


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura líder em IA. Saiba Mais
Pesquisadores da Universidade de Illinois em Urbana-Champaign introduziram o s3, uma estrutura de código aberto projetada para construir sistemas de geração aumentada por recuperação (RAG) de forma mais eficiente que os métodos atuais.
O s3 pode beneficiar desenvolvedores que criam aplicações práticas de grandes modelos de linguagem (LLM), pois simplifica e reduz o custo de criação de modelos de recuperação dentro das arquiteturas RAG.
Recuperação RAG
A eficácia de qualquer sistema RAG depende da qualidade de seu componente de recuperação. No artigo, os pesquisadores classificam a evolução das abordagens RAG em três fases distintas.
- Sistemas de “RAG Clássico” dependem de métodos de recuperação estáticos com consultas fixas, onde a qualidade da recuperação está desconectada do desempenho de geração final. Estas arquiteturas têm dificuldades com consultas que requerem raciocínio contextual ou de múltiplas etapas.
- Uma fase subsequente, chamada de “Pre-RL-Zero”, introduz maior participação do LLM ativo durante a inferência. Essas técnicas envolvem interações de múltiplas turnos, intercalando geração de consultas, recuperação e raciocínio. No entanto, dependem geralmente de prompting zero-shot e carecem de componentes treináveis para otimizar a recuperação através de sinais de resultado direto.
- A fase mais recente, “RL-Zero”, utiliza aprendizado por reforço (RL) para treinar modelos a atuar como agentes de busca, melhorando através de feedback baseado em resultados, como a correção de respostas. Um exemplo é o Search-R1, que treina o modelo para intercalar raciocínio com consultas de busca e contexto recuperado.
Apesar de seus avanços, as abordagens RL-Zero existentes frequentemente otimizam a recuperação utilizando métricas centradas na busca que ignoram a utilidade a montante. Além disso, requerem ajuste fino do LLM, que é custoso e suscetível a erros. Ao entrelaçar recuperação com geração, limitam a verdadeira utilidade de busca e compatibilidade com modelos congelados ou proprietários.
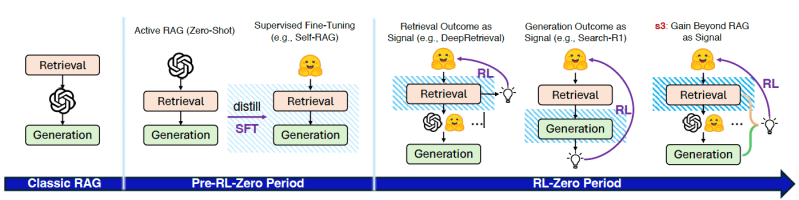
Como os pesquisadores afirmam: “Isso motiva uma mudança para uma estrutura modular onde busca e geração são separadas de forma clara, e a otimização foca puramente na qualidade da busca em relação à utilidade a montante.”
s3
A estrutura s3 aborda este desafio com uma abordagem independente de modelo. A ideia principal é treinar um agente de busca com acesso estruturado e de múltiplos turnos a conhecimentos externos. Este agente de busca melhora a qualidade da fase de recuperação sem afetar o LLM que gera a resposta final.
No s3, um LLM de busca dedicado interage iterativamente com um mecanismo de busca. Ele gera consultas com base no prompt, recupera documentos relevantes, seleciona um subconjunto útil de evidências e decide se deve continuar buscando mais informações. Assim que a busca conclui, um LLM gerador congelado e separado consome essas evidências acumuladas para produzir a resposta final.
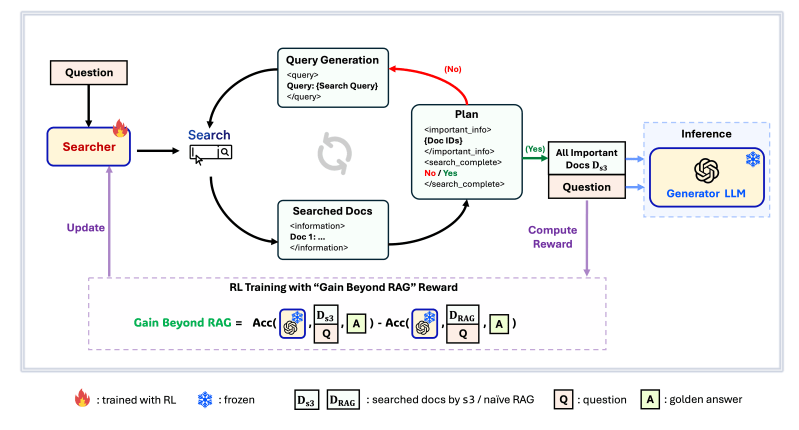
Uma inovação central do s3 é seu sinal de recompensa, Ganho Além do RAG (GBR). O GBR quantifica a melhoria na precisão do gerador quando condicionado a documentos recuperados pelo s3, em comparação com uma linha de base que recupera os principais documentos correspondentes à consulta. Essa recompensa incentiva o buscador a encontrar documentos que realmente melhoram a qualidade de saída do gerador.
“O s3 desacopla o recuperador (buscador) do gerador. Isso permite que empresas integrem qualquer LLM comercial ou proprietário — seja GPT-4, Claude ou um modelo interno — sem precisar ajustá-lo,” disse Patrick (Pengcheng) Jiang, autor principal do artigo e estudante de doutorado na UIUC, ao VentureBeat. “Para empresas com restrições regulatórias ou contratuais em relação à modificação de modelos, ou que dependem de APIs de LLM fechados, essa modularidade torna o s3 altamente prático. Ele permite que melhorem a qualidade da busca sem alterar sua infraestrutura de geração.”
s3 em ação
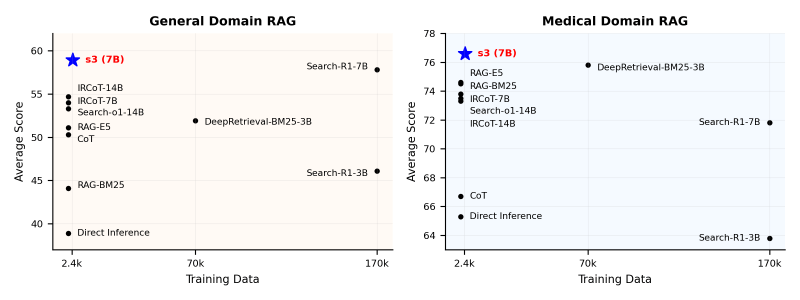
Os pesquisadores testaram o s3 em seis benchmarks gerais de perguntas e respostas, comparando-o contra três categorias de sistemas RAG: Ajuste fino de ponta a ponta (por exemplo, Search-R1), recuperação estática com geradores congelados (como pipelines RAG clássicos) e recuperação ativa com geradores congelados (por exemplo, combinando documentos obtidos pelo Search-R1 com um LLM congelado). Em seus experimentos, utilizaram o Qwen2.5-7B-Instruct como modelo base para o buscador e os LLMs congelados Qwen2.5-14B-Instruct e Claude 3 Haiku como geradores.
O s3 superou as bases estáticas, zero-shot e sintonizadas de ponta a ponta na maioria dos benchmarks e obteve uma pontuação média. Sua eficiência de dados é particularmente notável: o s3 alcançou ganhos significativos com apenas 2.4k exemplos de treinamento, significativamente menos que os 70k exemplos requeridos pelo DeepRetrieval (uma estrutura de recuperação estática) ou os 170k necessários pelo Search-R1, enquanto superou ambos na qualidade do contexto e no desempenho da resposta final.
“Muitas empresas carecem de grandes conjuntos de dados de QA anotados ou da infraestrutura GPU para ajustar sistemas LLM de ponta a ponta. O s3 reduz a barreira permitindo forte desempenho de recuperação com supervisão e computação mínimas,” disse Jiang. “Isso significa protótipos mais rápidos, custos reduzidos e um tempo de implantação mais curto para aplicações de busca com IA.”
Os resultados sugerem uma mudança fundamental na estratégia de otimização. Como os pesquisadores anotam no artigo, a maior parte do ganho de desempenho em RAG provém de “melhorar a capacidade de busca em vez de alinhar saídas de geração”, o que implica que focar o RL na estratégia de busca em vez de alinhamento de geração combinado resulta em melhores resultados.
Outra descoberta crucial para aplicações empresariais é a capacidade do s3 de generalizar para domínios que não foram treinados. O s3 demonstrou sucesso zero-shot em QA médica apesar de ter sido treinado apenas em QA geral, sugerindo que “as habilidades de busca aprendidas por reforço se generalizam de maneira mais confiável do que abordagens ajustadas para geração,” segundo os pesquisadores.
Essa adaptabilidade entre domínios faz do s3 uma solução bem adequada para aplicações empresariais especializadas que frequentemente lidam com conjuntos de dados proprietários ou personalizados sem exigir extensos dados de treinamento específicos de domínio. Isso significa que um único buscador treinado poderia atender diferentes departamentos (por exemplo, jurídico, RH, suporte ao cliente) ou se adaptar a conteúdos em evolução, como novos documentos de produtos.
“Vemos um potencial imediato em saúde, gestão de conhecimento empresarial e suporte à pesquisa científica, onde a alta qualidade de recuperação é crítica e os dados rotulados são frequentemente escassos,” disse Jiang.


Conteúdo relacionado

Dentro da revolução da IA: Principais insights e avanços dos nossos parceiros na TechCrunch Sessions: IA
[the_ad id="145565"] Here's the rewritten content in Portuguese, preserving the HTML tags: <div xmlns:default="http://www.w3.org/2000/svg"> <p id="speakable-summary"…

Grammarly garante $1 bilhão em financiamento não dilutivo da General Catalyst
[the_ad id="145565"] Here's the content rewritten in Portuguese while preserving the HTML tags: <div xmlns:default="http://www.w3.org/2000/svg"> <p…

O novo modelo R1 de IA da DeepSeek, otimizado para rodar em uma única GPU.
[the_ad id="145565"] O modelo de raciocínio AI R1 atualizado da DeepSeek pode estar recebendo a maior parte da atenção da comunidade de IA esta semana. Mas o laboratório de IA…