta-feira, 8 de maio de 2025

Conteúdo relacionado

Ex-CEO da Synapse estaria tentando arrecadar US$ 100 milhões para sua nova venture em robótica humanoide.
[the_ad id="145565"] A última startup de Sankaet Pathak, a fintech Synapse, entrou com um pedido de falência em 2024 devido a problemas com a parceira Evolve Bank & Trust.…

Anthropic lança API de busca na web Claude, apostando no futuro do acesso à informação pós-Google.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para receber as últimas atualizações e conteúdos exclusivos sobre cobertura de IA de ponta. Saiba mais…

Por que a Hims & Hers recorreu à indústria de veículos autônomos em busca de um CTO especialista em IA
[the_ad id="145565"] A Hims & Hers, empresa de telemedicina e bem-estar, contratou um veterano da indústria de veículos autônomos como seu próximo diretor de tecnologia. De…