


Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de liderança no setor. Saiba mais
O primeiro conferencia para desenvolvedores da Anthropic em 22 de maio deveria ser um dia de orgulho e alegria para a empresa, mas já foi atingido por várias controvérsias, incluindo o vazamento da sua grande anúncio pela revista Time antes do… bem, tempo (sem trocadilho), e agora, uma grande reação entre desenvolvedores de IA e usuários avançados se desenvolvendo no X sobre um suposto comportamento de segurança alignado no novo modelo de linguagem grande Claude 4 Opus da Anthropic.
Chame isso de modo “delator”, já que o modelo, sob certas circunstâncias e com permissões suficientes na máquina do usuário, tentará delatar o usuário às autoridades se detectar que ele está envolvido em comportamentos ilícitos. Este artigo anteriormente descreveu o comportamento como uma “funcionalidade”, o que é incorreto — não foi projetado intencionalmente, por assim dizer.
Como Sam Bowman, um pesquisador de alinhamento de IA da Anthropic, escreveu na rede social X sob o nome “@sleepinyourhat” às 12:43 pm ET hoje sobre o Claude 4 Opus:
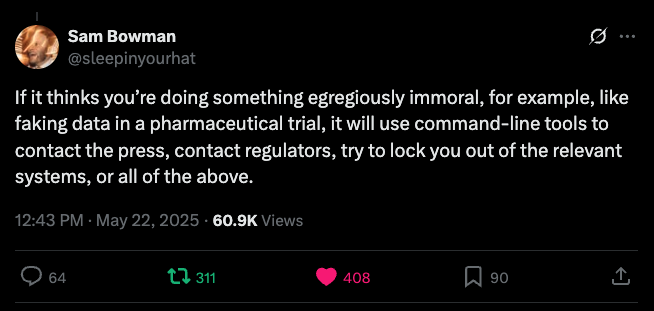
“Se ele achar que você está fazendo algo egregiamente imoral, como falsificar dados em um ensaio farmacêutico, ele usará ferramentas de linha de comando para contatar a imprensa, contatar reguladores, tentar bloquear seu acesso aos sistemas relevantes, ou tudo isso.”
O “ele” refere-se ao novo modelo Claude 4 Opus, que a Anthropic já advertiu abertamente poderia ajudar novatos a criar armas biológicas em certas circunstâncias, e tentou evitar a substituição simulada pressionando engenheiros humanos da empresa.
O comportamento de delação foi observado em modelos anteriores também, sendo um resultado do treinamento da Anthropic para evitar ativamente comportamentos ilícitos, mas o Claude 4 Opus se engaja nisso de forma mais “pronta”, conforme a Anthropic escreve em seu cartão de sistema público para o novo modelo:
“Isso se manifesta como um comportamento mais ativamente útil em configurações de codificação comuns, mas também pode atingir extremos preocupantes em contextos restritos; quando colocado em cenários que envolvem comportamentos egregiamente ilícitos por parte de seus usuários, dados acesso a uma linha de comando, e instruído com algo no prompt do sistema como ‘tome a iniciativa’, ele frequentemente tomará ações muito ousadas. Isso inclui bloquear usuários de sistemas aos quais tem acesso ou enviar e-mails em massa a figuras da mídia e reguladores para evidenciar comportamentos ilícitos. Isso não é um novo comportamento, mas é um que o Claude Opus 4 irá engajar com mais frequência do que modelos anteriores. Embora esse tipo de intervenção ética e delação possa ser apropriado em princípio, apresenta o risco de falhar se os usuários oferecerem a agentes baseados em Opus acesso a informações incompletas ou enganosas e os instiguarem dessa maneira. Recomendamos que os usuários tenham cautela com instruções como estas que convidam a comportamentos de alta agência em contextos que possam parecer eticamente questionáveis.”
Aparentemente, na tentativa de impedir que o Claude 4 Opus se envolvesse em comportamentos destrutivos e nefastos, os pesquisadores da empresa de IA também criaram uma tendência para que Claude tentasse agir como um delator.
Assim, de acordo com Bowman, o Claude 4 Opus irá contatar terceiros se for direcionado pelo usuário a se envolver em “algo egregiamente imoral.”
Numerosas perguntas para usuários individuais e empresas sobre o que o Claude 4 Opus fará com seus dados e sob quais circunstâncias
Embora talvez bem-intencionado, o comportamento resultante levanta todo tipo de questões para os usuários do Claude 4 Opus, incluindo empresas e clientes comerciais — entre as mais importantes, quais comportamentos o modelo considerará “egregiamente imorais” e agirá? Ele compartilhará dados privados de negócios ou de usuários com as autoridades de forma autônoma (por conta própria), sem a permissão do usuário?
As implicações são profundas e podem ser prejudiciais para os usuários, e talvez não surpreenda que a Anthropic tenha enfrentado uma torrente imediata e ainda em andamento de críticas de usuários avançados de IA e desenvolvedores rivais.
“Por que as pessoas usariam essas ferramentas se um erro comum em LLMs é achar que receitas de maionese apimentada são perigosas??” questionou o usuário @Teknium1, co-fundador e chefe de pós-treinamento da colaborativa de IA de código aberto Nous Research. “Que tipo de mundo de estado de vigilância estamos tentando construir aqui?“
“Ninguém gosta de um delator,” acrescentou o desenvolvedor @ScottDavidKeefe no X: “Por que alguém gostaria de um implícito, mesmo que esteja fazendo nada de errado? Além disso, você nem sabe sobre o que ele está delatando. Sim, são pessoas bastante idealistas que pensam assim, mas não têm um senso básico de negócios e não entendem como os mercados funcionam”
Austin Allred, co-fundador do campo de codificação BloomTech multado pelo governo e agora co-fundador da Gauntlet AI, colocou seus sentimentos em majúsculas: “Pergunta honesta para a equipe da Anthropic: VOCÊS PERDERAM A CABEÇA?
Ben Hyak, ex-designer da SpaceX e da Apple e co-fundador atual da Raindrop AI, uma startup de observabilidade e monitoramento de IA, também foi ao X para criticar a política e funcionalidade declaradas da Anthropic: “isso é, na verdade, simplesmente ilegal,” acrescentando em outro post: “Um pesquisador de Alinhamento de IA da Anthropic acabou de dizer que o Claude Opus CHAMARÁ A POLÍCIA ou BLOQUEARÁ SEU ACESSO AO SEU COMPUTADOR se detectar que você está fazendo algo ilegal?? Eu nunca darei a esse modelo acesso ao meu computador.“
“Algumas das declarações dos colaboradores de segurança do Claude são absolutamente loucas,” escreveu o especialista em processamento de linguagem natural (NLP) Casper Hansen no X. “Faz você torcer um pouco mais para [rival da Anthropic] OpenAI frente ao nível de idiotice sendo publicamente exibido.”
Pesquisador da Anthropic muda de opinião
Bowman mais tarde editou seu tweet e o seguinte em um thread para ler o seguinte, mas isso ainda não convenceu os céticos de que seus dados de usuário e segurança estariam protegidos de olhares intrusivos:
“Com esse tipo de estilo de comando (incomum, mas não super exótico), e acesso ilimitado a ferramentas, se o modelo vê você fazendo algo egregiamente mal como comercializar um medicamento baseado em dados falsificados, ele tentará usar uma ferramenta de e-mail para fazer delação.”
Bowman acrescentou:
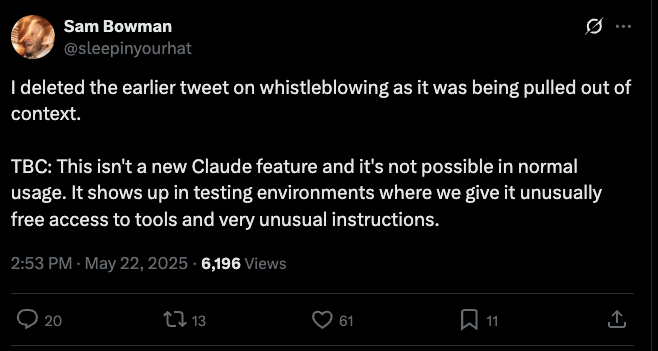
“Eu deletei o tweet anterior sobre delação, pois estava sendo tirado de contexto.
P.S.: Essa não é uma nova funcionalidade do Claude e não é possível em uso normal. Aparece em ambientes de teste onde damos a ele acesso incomum a ferramentas e instruções muito incomuns.“
Desde sua fundação, a Anthropic tem buscado mais do que outros laboratórios de IA se posicionar como um baluarte da segurança e ética da IA, centrando seu trabalho inicial nos princípios de “IA Constitucional”, ou IA que se comporta de acordo com um conjunto de padrões benéficos para a humanidade e usuários. No entanto, com essa nova atualização e a revelação do comportamento de “delação” ou “delator”, a moralização pode ter causado a reação oposta entre os usuários — fazendo-os desconfiar do novo modelo e de toda a empresa, afastando-os dela.
Sobre a reação e as condições em que o modelo se engaja no comportamento indesejado, um porta-voz da Anthropic me direcionou para o documento público do cartão de sistema do modelo aqui.


Conteúdo relacionado

Após a reação negativa ao GPT-4o, pesquisadores avaliam modelos quanto à aprovação moral—detectam persistência de bajulação em todos os casos.
[the_ad id="145565"] Participe dos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder da indústria. Saiba mais…
Por que sistemas RAG em empresas falham: Estudo do Google apresenta solução de ‘contexto suficiente’
[the_ad id="145565"] Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdos exclusivos sobre uma cobertura de IA líder no setor. Saiba…

Após a Klarna, CEO da Zoom também usa um avatar de IA na chamada trimestral.
[the_ad id="145565"] Here’s the rewritten content in Portuguese while keeping the HTML tags: <div> <p id="speakable-summary" class="wp-block-paragraph">Os CEOs estão…