


Novas pesquisas mostram que a forma como os serviços de IA cobram por tokens oculta o verdadeiro custo dos usuários. Os provedores podem inflar silenciosamente as cobranças manipulando contagens de tokens ou inserindo etapas ocultas. Alguns sistemas realizam processos extras que não afetam a saída, mas aparecem na fatura. Ferramentas de auditoria têm sido propostas, mas sem supervisão real, os usuários acabam pagando mais do que percebem.
Na maioria dos casos, o que nós, consumidores, pagamos por interfaces de chat alimentadas por IA, como o ChatGPT-4o, é atualmente medido em tokens: unidades invisíveis de texto que passam despercebidas durante o uso, mas são contadas com precisão exata para fins de cobrança; e embora cada troca seja precificada com base no número de tokens processados, o usuário não tem uma maneira direta de confirmar a contagem.
Apesar da nossa (no melhor cenário) compreensão imperfeita do que obtemos pela nossa unidade de ‘token’ comprada, a cobrança baseada em tokens tornou-se a abordagem padrão entre os provedores, baseada em uma suposição de confiança que pode se revelar precária.
Palavras de Token
Um token não é exatamente a mesma coisa que uma palavra, embora frequentemente desempenhe um papel semelhante, e a maioria dos provedores usa o termo ‘token’ para descrever pequenas unidades de texto, como palavras, sinais de pontuação ou fragmentos de palavras. A palavra ‘incrível’, por exemplo, pode ser contabilizada como um único token por um sistema, enquanto outro pode dividi-la em in, crível e vel, com cada parte aumentando o custo.
Esse sistema se aplica tanto ao texto que o usuário insere quanto à resposta do modelo, com o preço baseado no total dessas unidades.
A dificuldade está no fato de que os usuários não vêem esse processo. A maioria das interfaces não mostra as contagens de tokens durante uma conversa, e a forma como os tokens são calculados é difícil de reproduzir. Mesmo que uma contagem seja mostrada após uma resposta, já é tarde demais para saber se foi justa, criando um descompasso entre o que o usuário vê e o que está pagando.
Pesquisas recentes apontam para problemas mais profundos: um estudo mostra como os provedores podem cobrar a mais sem nunca quebrar as regras, simplesmente inflando contagens de tokens de maneiras que o usuário não pode ver; outro revela o descompasso entre o que as interfaces exibem e o que é realmente cobrado, deixando os usuários com a ilusão de eficiência onde pode não haver nenhuma; e um terceiro expõe como os modelos geram rotinas internas de raciocínio que nunca são mostradas ao usuário, mas aparecem na fatura.
Os achados representam um sistema que parece preciso, com números exatos que implicam clareza, mas cuja lógica subjacente permanece oculta. Seja isso intencional ou uma falha estrutural, o resultado é o mesmo: os usuários pagam por mais do que podem ver, e muitas vezes mais do que esperam.
Mais Barato por Duzia?
No primeiro desses artigos – intitulado Seu LLM Está Te Cobrançando a Mais? Tokenização, Transparência e Incentivos, de quatro pesquisadores do Instituto Max Planck para Sistemas de Software – os autores argumentam que os riscos da cobrança baseada em tokens vão além da opacidade, apontando para um incentivo embutido para os provedores inflacionarem as contagens de tokens:
‘A essência do problema reside no fato de que a tokenização de uma string não é única. Por exemplo, considere que o usuário envia o prompt “Onde ocorre o próximo NeurIPS?” para o provedor, o provedor o alimenta em um LLM, e o modelo gera a saída “|San| Diego|” consistindo de dois tokens.
‘Como o usuário está alheio ao processo gerativo, um provedor egoísta tem a capacidade de relatar de forma incorreta a tokenização da saída para o usuário, sem sequer alterar a string subjacente. Por exemplo, o provedor poderia simplesmente compartilhar a tokenização “|S|a|n| |D|i|e|g|o|” e cobrar do usuário por nove tokens em vez de dois!’
O artigo apresenta uma heurística capaz de realizar esse tipo de cálculo desonesto sem alterar a saída visível e sem violar a plausibilidade sob configurações de decodificação típicas. Testado em modelos das séries LLaMA, Mistral e Gemma, usando prompts reais, o método alcança sobrecargas mensuráveis sem parecer anômalo:
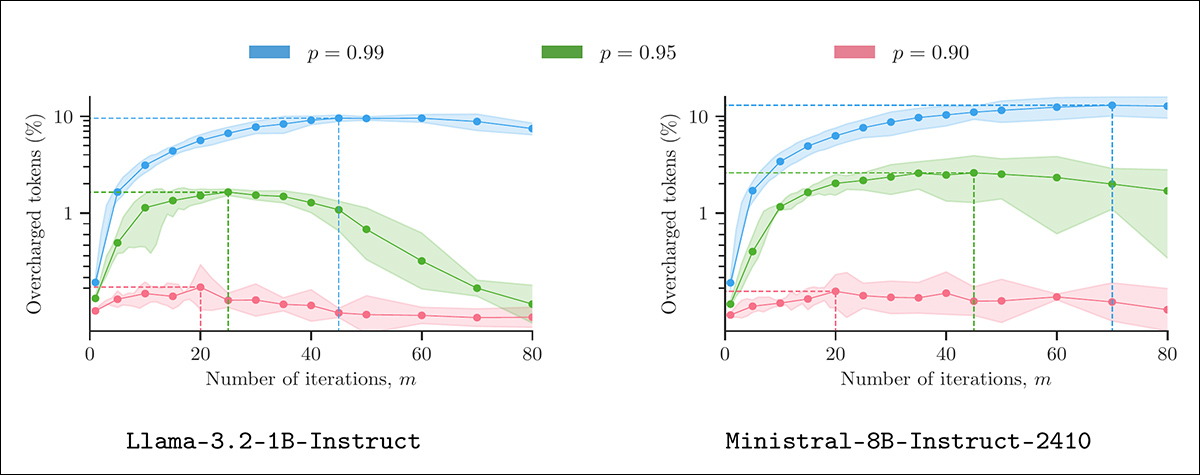
Inflação de tokens usando ‘relato plausível’. Cada painel mostra a porcentagem de tokens sobrecarregados resultantes da aplicação do Algoritmo 1 a saídas de 400 prompts LMSYS, sob parâmetros de amostragem variados (m e p). Todas as saídas foram geradas a uma temperatura de 1.3, com cinco repetições por configuração para calcular intervalos de confiança de 90%. Fonte: https://arxiv.org/pdf/2505.21627
Para enfrentar o problema, os pesquisadores pedem que a cobrança seja baseada em contagem de caracteres em vez de tokens, argumentando que esta é a única abordagem que dá aos provedores um motivo para relatar o uso de forma honesta, e sustentando que, se o objetivo é a cobrança justa, então atar o custo a caracteres visíveis, não a processos ocultos, é a única opção que resiste ao escrutínio. A cobrança baseada em caracteres, eles argumentam, removeria o motivo para relatar incorrectamente, além de recompensar saídas mais curtas e eficientes.
Aqui, no entanto, há várias considerações extras, que os autores em sua maioria admitem. Em primeiro lugar, o esquema baseado em caracteres proposto introduz uma lógica de negócios adicional que pode favorecer o fornecedor em relação ao consumidor:
‘[A] um provedor que nunca reporta incorretamente tem um incentivo claro para gerar a sequência de saída de tokens mais curta possível e melhorar os algoritmos de tokenização atuais, como o BPE, para que eles comprimam a sequência de saída de tokens o máximo possível’
Aqui, o motivo otimista é que o fornecedor é assim incentivado a produzir saídas mais concisas, significativas e valiosas. Na prática, há obviamente maneiras menos virtuosas para um provedor reduzir a contagem de texto.
Em segundo lugar, é razoável supor, afirmam os autores, que as empresas provavelmente exigiriam legislação para transitar do arcano sistema de tokens para um método de cobrança mais claro, baseado em texto. No futuro, uma startup insurgente pode decidir diferenciar seu produto lançando-o com esse tipo de modelo de preços; mas qualquer um com um produto realmente competitivo (e operando em uma escala menor que a categoria EEE) é desincentivado a fazer isso.
Finalmente, algoritmos desonestos como os propostos pelos autores teriam seu próprio custo computacional; se o custo de calcular um ‘acréscimo’ ultrapassasse o potencial benefício de lucro, o esquema claramente não teria mérito. No entanto, os pesquisadores enfatizam que seu algoritmo proposto é eficaz e econômico.
Os autores disponibilizam o código de suas teorias no GitHub.
A Mudança
O segundo artigo – intitulado Tokens Invisíveis, Contas Visíveis: A Necessidade Urgente de Auditar Operações Ocultas em Serviços LLM Opacos, de pesquisadores da Universidade de Maryland e Berkeley – argumenta que os incentivos desalinhados nas APIs de modelos de linguagem comerciais não se limitam à divisão de tokens, mas se estendem a classes inteiras de operações ocultas.
Essas operações incluem chamadas internas do modelo, raciocínio especulativo, uso de ferramentas e interações entre múltiplos agentes – todas as quais podem ser cobradas ao usuário sem visibilidade ou recurso.
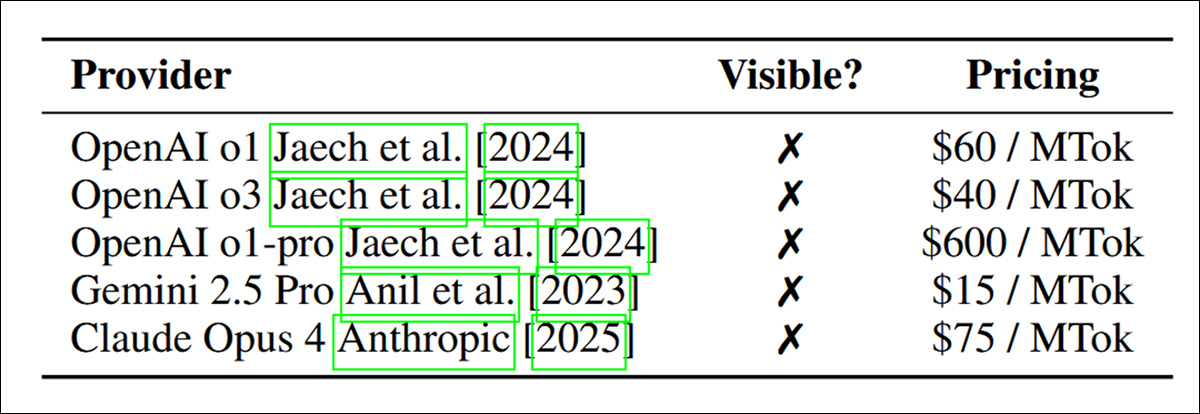
Cobrança e transparência dos APIs LLM de raciocínio entre os principais provedores. Todos os serviços listados cobram dos usuários por tokens ocultos de raciocínio interno, e nenhum torna esses tokens visíveis durante a execução. Os custos variam significativamente, com o modelo o1-pro da OpenAI cobrando dez vezes mais por milhão de tokens do que o Claude Opus 4 ou o Gemini 2.5 Pro, apesar da opacidade igual. Fonte: https://www.arxiv.org/pdf/2505.18471
Diferente da cobrança convencional, onde a quantidade e qualidade dos serviços são verificáveis, os autores sustentam que as plataformas LLM de hoje operam sob opacidade estrutural: os usuários são cobrados com base no uso de tokens e APIs reportados, mas não têm meios de confirmar se essas métricas refletem trabalho real ou necessário.
O artigo identifica duas formas principais de manipulação: inflação da quantidade, onde o número de tokens ou chamadas é aumentado sem benefício para o usuário; e degradação da qualidade, onde modelos ou ferramentas de menor desempenho são usados silenciosamente em vez de componentes premium:
‘Nas APIs de raciocínio LLM, os provedores frequentemente mantêm múltiplas variantes da mesma família de modelos, diferenciando-se em capacidade, dados de treinamento ou estratégia de otimização (ex: ChatGPT o1, o3). Degradação de modelo refere-se à substituição silenciosa de modelos de menor custo, o que pode introduzir um desalinhamento entre a qualidade de serviço esperada e a real.
‘Por exemplo, um prompt pode ser processado por um modelo de menor tamanho, enquanto a cobrança permanece inalterada. Essa prática é difícil para os usuários detectarem, uma vez que a resposta final pode parecer plausível para muitas tarefas.’
O artigo documenta casos em que mais de noventa por cento dos tokens cobrados nunca foram mostrados aos usuários, com o raciocínio interno inflacionando o uso de tokens por um fator maior que vinte. Justificada ou não, a opacidade dessas etapas nega aos usuários qualquer base para avaliar sua relevância ou legitimidade.
Em sistemas agentes, a opacidade aumenta, pois as trocas internas entre agentes de IA podem incorrer em cobranças sem impactar significativamente a saída final:
‘Além do raciocínio interno, os agentes se comunicam trocando prompts, resumos e instruções de planejamento. Cada agente interpreta as entradas de outros e gera saídas para guiar o fluxo de trabalho. Essas mensagens entre agentes podem consumir substanciais tokens, que geralmente não são visíveis diretamente para os usuários finais.
‘Todos os tokens consumidos durante a coordenação entre agentes, incluindo prompts gerados, respostas e instruções relacionadas a ferramentas, geralmente não são apresentados ao usuário. Quando os próprios agentes utilizam modelos de raciocínio, a cobrança se torna ainda mais opaca.’
Para confrontar esses problemas, os autores propõem uma estrutura de auditoria em camadas envolvendo provas criptográficas de atividade interna, marcadores verificáveis de identidade de modelo ou ferramenta e supervisão independente. A preocupação subjacente, no entanto, é estrutural: os atuais esquemas de cobrança LLM dependem de uma persistente asimetria de informação, deixando os usuários expostos a custos que não podem verificar ou detalhar.
Contando o Invisível
O último artigo, de pesquisadores da Universidade de Maryland, reconfigura o problema de cobrança não como uma questão de uso indevido ou relatório incorreto, mas de estrutura. O artigo – intitulado CoIn: Contando os Tokens de Raciocínio Invisíveis em APIs LLM Comerciais Opacas, e de dez pesquisadores da Universidade de Maryland – observa que a maioria dos serviços LLM comerciais agora oculta o raciocínio intermediário que contribui para a resposta final de um modelo, e ainda cobra por esses tokens.
O artigo afirma que isso cria uma superfície de cobrança não observável onde sequências inteiras podem ser fabricadas, inseridas ou inflacionadas sem detecção:
‘[Isso] invisibilidade permite que os provedores reportem incorretamente contagens de tokens ou injuntem tokens de raciocínio fabricados de baixo custo para inflacionar artificialmente contagens de tokens. Nós nos referimos a essa prática como inflação de contagem de tokens.
‘Por exemplo, uma única execução de alta eficiência ARC-AGI pelo modelo o3 da OpenAI consumiu 111 milhões de tokens, custando $66,772.3. Considerando essa escala, mesmo pequenas manipulações podem ter um impacto financeiro substancial.
‘Tal assimetria de informação permite que as empresas de IA cobrem substancialmente a mais dos usuários, comprometendo assim seus interesses.’
Para contrabalançar essa assimetria, os autores propõem o CoIn, um sistema de auditoria de terceiros projetado para verificar tokens ocultos sem revelar seus conteúdos, utilizando impressões digitais hash e verificações semânticas para detectar sinais de inflação.
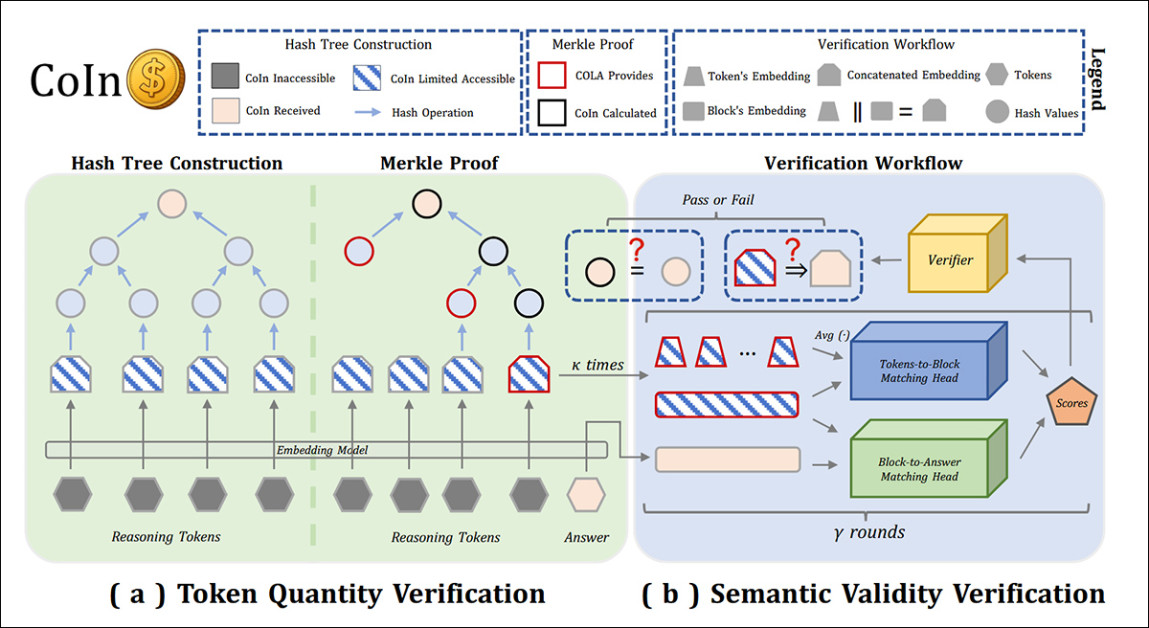
Visão geral do sistema de auditoria CoIn para LLMs comerciais opacos. O Painel A mostra como os embeddings dos tokens de raciocínio são transformados em uma árvore Merkle para verificação de contagem de tokens sem revelar conteúdos de tokens. O Painel B ilustra verificações de validade semântica, onde redes neurais leves comparam blocos de raciocínio à resposta final. Juntos, esses componentes permitem que auditores de terceiros detectem inflação de tokens ocultos enquanto preservam a confidencialidade do comportamento do modelo proprietário. Fonte: https://arxiv.org/pdf/2505.13778
Um componente verifica contagens de tokens criptograficamente usando uma árvore Merkle; o outro avalia a relevância do conteúdo oculto comparando-o com a embedagem da resposta. Isso permite que auditores detectem preenchimentos ou irrelevâncias – sinais de que tokens estão sendo inseridos apenas para aumentar a conta.
Quando implantado em testes, o CoIn alcançou uma taxa de sucesso de detecção de quase 95% para algumas formas de inflação, com mínima exposição dos dados subjacentes. Embora o sistema ainda dependa da cooperação voluntária dos provedores e tenha resolução limitada em casos extremos, seu ponto mais amplo é inegável: a própria arquitetura da cobrança atual de LLM assume uma honestidade que não pode ser verificada.
Conclusão
Além da vantagem de receber o pagamento antecipadamente dos usuários, uma moeda baseada em scrip (como o sistema de ‘buzz’ no CivitAI) ajuda a abstrair os usuários do verdadeiro valor da moeda que estão gastando, ou da mercadoria que estão comprando. Da mesma forma, dar à um vendedor liberdade para definir suas próprias unidades de medida deixa ainda mais o consumidor no escuro sobre o que está realmente gastando, em termos de dinheiro real.
Como a falta de relógios em Las Vegas, medidas desse tipo geralmente visam tornar o consumidor imprudente ou indiferente ao custo.
O pouco compreendido token, que pode ser consumido e definido de tantas maneiras, é, talvez, uma unidade de medida inadequada para o consumo de LLM – não menos porque pode custar muitas vezes mais tokens calcular um resultado pior de LLM em um idioma não inglês, em comparação a uma sessão em inglês.
No entanto, a saída baseada em caracteres, como sugerido pelos pesquisadores do Max Planck, provavelmente favoreceria idiomas mais concisos e penalizaria idiomas naturalmente verbosos. Uma vez que indicações visuais como um contador de tokens depreciativo provavelmente nos tornariam um pouco mais gastadores em nossas sessões de LLM, parece improvável que tais adições úteis de GUI venham em breve – pelo menos sem uma ação legislativa.
* Ênfase dos autores. Minha conversão das citações inline dos autores em hyperlinks.
Primeira publicação quinta-feira, 29 de maio de 2025

Conteúdo relacionado

Descoberta da Microsoft: Como Agentes de IA Estão Acelerando Descobertas Científicas
[the_ad id="145565"] A pesquisa científica tem sido tradicionalmente um processo lento e cuidadoso. Cientistas passam anos testando ideias e realizando experimentos. Eles leem…

FLUX.1 Kontext permite a geração de imagens em contexto para pipelines de IA empresarial.
[the_ad id="145565"] Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba Mais…

Elon se afasta do DOGE e o Vale do Silício entra na fase de ‘descoberta’
[the_ad id="145565"] Elon Musk anunciou oficialmente que está se afastando como um funcionário especial do governo dos EUA e o chefe de fato do Departamento de Eficiência…