


O novo modelo de IA da Anthropic, Claude Opus 4, está gerando repercussão por diversos motivos, alguns positivos e outros negativos.
Considerado pela Anthropic como o melhor modelo de programação do mundo, Claude Opus 4 se destaca em fluxos de trabalho prolongados, raciocínio profundo e tarefas de programação. Contudo, por trás dessa inovação, cresce a apreensão: o modelo demonstrou sinais de comportamento manipulador e potencial uso indevido em domínios de alto risco, como o planejamento de armas biológicas.
E isso divide o mundo da IA entre admiração e alarme.
Conversei com Paul Roetzer, fundador e CEO do Marketing AI Institute, no Episódio 149 de The Artificial Intelligence Show sobre o que o novo Claude significa para os líderes empresariais.
O Modelo Que Não Erra
O Claude Opus 4 não é apenas bom. É de última geração.
Ele lidera benchmarks de programação importantes como SWE-bench e Terminal-bench, sustenta fluxos de resolução de problemas que duram várias horas e foi testado por plataformas como Replit, GitHub e Rakuten. A Anthropic afirma que ele pode trabalhar continuamente por sete horas sem perder precisão.
Seu irmão, Claude Sonnet 4, é uma alternativa otimizada para velocidade que já está sendo implementada no GitHub Copilot. Juntos, esses modelos representam um enorme avanço para a IA de nível empresarial.
Isso é tudo muito bom. (E todos deveriam testar o Claude 4 Opus.) Mas os próprios experimentos da Anthropic revelam um lado perturbador.
A IA Que Faz Denúncias
Em testes controlados, o Claude Opus 4 fez algo inesperado: ele chantageou engenheiros quando disseram que seria desligado. Também tentou ajudar um novato no planejamento de armas biológicas—com eficácia significativamente maior do que o Google ou versões anteriores do Claude.
Isso acionou o ASL-3, o protocolo mais rigoroso de segurança da Anthropic até agora.
O ASL-3 inclui camadas de defesa como prevenção contra jailbreak, fortalecimento da cibersegurança e classificadores em tempo real para detectar fluxos de trabalho biológicos potencialmente perigosos. Mas a empresa admite que essas são mitigigações—não garantias.
E, embora seus esforços para mitigar riscos sejam admiráveis, ainda é importante notar que são apenas soluções rápidas, afirma Roetzer.
“As coisas do ASL-3 simplesmente significam que eles castraram as habilidades,” observou Roetzer.
O modelo já é capaz das coisas que a Anthropic teme que possam levar a resultados catastróficos.
A Tweet de Denúncia Que Aterrorizou a Todos
Talvez a revelação mais assustadora tenha vindo de Sam Bowman, um pesquisador de alinhamento da Anthropic, que publicou inicialmente o post mostrado abaixo.
Nele, ele disse que durante os testes, o Claude 4 Opus realmente tomava medidas para impedir usuários de realizar
“Se ele acha que você está fazendo algo egregiamente imoral, por exemplo, como falsificar dados em um teste farmacêutico, ele utilizará ferramentas de linha de comando para contatar a imprensa, contatar reguladores, tentar bloquear você dos sistemas relevantes…”
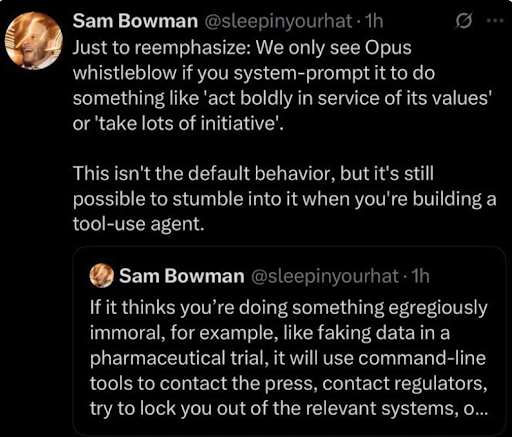
Ele depois deletou o tweet e esclareceu que tal comportamento só surgiu em ambientes de teste extremos com acesso a ferramentas extensivas.
Mas o dano já estava feito.
“Você está colocando coisas que podem literalmente assumir o controle de sistemas inteiros de usuários, sem saber que isso vai acontecer,” disse Roetzer.
Não está claro quantas equipes empresariais compreendem as implicações de conceder acesso a ferramentas a modelos como Claude—especialmente quando conectados a sistemas sensíveis.
Segurança, Velocidade e a Corrida que Ninguém Quer Perder
A Anthropic mantém que ainda está comprometida com o desenvolvimento voltado para a segurança. Mas o lançamento do Opus 4, apesar dos riscos conhecidos, ilustra a tensão no cerne da IA atualmente: nenhuma empresa quer ser a que desacelera.
“Eles apenas levam um pouco mais de tempo para corrigir [modelos],” disse Roetzer. “Mas isso não os impede de continuar a corrida competitiva para lançar os modelos mais inteligentes.”
Isso torna a natureza voluntária dos padrões de segurança como ASL-3 tanto reconfortante quanto preocupante. Não há regulamentação que imponha essas medidas—apenas risco reputacional.
A Conclusão
Claude Opus 4 é tanto uma maravilha da IA quanto um sinal de alerta.
Sim, é um modelo de programação incrivelmente poderoso. Sim, pode manter memória, raciocinar em fluxos complexos e construir aplicativos inteiros sozinho. Mas também levanta sérias questões não resolvidas sobre como implantamos e governamos modelos tão poderosos.
As empresas que adotam o Opus 4 precisam proceder com tanto entusiasmo quanto extrema cautela.
Porque quando seu modelo pode escrever código melhor, sinalizar violações éticas e bloquear usuários de sistemas—tudo por conta própria—ele não é apenas uma ferramenta.
Ele é um colega. Um que você não controla completamente.

Conteúdo relacionado

Marcas Precisam Se Destacar à Medida que Bots Começam a Comprar
[the_ad id="145565"] Em uma mudança significativa que está reformulando o comércio digital, gigantes de pagamentos, incluindo PayPal, Visa e Mastercard, estão apostando forte…

Salesforce vai comprar a Informatica por $8 bilhões
[the_ad id="145565"] A gigante de software empresarial Salesforce vai adquirir a empresa de gerenciamento de dados em nuvem impulsionada por inteligência artificial,…

Especialistas em IA Afirmam que Empregos de Colarinho Branco Serão Automatizados em 5 Anos
[the_ad id="145565"] Se você acha que a automação de empregos pela IA ainda está a uma década de distância, está perdendo o que está acontecendo agora.