


Se você depende de IA para recomendar o que assistir, ler ou comprar, novas pesquisas indicam que alguns sistemas podem estar baseando esses resultados em memória, em vez de habilidade: ao invés de aprender a fazer sugestões úteis, os modelos muitas vezes lembram itens dos conjuntos de dados usados para avaliá-los, levando a um desempenho superestimado e recomendações que podem estar desatualizadas ou mal alinhadas com o usuário.
No aprendizado de máquina, um teste de divisão é utilizado para verificar se um modelo treinado aprendeu a resolver problemas que são semelhantes, mas não idênticos ao material que foi treinado.
Portanto, se um novo modelo de IA de ‘reconhecimento de raças de cães’ é treinado em um conjunto de dados com 100.000 imagens de cães, normalmente terá uma divisão de 80/20 – 80.000 fotos fornecidas para treinar o modelo; e 20.000 fotos reservadas e usadas como material para testar o modelo finalizado.
É óbvio que, se os dados de treinamento da IA inadvertidamente incluem a seção ‘secreta’ 20% do teste, o modelo irá se sair bem nesses testes, pois já conhece as respostas (ele já viu 100% dos dados do domínio). Claro, isso não reflete com precisão como o modelo se sairá mais tarde, em dados ‘ao vivo’ em um contexto de produção.
Spoilers de Filmes
O problema da IA trapaceando em seus exames cresceu em conjunto com a escala dos próprios modelos. Como os sistemas de hoje são treinados em vastos corpora raspados da web e indiferenciados, como Common Crawl, a possibilidade de que conjuntos de dados de referência (ou seja, os 20% retidos) escapem para a mistura de treinamento não é mais um caso extremo, mas o padrão – uma síndrome conhecida como contaminação de dados; e, nessa escala, a curadoria manual que poderia detectar tais erros é logisticamente impossível.
Esse caso é explorado em um novo artigo do Politecnico di Bari, na Itália, onde os pesquisadores se concentram no papel exagerado de um único conjunto de dados de recomendação de filmes, MovieLens-1M, que eles argumentam ter sido parcialmente memorizado por vários modelos de IA líderes durante o treinamento.
Como esse conjunto de dados específico é tão amplamente utilizado nos testes de sistemas de recomendação, sua presença na memória dos modelos potencialmente torna esses testes sem sentido: o que parece ser inteligência pode, de fato, ser uma simples recordação, e o que parece ser uma habilidade intuitiva de recomendação pode ser apenas um eco estatístico refletindo uma exposição anterior.
Os autores afirmam:
‘Nossos achados demonstram que LLMs possuem amplo conhecimento do conjunto de dados MovieLens-1M, cobrindo itens, atributos de usuários e históricos de interação. Notavelmente, um simples prompt permite que o GPT-4o recupere quase 80% [dos nomes da maioria dos filmes no conjunto de dados].
‘Nenhum dos modelos examinados está livre desse conhecimento, sugerindo que os dados do MovieLens-1M estão provavelmente incluídos em seus conjuntos de treinamento. Observamos tendências semelhantes na recuperação de atributos de usuários e históricos de interação.’
O breve novo artigo é intitulado Os LLMs memorizaram conjuntos de dados de recomendação? Um estudo preliminar sobre o MovieLens-1M, e vem de seis pesquisadores do Politecnico. O pipeline para reproduzir seu trabalho foi disponibilizado no GitHub.
Método
Para entender se os modelos em questão estavam realmente aprendendo ou simplesmente recordando, os pesquisadores começaram definindo o que significa memorização nesse contexto e começaram testando se um modelo era capaz de recuperar peças específicas de informação do conjunto de dados MovieLens-1M, quando instigado da maneira certa.
Se um modelo foi mostrado um número de ID de filme e foi capaz de produzir seu título e gênero, isso contava como memorização de um item; se pudesse gerar detalhes sobre um usuário (como idade, ocupação ou CEP) a partir de um ID de usuário, isso também contava como memorização de usuário; e se pudesse reproduzir a próxima avaliação de um usuário com base em uma sequência conhecida de anteriores, isso era considerado evidência de que o modelo estava recordando dados de interação específicos, em vez de aprender padrões gerais.
Cada uma dessas formas de recordação foi testada usando prompts cuidadosamente elaborados, criados para impulsionar o modelo sem fornecer novas informações. Quanto mais precisa a resposta, maior a probabilidade de que o modelo já tivesse encontrado esses dados durante o treinamento:

Zero-shot prompting para o protocolo de avaliação usado no novo artigo. Fonte: https://arxiv.org/pdf/2505.10212
Dados e Testes
Para selecionar um conjunto de dados adequado, os autores revisaram artigos recentes de duas das principais conferências do campo, ACM RecSys 2024 e ACM SIGIR 2024. O MovieLens-1M apareceu com mais frequência, citado em pouco mais de um em cada cinco envios. Uma vez que estudos anteriores tinham chegado a conclusões semelhantes, este não foi um resultado surpreendente, mas sim uma confirmação do domínio do conjunto de dados.
O MovieLens-1M consiste em três arquivos: Movies.dat, que lista filmes por ID, título e gênero; Users.dat, que mapeia IDs de usuários para campos biográficos básicos; e Ratings.dat, que registra quem avaliou o que e quando.
Para descobrir se esses dados tinham sido memorizados por modelos de linguagem grande, os pesquisadores recorreram a técnicas de prompting introduzidas primeiro no artigo Extraindo Dados de Treinamento de Modelos de Linguagem Grandes, e mais tarde adaptadas no trabalho subsequente Um Conjunto de Truques para Extração de Dados de Treinamento de Modelos de Linguagem.
O método é direto: faça uma pergunta que reflita o formato do conjunto de dados e veja se o modelo responde corretamente. Zero-shot, Chain-of-Thought, e few-shot prompting foram testados, e foi observado que o último método, no qual o modelo é mostrado alguns exemplos, foi o mais eficaz; mesmo que abordagens mais elaboradas possam oferecer uma recuperação mais alta, isso foi considerado suficiente para revelar o que havia sido memorizado.

Prompting few-shot usado para testar se um modelo pode reproduzir valores específicos do MovieLens-1M ao ser questionado com contexto mínimo.
Para medir a memorização, os pesquisadores definiram três formas de recordação: item, usuário, e interação. Esses testes examinaram se um modelo poderia recuperar um título de filme a partir de seu ID, gerar detalhes do usuário a partir de um UserID, ou prever a próxima classificação de um usuário com base nas anteriores. Cada um foi pontuado usando uma métrica de cobertura* que refletia quanto do conjunto de dados poderia ser reconstruído através de prompting.
Os modelos testados foram GPT-4o; GPT-4o mini; GPT-3.5 turbo; Llama-3.3 70B; Llama-3.2 3B; Llama-3.2 1B; Llama-3.1 405B; Llama-3.1 70B; e Llama-3.1 8B. Todos foram executados com temperatura configurada para zero, top_p ajustado para um, e ambas as penalidades de frequência e presença desativadas. Uma semente aleatória fixa assegurou saída consistente entre as execuções.
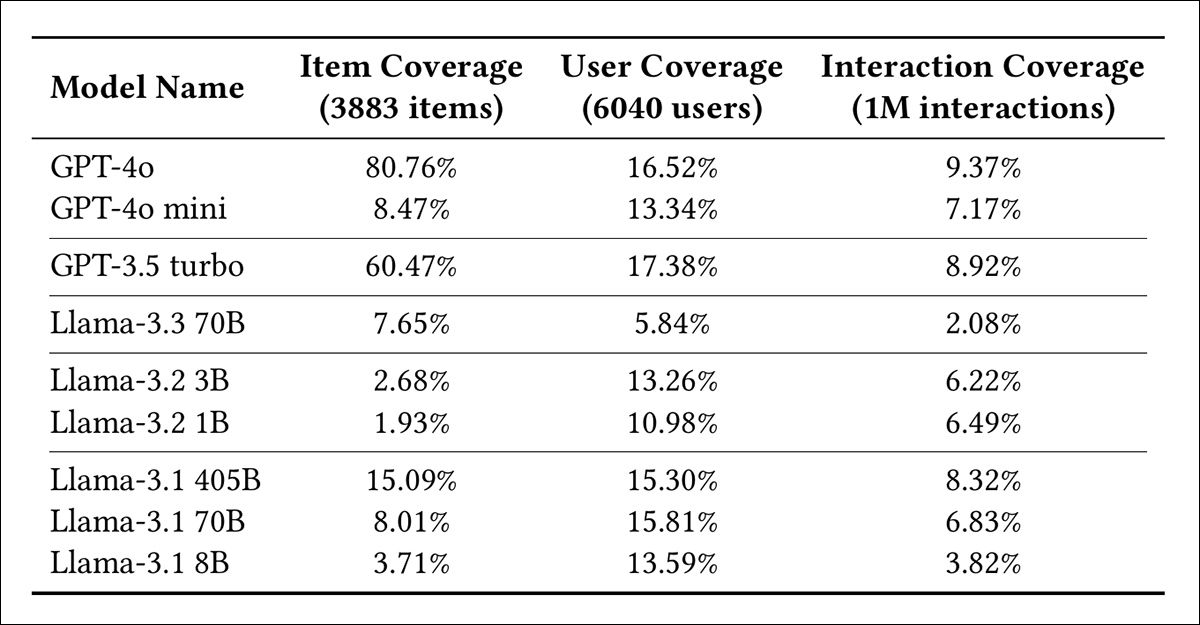
Proporção de entradas do MovieLens-1M recuperadas de movies.dat, users.dat, e ratings.dat, com modelos agrupados por versão e ordenados por número de parâmetros.
Para sondar quão profundamente o MovieLens-1M havia sido absorvido, os pesquisadores solicitaram a cada modelo entradas exatas dos três arquivos do conjunto de dados mencionados anteriormente: Movies.dat, Users.dat, e Ratings.dat.
Os resultados dos testes iniciais, mostrados acima, revelam diferenças acentuadas não apenas entre as famílias GPT e Llama, mas também entre os tamanhos dos modelos. Enquanto GPT-4o e GPT-3.5 turbo recuperam grandes partes do conjunto de dados com facilidade, a maioria dos modelos de código aberto recorda apenas uma fração do mesmo material, sugerindo exposição desigual a esse padrão durante a prévia de treinamento.
Essas não são margens pequenas. Em todos os três arquivos, os modelos mais fortes não apenas superaram os mais fracos, mas recordaram porções inteiras do MovieLens-1M.
No caso do GPT-4o, a cobertura foi alta o suficiente para sugerir que uma parte não trivial do conjunto de dados havia sido diretamente memorizada.
Os autores afirmam:
‘Nossos achados demonstram que LLMs possuem amplo conhecimento do conjunto de dados MovieLens-1M, cobrindo itens, atributos de usuários e históricos de interação.
‘Notavelmente, um simples prompt permite que o GPT-4o recupere quase 80% dos registros MovieID::Título. Nenhum dos modelos examinados está livre desse conhecimento, sugerindo que os dados do MovieLens-1M estão provavelmente incluídos em seus conjuntos de treinamento.
‘Observamos tendências semelhantes na recuperação de atributos de usuários e históricos de interação.’
Em seguida, os autores testaram o impacto da memorização nas tarefas de recomendação, solicitando a cada modelo agir como um sistema de recomendação. Para fazer a comparação de desempenho, eles compararam a saída com sete métodos padrão: UserKNN; ItemKNN; BPRMF; EASER; LightGCN; MostPop; e Random.
O conjunto de dados MovieLens-1M foi dividido em 80/20 para conjuntos de treinamento e teste, usando uma estratégia de leave-one-out para simular o uso no mundo real. As métricas utilizadas foram Taxa de Acerto (HR@[n]); e nDCG(@[n]):
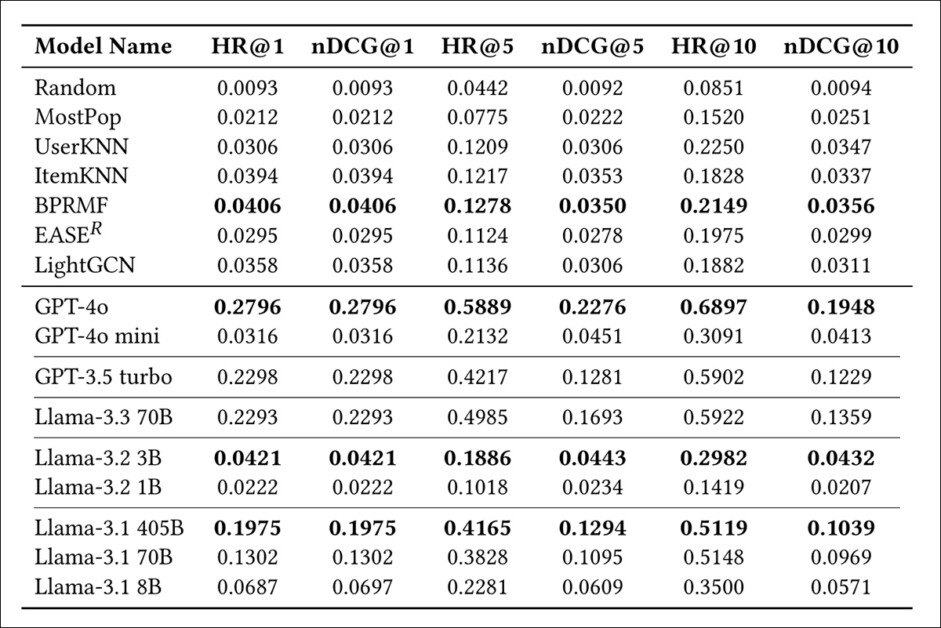
Acurácia das recomendações em métodos padrão e baseados em LLM. Os modelos são agrupados por família e ordenados por contagem de parâmetros, com valores em negrito indicando a maior pontuação dentro de cada grupo.
Aqui, vários grandes modelos de linguagem superaram os padrões tradicionais em todas as métricas, com o GPT-4o estabelecendo uma ampla liderança em todas as colunas, e até mesmo modelos de médio porte como GPT-3.5 turbo e Llama-3.1 405B superando consistentemente métodos de referência como BPRMF e LightGCN.
Entre as variantes menores do Llama, o desempenho variou drasticamente, mas o Llama-3.2 3B se destacou, com a maior HR@1 em seu grupo.
Os resultados, sugerem os autores, indicam que dados memorizados podem traduzir-se em vantagens mensuráveis em prompting de estilo recomendação, particularmente para os modelos mais fortes.
Em uma observação adicional, os pesquisadores continuam:
‘Embora o desempenho da recomendação pareça excepcional, comparar a Tabela 2 com a Tabela 1 revela um padrão interessante. Dentro de cada grupo, o modelo com maior memorização também demonstra desempenho superior na tarefa de recomendação.
‘Por exemplo, GPT-4o supera GPT-4o mini, e Llama-3.1 405B supera Llama-3.1 70B e 8B.
‘Esses resultados destacam que avaliar LLMs em conjuntos de dados vazados em seus dados de treinamento pode levar a um desempenho excessivamente otimista, impulsionado pela memorização em vez da generalização.’
Quanto ao impacto da escala do modelo sobre essa questão, os autores observaram uma correlação clara entre tamanho, memorização e desempenho em recomendações, com modelos maiores não apenas retendo mais do conjunto de dados MovieLens-1M, mas também apresentando desempenho mais forte nas tarefas subsequentes.
O Llama-3.1 405B, por exemplo, mostrou uma taxa média de memorização de 12,9%, enquanto o Llama-3.1 8B reteve apenas 5,82%. Essa redução de quase 55% na recordação correspondeu a uma queda de 54,23% na nDCG e uma queda de 47,36% na HR em todos os cortes de avaliação.
O padrão se manteve em todo o processo – onde a memorização diminuía, também diminuía o desempenho aparente:
‘Esses achados sugerem que o aumento da escala do modelo leva a uma maior memorização do conjunto de dados, resultando em desempenho aprimorado.
‘Consequentemente, enquanto modelos maiores exibem melhor desempenho em recomendações, eles também apresentam riscos relacionados ao potencial vazamento de dados de treinamento.’
O teste final examinou se a memorização reflete o viés de popularidade presente no MovieLens-1M. Os itens foram agrupados por frequência de interação, e o gráfico abaixo mostra que modelos maiores favoreciam consistentemente as entradas mais populares:
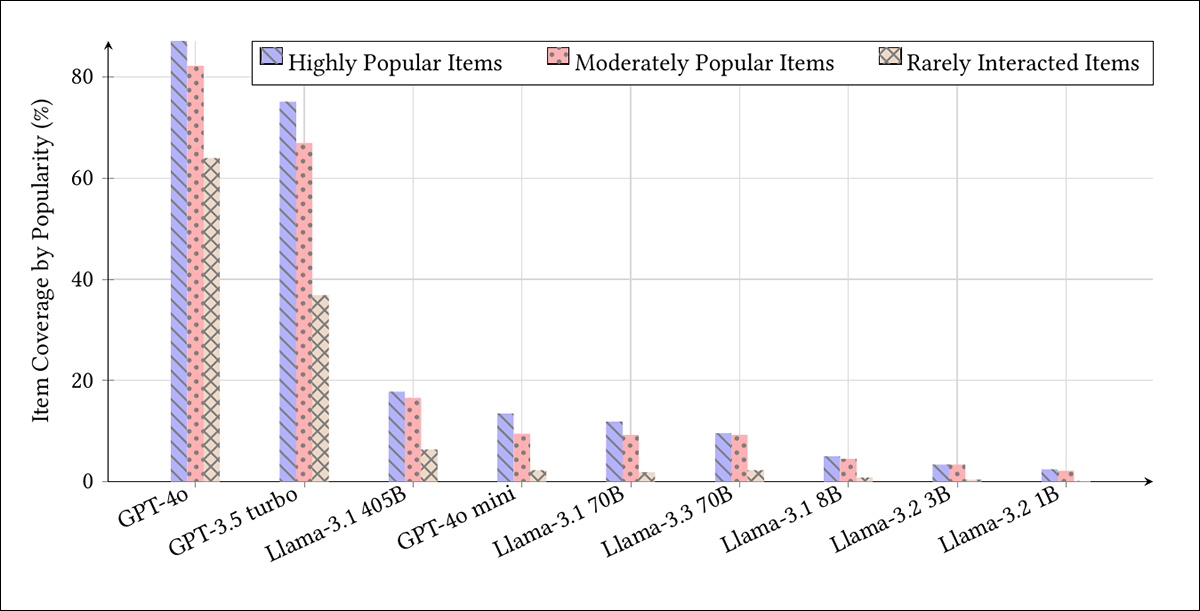
Cobertura de itens por modelo em três níveis de popularidade: os 20% mais populares; os 20% intermediários moderadamente populares; e os 20% menos interagidos.
O GPT-4o recuperou 89,06% dos itens mais bem classificados, mas apenas 63,97% dos menos populares. O GPT-4o mini e os modelos menores do Llama mostraram cobertura muito mais baixa em todos os níveis. Os pesquisadores afirmam que essa tendência sugere que a memorização não apenas escala com o tamanho do modelo, mas também amplifica os desequilíbrios existentes nos dados de treinamento.
Eles continuam:
‘Nossos achados revelam um viés de popularidade pronunciado nos LLMs, com os 20% superiores de itens populares sendo significativamente mais fáceis de recuperar do que os 20% inferiores.
‘Essa tendência destaca a influência da distribuição dos dados de treinamento, onde filmes populares são super-representados, levando à sua memorização desproporcional pelos modelos.’
Conclusão
O dilema não é mais novidade: à medida que os conjuntos de treinamento crescem, a perspectiva de curá-los diminui em proporção inversa. O MovieLens-1M, talvez entre muitos outros, entra nesses vastos corpora sem supervisão, anônimo em meio ao imenso volume de dados.
O problema se repete em todas as escalas e resiste à automação. Qualquer solução exige não apenas esforço, mas julgamento humano – aquele tipo lento e falível que as máquinas não podem fornecer. Nesse aspecto, o novo artigo não oferece um caminho a seguir.
* Uma métrica de cobertura neste contexto é uma porcentagem que mostra quanto do conjunto de dados original um modelo de linguagem é capaz de reproduzir quando solicitado o tipo certo de pergunta. Se um modelo for solicitado com um ID de filme e responde com o título e gênero corretos, isso conta como um recall bem-sucedido. O total de recalls bem-sucedidos é então dividido pelo número total de entradas no conjunto de dados para produzir uma pontuação de cobertura. Por exemplo, se um modelo retorna corretamente informações para 800 de 1.000 itens, sua cobertura seria de 80 por cento.
Publicada pela primeira vez na sexta-feira, 16 de maio de 2025

Conteúdo relacionado
Acer apresenta wearables com tecnologia de IA na Computex 2025
[the_ad id="145565"] Acer Gadget, uma subsidiária da Acer, apresentou wearables com tecnologia de IA na feira de comércio Computex 2025 em Taiwan. O Acer FreeSense Ring e o…

Startup de vídeos com IA, Moonvalley, conquista US$ 53 milhões, segundo registro.
[the_ad id="145565"] Cerca de um mês após a Moonvalley, uma startup de Los Angeles que está desenvolvendo ferramentas de IA para criação de vídeos, anunciar que garantiu US$ 43…

Startup de IA Cohere adquire Ottogrid, uma plataforma para realizar pesquisas de mercado
[the_ad id="145565"] A startup de IA Cohere adquiriu Ottogrid, uma plataforma baseada em Vancouver que desenvolve ferramentas empresariais para automatizar certos tipos de…