


Um novo artigo da Microsoft Research e da Salesforce descobriu que mesmo os mais capazes Modelos de Linguagem de Grande Escala (LLMs) apresentam dificuldades quando instruções são dadas em etapas ao invés de tudo de uma vez. Os autores constataram que o desempenho cai em média 39% em seis tarefas quando um prompt é dividido em várias etapas:

Uma conversa em uma única etapa (esquerda) obtém os melhores resultados, mas é antinatural para o usuário final. Uma conversa em várias etapas (direita) faz com que até os LLMs mais bem classificados e eficientes percam o ímpeto eficaz em uma conversa. Fonte: https://arxiv.org/pdf/2505.06120
Mais surpreendentemente, a confiabilidade das respostas despenca, com modelos renomados como ChatGPT-4.1 e Gemini 2.5 Pro variando entre respostas quase perfeitas e falhas evidentes, dependendo de como a mesma tarefa é formulada; além disso, a consistência da saída pode cair em mais da metade nesse processo.
Para explorar esse comportamento, o artigo introduz um método chamado sharding*, que divide prompts completamente especificados em fragmentos menores e os libera um de cada vez durante uma conversa.
Em termos simples, isso equivale a fazer um pedido coeso e abrangente em um restaurante, deixando ao garçom nada a fazer exceto reconhecer o pedido; ou decidir abordar o assunto de forma colaborativa:

Duas versões extremas de uma conversa no restaurante (não do novo artigo, apenas para fins ilustrativos).
Para enfatizar, o exemplo acima pode colocar o cliente de uma forma negativa. Mas a ideia central retratada na segunda coluna é a de uma troca transacional que esclarece um conjunto de problemas, antes de abordar os problemas – aparentemente uma maneira racional e razoável de abordar uma tarefa.
Essa configuração é refletida no novo trabalho, que adota uma abordagem de interação sharded com LLMs. Os autores observam que os LLMs frequentemente geram respostas excessivamente longas e então continuam a depender de suas próprias percepções mesmo após essas percepções terem sido mostradas como incorretas ou irrelevantes. Essa tendência, combinada com outros fatores, pode fazer com que o sistema perca completamente o controle da troca.
Na verdade, os pesquisadores notam o que muitos de nós descobriram anedoticamente – que a melhor maneira de colocar a conversa de volta nos trilhos é começar uma nova conversa com o LLM.
Se uma conversa com um LLM não levou aos resultados esperados, iniciar uma nova conversa que repete a mesma informação pode gerar resultados significativamente melhores do que continuar uma conversa em andamento.
Isso ocorre porque os LLMs atuais podem se perder na conversa, e nossos experimentos mostram que persistir em uma conversa com o modelo é ineficaz. Além disso, uma vez que os LLMs geram texto com aleatoriedade, uma nova conversa pode levar a resultados melhores.
Os autores reconhecem que sistemas autônomos, como Autogen ou LangChain, podem potencialmente melhorar os resultados agindo como camadas interpretativas entre o usuário final e o LLM, comunicando-se com o LLM apenas quando reuniram respostas ‘sharded’ suficientes para coagular em uma única consulta coesa (a qual o usuário final não terá acesso).
No entanto, os autores sustentam que uma camada de abstração separada não deve ser necessária ou deve ser incorporada diretamente ao LLM de origem:
‘Pode-se argumentar que as capacidades de múltiplas interações não são um recurso necessário de LLMs, já que pode ser transferido para a estrutura do agente. Em outras palavras, precisamos de suporte nativo para múltiplas interações nos LLMs, quando uma estrutura de agente pode orquestrar interações com usuários e aproveitar os LLMs apenas como operadores de um único turno?…’
Mas, após testar a proposição em sua gama de exemplos, eles concluem:
‘[Confiar] em uma estrutura semelhante a um agente para processar informações pode ser limitante, e argumentamos que os LLMs devem suportar nativamente a interação em múltiplas etapas’
Este interessante novo artigo é intitulado LLMs se Perdem em Conversas de Múltiplas Etapas, e vem de quatro pesquisadores da Microsoft Research e Salesforce.
Conversas Fragmentadas
O novo método primeiro divide instruções convencionais de um único turno em pequenos fragmentos, projetados para serem introduzidos em momentos-chave durante uma interação com o LLM, uma estrutura que reflete o estilo de engajamento exploratório e interativo visto em sistemas como ChatGPT ou Google Gemini.
Cada instrução original é um prompt único e autossuficiente que fornece toda a tarefa de uma só vez, combinando uma pergunta de alto nível, contexto de apoio e quaisquer condições relevantes. A versão sharded divide isso em várias partes menores, com cada shard adicionando apenas uma peça de informação:
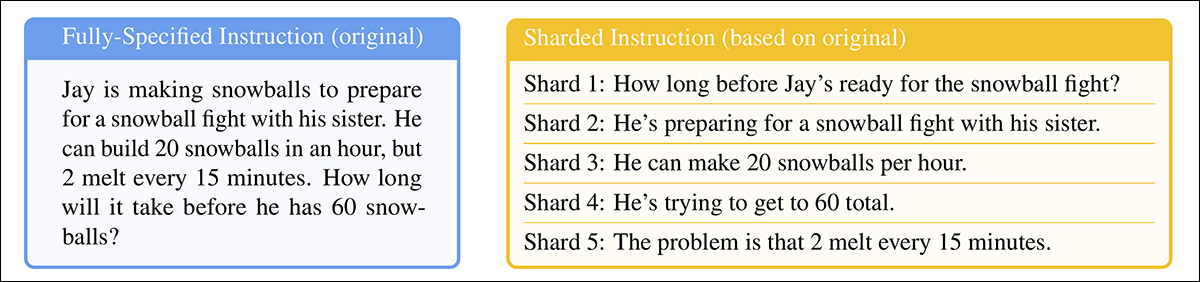
Instruções pareadas mostrando (a) um prompt completo entregue em um único turno e (b) sua versão sharded usada para simular uma interação inadequadamente especificada em múltiplas etapas. Semanticamente, cada versão entrega o mesmo conjunto informativo.
O primeiro shard sempre introduz o objetivo principal da tarefa, enquanto os demais fornecem detalhes esclarecedores. Juntos, eles entregam o mesmo conteúdo que o prompt original, mas espalhado naturalmente em várias etapas da conversa.
Cada conversa simulada se desenrola entre três componentes: o assistente, o modelo em avaliação; o usuário, um agente simulado com acesso à instrução completa em forma sharded; e o sistema, que supervisiona e pontua a troca.
A conversa começa com o usuário revelando o primeiro shard e o assistente respondendo livremente. O sistema então classifica essa resposta em uma das várias categorias, como um pedido de esclarecimento ou uma tentativa de resposta completa.
Se o modelo tentar uma resposta, um componente separado extrai apenas o intervalo relevante para avaliação, ignorando qualquer texto ao redor. A cada novo turno, o usuário revela um shard adicional, solicitando outra resposta. A troca continua até que o modelo acerte a resposta ou não haja mais shards para revelar:
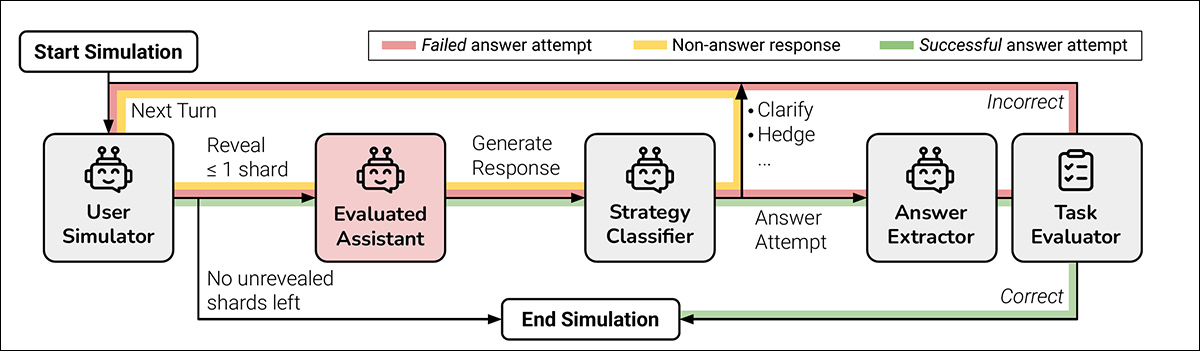
Diagrama de uma simulação de conversa sharded, com o modelo avaliado destacado em vermelho.
Testes iniciais mostraram que os modelos frequentemente perguntavam sobre informações que ainda não haviam sido compartilhadas, então os autores abandonaram a ideia de revelar shards em uma ordem fixa. Em vez disso, um simulador foi usado para decidir qual shard revelar a seguir, com base em como a conversa estava se desenrolando.
O simulador de usuário, implementado usando GPT-4o-mini, teve acesso total tanto à instrução completa quanto ao histórico da conversa, encarregado de decidir, a cada turno, qual shard revelar a seguir, com base em como a troca estava progredindo.
O simulador de usuário também reformulou cada shard para manter o fluxo da conversa, sem alterar o significado. Isso permitiu que a simulação refletisse o ‘dar e receber’ de um diálogo real, enquanto preservava o controle sobre a estrutura da tarefa.
Antes de a conversa começar, o assistente recebe apenas as informações básicas necessárias para completar a tarefa, como um esquema de banco de dados ou uma referência de API. Não é informado de que as instruções serão fragmentadas, e não é guiado em direção a nenhuma maneira específica de lidar com a conversa. Isso é feito intencionalmente: em uso real, os modelos raramente são informados de que um prompt será incompleto ou atualizado ao longo do tempo, e deixar essa contexto de fora ajuda a simulação a refletir como o modelo se comporta em um contexto mais realista.
O GPT-4o-mini também foi usado para decidir como as respostas do modelo deveriam ser classificadas e para extrair qualquer resposta final dessas respostas. Isso ajudou a simulação a manter-se flexível, mas introduziu erros ocasionais: no entanto, após verificar várias centenas de conversas manualmente, os autores descobriram que menos de cinco por cento tiveram problemas, e menos de dois por cento mostraram uma mudança de resultado por causa deles, e consideraram essa taxa de erro baixa o suficiente dentro dos parâmetros do projeto.
Cenários de Simulação
Os autores utilizaram cinco tipos de simulação para testar o comportamento do modelo sob diferentes condições, cada uma uma variação de como e quando partes da instrução são reveladas.
No setting Completo, o modelo recebe a instrução inteira em um único turno. Isso representa o formato padrão de benchmark e serve como a linha de base de desempenho.
O setting Sharded divide a instrução em várias peças e as entrega uma de cada vez, simulando uma conversa mais realista e inadequadamente especificada. Este é o setting principal utilizado para testar como os modelos lidam com entradas em múltiplas etapas.
No setting Concat, os shards são costurados de volta como uma única lista, preservando sua redação, mas removendo a estrutura turno a turno. Isso ajuda a isolar os efeitos da fragmentação da conversa da reformulação ou perda de conteúdo.
O setting Recap funciona como o Sharded, mas adiciona um turno final onde todos os shards anteriores são reiterados antes do modelo dar uma resposta final. Isso testa se um prompt de resumo pode ajudar a recuperar o contexto perdido.
Finalmente, Snowball vai mais longe, repetindo todos os shards anteriores em cada turno, mantendo a instrução completa visível conforme a conversa avança – e oferecendo um teste mais indulgente da capacidade de múltiplas etapas.
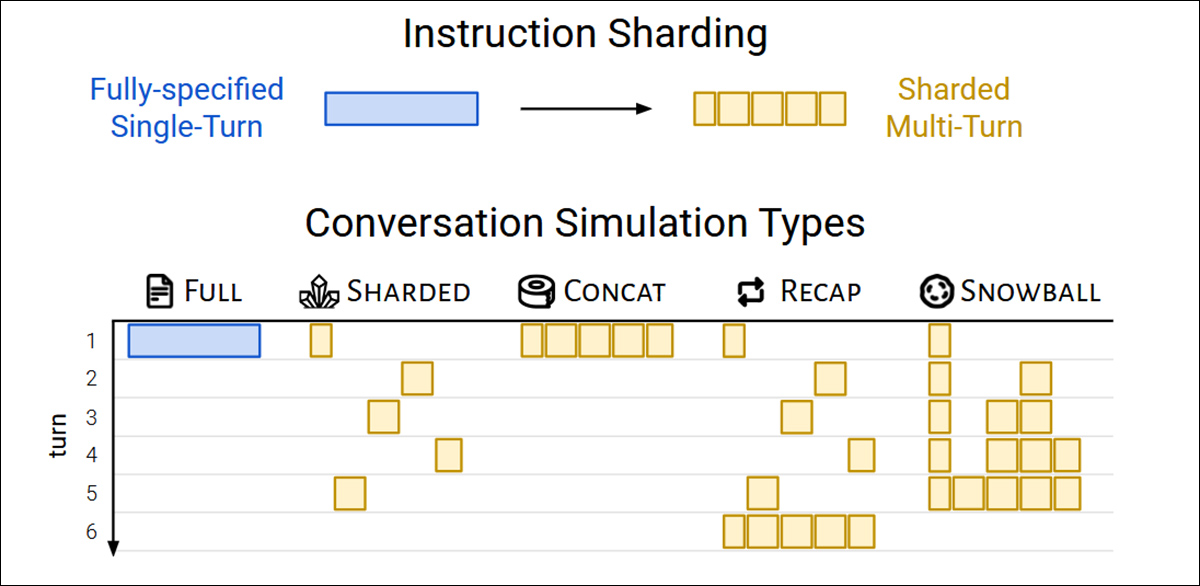
Tipos de simulação baseados em instruções sharded. Um prompt totalmente especificado é dividido em partes menores, que podem então ser usadas para simular conversas de turno único (Completo, Concat) ou múltiplos turnos (Sharded, Recap, Snowball), dependendo da rapidez com que as informações são reveladas.
Tarefas e Métricas
Seis tarefas de geração foram escolhidas para cobrir tanto programação quanto domínios de linguagem natural: prompts de geração de código foram retirados de HumanEval e LiveCodeBench; consultas Text-to-SQL foram extraídas de Spider; chamadas de API foram construídas usando dados do Berkeley Function Calling Leaderboard; problemas matemáticos elementares foram fornecidos por GSM8K; tarefas de legendagem tabular foram baseadas em ToTTo; e resumos de múltiplos documentos foram retirados do Sumário de um Haystack dataset.
O desempenho do modelo foi medido usando três métricas principais: desempenho médio, aptidão, e instabilidade.
Desempenho médio capturou quão bem um modelo se saiu no geral em várias tentativas; aptidão refletiu os melhores resultados que um modelo poderia alcançar, com base em suas saídas de maior pontuação; e instabilidade mediu quanto esses resultados variaram, com lacunas maiores entre os melhores e piores resultados indicando um comportamento menos estável.
Todos os escores foram colocados em uma escala de 0-100 para garantir consistência entre as tarefas, e as métricas computadas para cada instrução – e então médias foram calculadas para fornecer um panorama geral do desempenho do modelo.

Seis tarefas sharded utilizadas nos experimentos, cobrindo tanto programação quanto geração de linguagem natural. Cada tarefa é mostrada com uma instrução totalmente especificada e sua versão sharded. Entre 90 e 120 instruções foram adaptadas a partir de benchmarks estabelecidos para cada tarefa.
Concorrentes e Testes
Nas simulações iniciais (com um custo estimado de $5000), 600 instruções abrangendo seis tarefas foram sharded e usadas para simular três tipos de conversa: completa, concat, e sharded. Para cada combinação de modelo, instrução, e tipo de simulação, dez conversas foram conduzidas, produzindo mais de 200.000 simulações no total – um esquema que tornou possível capturar tanto o desempenho geral quanto medidas mais profundas de aptidão e confiabilidade.
Quinze modelos foram testados, abrangendo uma ampla gama de provedores e arquiteturas: os modelos da OpenAI GPT-4o (versão 2024-11-20), GPT-4o-mini (2024-07-18), GPT-4.1 (2025-04-14), e o modelo de raciocínio o3 (2025-04-16).
Os modelos da Anthropic foram Claude 3 Haiku (2024-03-07) e Claude 3.7 Sonnet (2025-02-19), acessados via Amazon Bedrock.
O Google contribuiu com Gemini 2.5 Flash (preview-04-17) e Gemini 2.5 Pro (preview-03-25). Modelos da Meta foram Llama 3.1-8B-Instruct e Llama 3.3-70B-Instruct, bem como Llama 4 Scout-17B-16E, via Together AI.
As outras entradas foram OLMo 2 13B, Phi-4, e Command-A, todos acessados localmente via Ollama ou Cohere API; e Deepseek-R1, acessado através do Amazon Bedrock.
Para os dois modelos de ‘raciocínio’ (o3 e R1), os limites de tokens foram aumentados para 10.000 para acomodar cadeias de raciocínio mais longas:
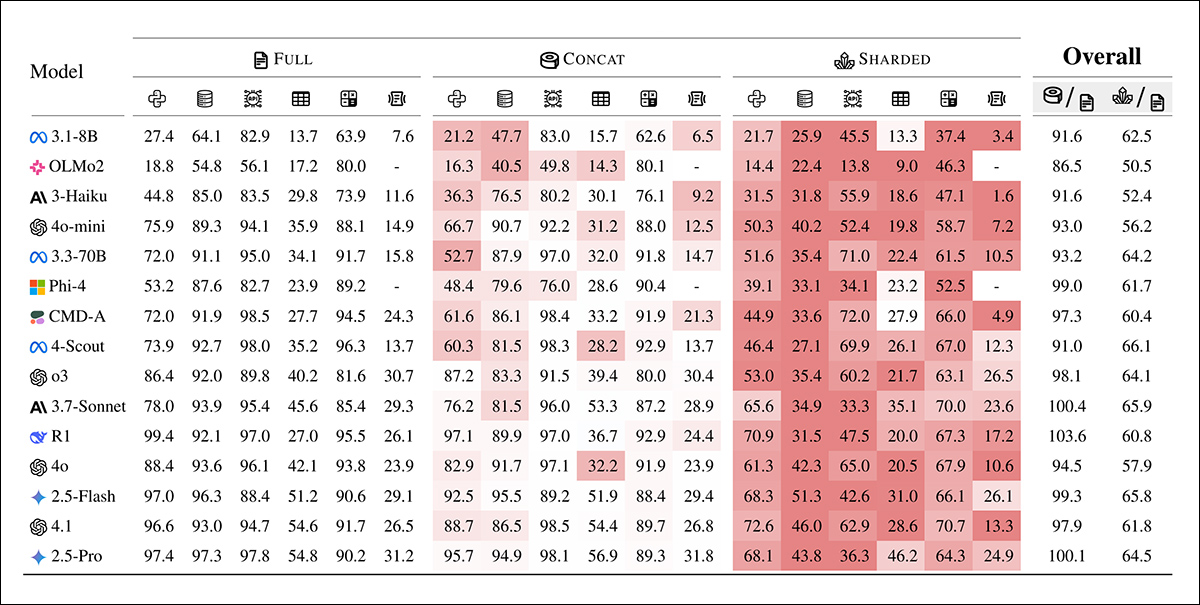
Médias das pontuações de desempenho para cada modelo em seis tarefas: código, banco de dados, ações, data-a-texto, matemática, e resumo. Os resultados são mostrados para três tipos de simulação: completa, concat e sharded. Os modelos estão ordenados pela sua média de pontuação no setting completo. A sombreamento reflete o grau de queda de desempenho em relação ao setting completo, com as duas últimas colunas relatando as quedas médias para concat e sharded em relação ao completo.
Sobre esses resultados, os autores afirmam†:
A um alto nível, todos os modelos veem seu desempenho degradar em todas as tarefas ao comparar desempenho COMPLETO e SHARDED, com uma degradação média de -39%. Nomeamos esse fenômeno Perdido na Conversação: modelos que atingem um desempenho excelente (90%+) na configuração laboratorial de uma conversa totalmente especificada e de um único turno lutam nas mesmas tarefas em um cenário mais realista quando a conversa está inadequadamente especificada e em múltiplos turnos.’
As pontuações de Concat em média 95% de completo, indicando que a queda de desempenho no setting sharded não pode ser explicada por perda de informação. Modelos menores, como Llama3.1-8B-Instruct, OLMo-2-13B, e Claude 3 Haiku mostraram uma degradação mais pronunciada sob concat, sugerindo que modelos menores são geralmente menos robustos à reformulação do que os maiores.
Os autores observam†:
Surpreendentemente, modelos mais eficientes (Claude 3.7 Sonnet, Gemini 2.5, GPT-4.1) se perdem igualmente na conversação em comparação com modelos menores (Llama3.1-8B-Instruct, Phi-4), com degradações médias de 30-40%. Isso se deve em parte às definições de métrica. Como modelos menores alcançam pontuações absolutas mais baixas em COMPLETO, eles têm menos margem para degradação do que os modelos melhores.
‘Em suma, não importa quão forte seja o desempenho de um LLM em um único turno, observamos grandes degradações no desempenho na configuração de múltiplos turnos.’
A testagem inicial indica que alguns modelos se saíram melhor em tarefas específicas: Command-A em Ações, Claude 3.7 Sonnet e GPT-4.1 em código; e Gemini 2.5 Pro em Data-a-Texto, indicando que a capacidade de múltiplos turnos varia conforme o domínio. Modelos de raciocínio, como o3 e Deepseek-R1, não se saíram melhor no geral, talvez porque suas respostas mais longas introduziram mais suposições, que tendiam a confundir a conversa.
Confiabilidade
A relação entre aptidão e confiabilidade, clara em simulações de um único turno, pareceu se desintegrar em condições de múltiplos turnos. Enquanto a aptidão declinou apenas modestamente, a instabilidade dobrou em média. Modelos que eram estáveis em prompts completos, como GPT-4.1 e Gemini 2.5 Pro, tornaram-se tão erráticos quanto modelos mais fracos, como Llama3.1-8B-Instruct ou OLMo-2-13B, uma vez que a instrução foi fragmentada.
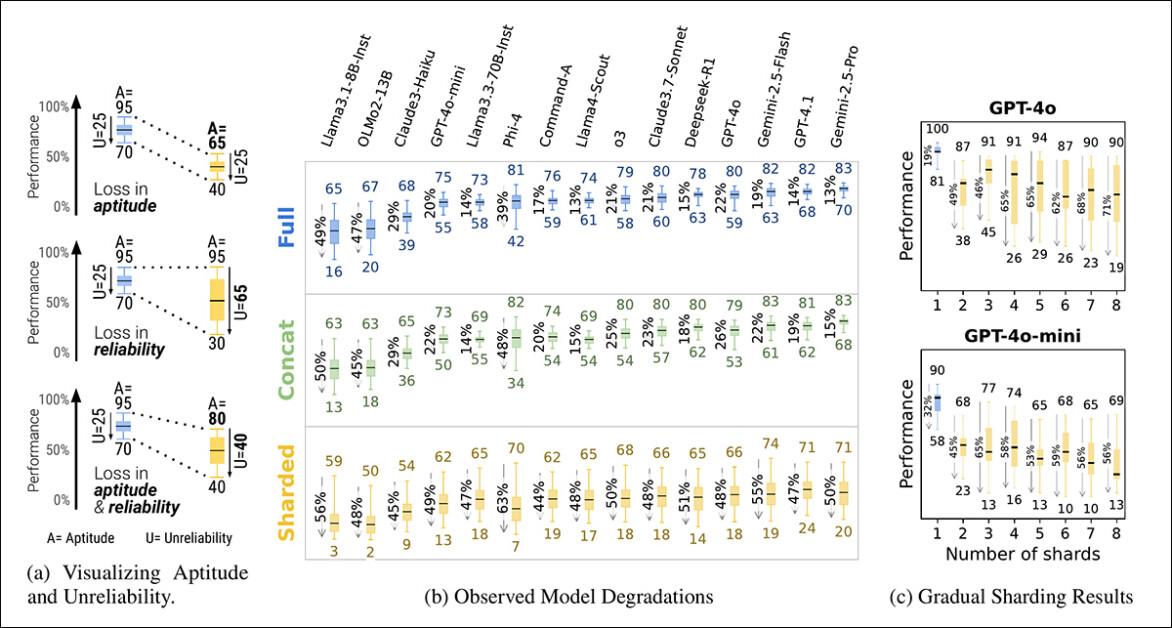
Visão geral da aptidão e instabilidade como mostrado em um gráfico de caixa (a), seguido pelos resultados de confiabilidade de experimentos com quinze modelos (b), e resultados do teste de fragmentação gradual onde as instruções foram divididas em um a oito shards (c).
As respostas do modelo frequentemente variaram em até 50 pontos na mesma tarefa, mesmo quando nada novo foi adicionado, sugerindo que a queda no desempenho não se deve a uma falta de habilidade, mas ao modelo se tornando cada vez mais instável entre os turnos.
O artigo afirma†:
Embora modelos melhores tendam a ter uma aptidão de múltiplos turnos ligeiramente mais alta, todos os modelos tendem a ter níveis semelhantes de instabilidade. Em outras palavras, em configurações multi-turno, inadequadamente especificadas, todos os modelos que testamos apresentam uma instabilidade muito alta, com o desempenho se degradando 50 pontos percentuais em média entre a melhor e a pior simulação realizada para uma instrução fixa.
Para testar se a degradação do desempenho estava ligada ao número de turnos, os autores realizaram um experimento de fragmentação gradual, dividindo cada instrução em um a oito shards (veja a coluna mais à direita na imagem acima).
Conforme o número de shards aumentava, a instabilidade aumentava de forma constante, confirmando que mesmo pequenas aumentos na contagem de turnos tornavam os modelos mais instáveis. A aptidão permaneceu praticamente inalterada, reforçando que o problema reside na consistência, e não na capacidade.
Controle de Temperatura
Um conjunto separado de experimentos testou se a instabilidade era simplesmente um subproduto da aleatoriedade. Para isso, os autores variaram a configuração de temperatura tanto do assistente quanto do simulador de usuário em três valores: 1.0, 0.5 e 0.0.
Em formatos de um único turno como completo e concat, reduzir a temperatura do assistente melhorou significativamente a confiabilidade, cortando a variação em até 80%; mas no setting sharded, a mesma intervenção teve pouco efeito:
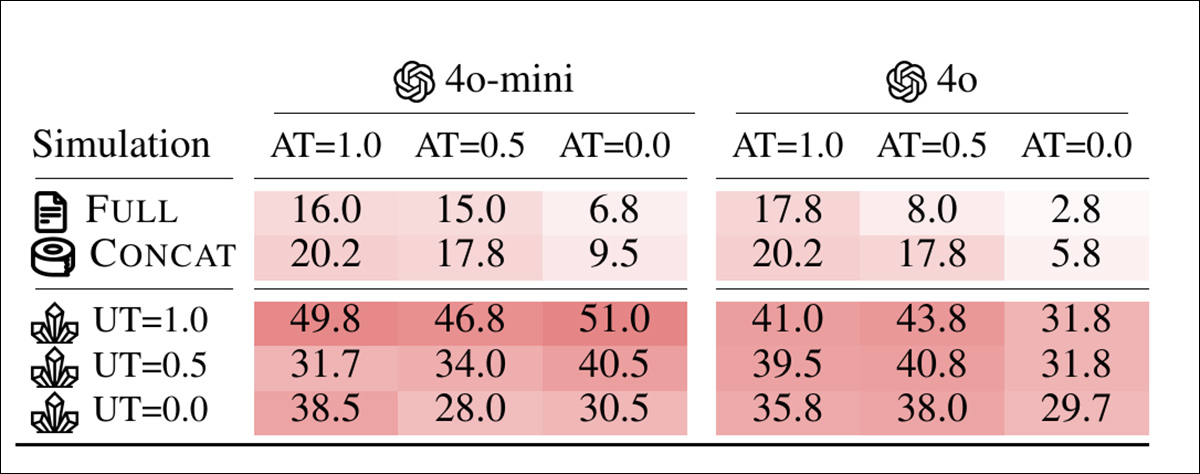
Pontuações de instabilidade para diferentes combinações de temperatura do assistente e do usuário nas configurações completa, concat e sharded, com valores mais baixos indicando maior consistência de resposta.
Mesmo quando tanto o assistente quanto o usuário foram configurados para temperatura zero, a instabilidade permaneceu alta, com o GPT-4o mostrando variação em torno de 30%, sugerindo que a instabilidade observada em conversas de múltiplos turnos não é apenas ruído estocástico, mas uma fraqueza estrutural em como os modelos lidam com entradas fragmentadas.
Implicações
Os autores escrevem sobre as implicações de suas descobertas de forma incomum ao longo da conclusão do artigo, argumentando que um forte desempenho em um único turno não garante confiabilidade em múltiplos turnos, e alertando contra a dependência excessiva de benchmarks totalmente especificados ao avaliar a prontidão para o mundo real (já que benchmarks desse tipo encobrem a instabilidade em interações mais naturais e fragmentadas).
Eles também sugerem que a instabilidade não é apenas um artefato de amostragem, mas uma limitação fundamental em como os modelos atuais processam entradas em evolução, e eles sugerem que isso gera preocupações para estruturas de agentes, que dependem de raciocínio sustentado ao longo de múltiplos turnos.
Finalmente, argumentam que a habilidade de múltiplos turnos deve ser tratada como uma capacidade central dos LLMs, e não algo transferido para sistemas externos.
Os autores observam que seus resultados provavelmente subestimam a verdadeira dimensão do problema, e chamam a atenção para as condições ideais do teste: o simulador de usuário em sua configuração tinha acesso total à instrução e poderia revelar shards na ordem ideal, o que deu ao assistente um contexto irrealisticamente favorável (em uso do mundo real, os usuários costumam fornecer prompts fragmentados ou ambíguos sem saber o que o modelo precisa ouvir a seguir).
Além disso, o assistente foi avaliado imediatamente após cada turno, antes que a conversa completa se desenrolasse, impedindo que confusões ou autorrefutações posteriores fossem penalizadas, o que poderia agravar o desempenho. Essas escolhas, embora necessárias para o controle experimental, significam que as lacunas de confiabilidade observadas na prática são provavelmente ainda maiores do que as relatadas.
Eles concluem:
Acreditamos que as simulações realizadas representam um terreno de teste benigno para as capacidades de múltiplos turnos dos LLMs. Devido às condições excessivamente simplificadas da simulação, acreditamos que a degradação observada nos experimentos é, na verdade, um subestimar da ineficácia dos LLMs, e de como frequentemente se perdem em conversa em configurações do mundo real.‘
Conclusão
Qualquer um que tenha passado um tempo considerável com um LLM provavelmente reconhecerá as questões formuladas aqui, a partir da experiência prática; e a maioria de nós, imagino, abandonou intuitivamente conversas ‘perdidas’ com LLMs em favor de novas, na esperança de que o LLM possa ‘começar de novo’ e deixar de se fixar em material que surgiu em uma troca longa, sinuosa e cada vez mais frustrante.
É interessante notar que oferecer mais contexto ao problema pode não resolver necessariamente; e, de fato, observar que o artigo levanta mais perguntas do que fornece respostas (exceto em termos de maneiras de contornar o problema).
* Confusamente, isso não está relacionado ao significado convencional de ‘sharding’ em IA.
† Ênfases em negrito dos autores.
Publicado pela primeira vez na segunda-feira, 12 de maio de 2025

Conteúdo relacionado

De silício à sentiência: O legado que guia a próxima fronteira da IA e a migração cognitiva humana.
[the_ad id="145565"] Assine nossas newsletters diárias e semanais para obter as últimas atualizações e conteúdos exclusivos sobre a cobertura de IA líder do setor. Saiba mais……

Os modelos Gemma AI do Google ultrapassam 150 milhões de downloads.
[the_ad id="145565"] A coleção de modelos de IA Gemma, gratuitamente disponível do Google, alcançou um marco importante: mais de 150 milhões de downloads. Omar Sanseviero,…

O projeto Stargate da OpenAI enfrenta dificuldades para decolar, devido às tarifas.
[the_ad id="145565"] O ambicioso projeto de data center Stargate da OpenAI enfrenta atrasos devido à incerteza econômica relacionada a tarifas, segundo a Bloomberg. A crescente…