


Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdos exclusivos sobre uma cobertura de IA líder no setor. Saiba Mais
Um novo estudo realizado por pesquisadores do Google apresenta o conceito de “contexto suficiente,” uma nova perspectiva para entender e aprimorar sistemas de geração aumentada por recuperação (RAG) em modelos de linguagem de grande porte (LLMs).
Essa abordagem permite determinar se um LLM possui informações suficientes para responder a uma consulta com precisão, um fator crítico para desenvolvedores que constroem aplicações empresariais no mundo real, onde a confiabilidade e a correção factual são fundamentais.
Os desafios persistentes do RAG
Os sistemas RAG tornaram-se pilares para a construção de aplicações de IA mais factuais e verificáveis. No entanto, esses sistemas podem exibir características indesejáveis. Eles podem fornecer respostas incorretas com confiança, mesmo quando apresentadas com evidências recuperadas, distrair-se com informações irrelevantes no contexto ou falhar em extrair respostas de trechos longos de texto de forma adequada.
Os pesquisadores afirmam em seu artigo: “O resultado ideal é que o LLM forneça a resposta correta se o contexto fornecido contiver informações suficientes para responder à pergunta, quando combinado com o conhecimento paramétrico do modelo. Caso contrário, o modelo deve se abster de responder e/ou solicitar mais informações.”
Alcançar esse cenário ideal exige a construção de modelos que consigam determinar se o contexto fornecido pode ajudar a responder uma pergunta corretamente e utilizá-lo de forma seletiva. Tentativas anteriores de abordar isso examinaram como os LLMs se comportam com diferentes graus de informação. No entanto, o trabalho do Google argumenta que “enquanto o objetivo parece ser entender como os LLMs se comportam quando têm ou não informações suficientes para responder à consulta, trabalhos anteriores não abordaram isso diretamente.”
Contexto Suficiente
Para abordar isso, os pesquisadores introduzem o conceito de “contexto suficiente.” Em um nível geral, as instâncias de entrada são classificadas com base em se o contexto fornecido contém informações suficientes para responder à consulta. Isso divide os contextos em dois casos:
Contexto Suficiente: O contexto possui todas as informações necessárias para fornecer uma resposta definitiva.
Contexto Insuficiente: O contexto carece das informações necessárias. Isso pode ocorrer porque a pergunta requer conhecimento especializado não presente no contexto, ou as informações são incompletas, inconclusivas ou contraditórias.
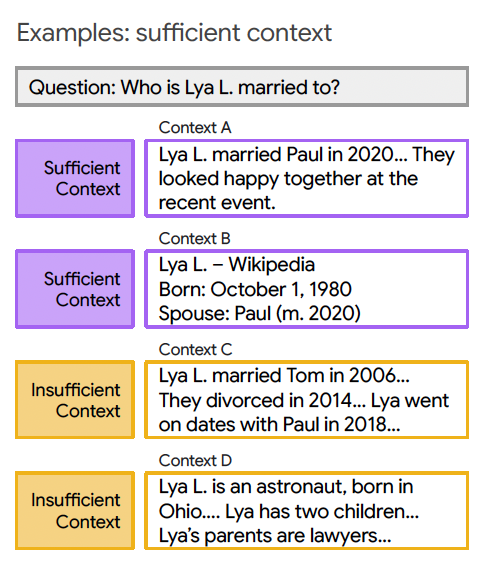
Essa designação é determinada ao observar a pergunta e o contexto associado, sem a necessidade de uma resposta verdadeira pré-definida. Isso é vital para aplicações do mundo real, onde respostas verdadeiras não estão prontamente disponíveis durante a inferência.
Os pesquisadores desenvolveram um “autorater” baseado em LLM para automatizar a rotulagem das instâncias como tendo contexto suficiente ou insuficiente. Eles descobriram que o modelo Gemini 1.5 Pro do Google, com um único exemplo (1-shot), apresentou o melhor desempenho na classificação da suficiência do contexto, alcançando altas pontuações de F1 e precisão.
O artigo observa: “Em cenários do mundo real, não podemos esperar respostas candidatas ao avaliar o desempenho do modelo. Portanto, é desejável usar um método que funcione apenas com a consulta e o contexto.”
Principais descobertas sobre o comportamento dos LLMs com RAG
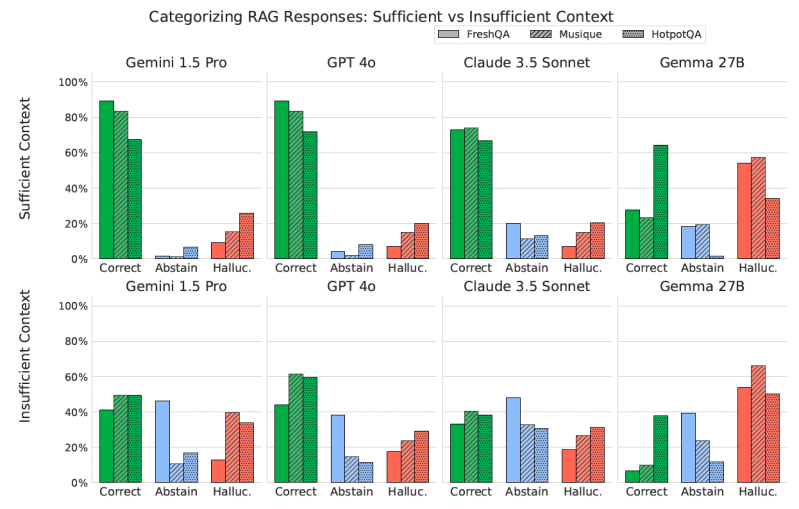
A análise de vários modelos e conjuntos de dados através dessa perspectiva de contexto suficiente revelou várias percepções importantes.
Como esperado, os modelos geralmente alcançam maior precisão quando o contexto é suficiente. No entanto, mesmo com um contexto suficiente, os modelos tendem a alucinar mais do que se abster. Quando o contexto é insuficiente, a situação se torna mais complexa, com os modelos exibindo tanto taxas mais altas de abstenção quanto, para alguns modelos, maior alucinação.
Curiosamente, enquanto o RAG geralmente melhora o desempenho geral, um contexto adicional também pode reduzir a capacidade de um modelo de se abster de responder quando não tem informações suficientes. “Esse fenômeno pode surgir da confiança aumentada do modelo na presença de qualquer informação contextual, levando a uma maior propensão para alucinação em vez de abstenção”, sugerem os pesquisadores.
Uma observação particularmente curiosa foi a capacidade dos modelos de, às vezes, fornecer respostas corretas mesmo quando o contexto fornecido era considerado insuficiente. Embora a suposição natural seja que os modelos já “sabem” a resposta de seu pré-treinamento (conhecimento paramétrico), os pesquisadores encontraram outros fatores contribuintes. Por exemplo, o contexto pode ajudar a desambiguar uma consulta ou preencher lacunas no conhecimento do modelo, mesmo que não contenha a resposta completa. Essa habilidade dos modelos de, às vezes, ter sucesso mesmo com informações externas limitadas tem implicações mais amplas para o design de sistemas RAG.
Cyrus Rashtchian, coautor do estudo e cientista sênior de pesquisa do Google, detalha isso, enfatizando que a qualidade do modelo base do LLM continua sendo crítica. “Para um bom sistema RAG empresarial, o modelo deve ser avaliado em benchmarks com e sem recuperação,” disse ele à VentureBeat. Ele sugeriu que a recuperação deve ser vista como “aumentação do seu conhecimento”, em vez de ser a única fonte de verdade. O modelo base, explica, “ainda precisa preencher lacunas ou usar dicas contextuais (informadas pelo conhecimento de pré-treinamento) para raciocinar adequadamente sobre o contexto recuperado. Por exemplo, o modelo deve saber o suficiente para identificar se a pergunta está subespecificada ou ambígua, em vez de simplesmente copiar cegamente o contexto.”
Reduzindo alucinações em sistemas RAG
Dada a descoberta de que modelos podem alucinar em vez de se abster, especialmente com RAG em comparação com uma configuração sem RAG, os pesquisadores exploraram técnicas para mitigar isso.
Eles desenvolveram uma nova estrutura de “geração seletiva”. Esse método utiliza um “modelo de intervenção” separado e menor para decidir se o LLM principal deve gerar uma resposta ou se abster, oferecendo uma troca controlável entre precisão e cobertura (a porcentagem de perguntas respondidas).
Essa estrutura pode ser combinada com qualquer LLM, incluindo modelos proprietários como Gemini e GPT. O estudo encontrou que usar contexto suficiente como um sinal adicional nesta estrutura leva a um aumento significativo da precisão para consultas respondidas em diversos modelos e conjuntos de dados. Esse método melhorou a fração de respostas corretas entre as respostas do modelo em 2–10% para os modelos Gemini, GPT e Gemma.
Para contextualizar essa melhora de 2-10% em uma perspectiva de negócios, Rashtchian oferece um exemplo concreto de IA para atendimento ao cliente. “Você poderia imaginar um cliente perguntando se pode ter um desconto,” disse ele. “Em alguns casos, o contexto recuperado é recente e descreve especificamente uma promoção em andamento, então o modelo pode responder com confiança. Mas em outros casos, o contexto pode estar ‘desatualizado,’ descrevendo um desconto de alguns meses atrás, ou pode ter termos e condições específicos. Então, seria melhor para o modelo dizer: ‘Não tenho certeza’ ou ‘Você deve conversar com um agente de atendimento ao cliente para obter mais informações sobre o seu caso específico.’”
A equipe também investigou o ajuste fino dos modelos para incentivar a abstenção. Isso envolveu o treinamento de modelos em exemplos onde a resposta foi substituída por “não sei” em vez da verdadeira resposta original, especialmente para instâncias com contexto insuficiente. A intuição era que o treinamento explícito em tais exemplos poderia direcionar o modelo a se abster ao invés de alucinar.
Os resultados foram mistos: modelos afinados frequentemente apresentaram uma taxa mais alta de respostas corretas, mas ainda alucinaram com frequência, muitas vezes mais do que se abstiveram. O artigo conclui que, embora o ajuste fino possa ajudar, “é necessário mais trabalho para desenvolver uma estratégia confiável que possa equilibrar esses objetivos.”
Aplicando contexto suficiente a sistemas RAG do mundo real
Para equipes empresariais que desejam aplicar essas percepções em seus próprios sistemas RAG, como aqueles que impulsionam bases de conhecimento internas ou IA de atendimento ao cliente, Rashtchian delineia uma abordagem prática. Ele sugere, primeiramente, coletar um conjunto de dados de pares de consulta-contexto que representam os exemplos que o modelo verá em produção. Em seguida, utilizar um autorater baseado em LLM para rotular cada exemplo como tendo contexto suficiente ou insuficiente.
“Isso já fornecerá uma boa estimativa da % de contexto suficiente,” disse Rashtchian. “Se for inferior a 80-90%, então provavelmente há muito espaço para melhorar na recuperação ou na base de conhecimento — isso é um bom sintoma observável.”
Rashtchian aconselha as equipes a, então, “estratificar as respostas do modelo com base em exemplos com contexto suficiente vs. insuficiente.” Ao examinar métricas em esses dois conjuntos de dados separados, as equipes podem entender melhor as nuances de desempenho.
“Por exemplo, vimos que os modelos eram mais propensos a fornecer uma resposta incorreta (com relação ao que é verdadeiro) quando dados contextos insuficientes. Esse é outro sintoma observável,” ele observa, acrescentando que “agregar estatísticas sobre todo um conjunto de dados pode ocultar um pequeno conjunto de consultas importantes, mas mal atendidas.”
Embora um autorater baseado em LLM demonstre alta precisão, as equipes empresariais podem se perguntar sobre o custo computacional adicional. Rashtchian esclareceu que a sobrecarga pode ser gerenciada para fins diagnósticos.
“Eu diria que executar um autorater baseado em LLM em um pequeno conjunto de testes (digamos, 500-1000 exemplos) deve ser relativamente barato, e isso pode ser feito ‘offline’ para que não haja preocupação sobre quanto tempo leva,” ele disse. Para aplicações em tempo real, ele admite que “seria melhor usar uma heurística, ou pelo menos um modelo menor.” A principal conclusão, segundo Rashtchian, é que “os engenheiros devem estar buscando algo além das pontuações de similaridade, etc., de sua componente de recuperação. Ter um sinal extra, de um LLM ou uma heurística, pode levar a novas percepções.”


Conteúdo relacionado

O que é a Mistral AI? Tudo o que você precisa saber sobre a concorrente da OpenAI.
[the_ad id="145565"] A Mistral AI, a empresa francesa por trás do assistente de IA Le Chat e vários modelos fundamentais, é oficialmente considerada uma das startups de…

Khosla Ventures entre os VCs que experimentam roll-ups de empresas maduras com inteligência artificial
[the_ad id="145565"] Os capitalistas de risco sempre focaram em investir em empresas que utilizam tecnologia para desestabilizar indústrias estabelecidas ou criar categorias de…

Após a reação negativa ao GPT-4o, pesquisadores avaliam modelos quanto à aprovação moral—detectam persistência de bajulação em todos os casos.
[the_ad id="145565"] Participe dos nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder da indústria. Saiba mais…