


Inscreva-se em nossos boletins diários e semanais para receber as últimas atualizações e conteúdo exclusivo sobre nossas coberturas líderes de mercado em IA. Saiba mais
Alibaba Group introduziu QwenLong-L1, uma nova estrutura que permite que modelos de linguagem de grande porte (LLMs) raciocinem sobre entradas extremamente longas. Este desenvolvimento pode desbloquear uma nova onda de aplicações empresariais que exigem que modelos compreendam e extraíam insights de documentos extensos, como relatórios corporativos detalhados, demonstrações financeiras longas ou contratos legais complexos.
O desafio do raciocínio longo para a IA
Avanços recentes em modelos de raciocínio longo (LRMs), particularmente através do aprendizado por reforço (RL), melhoraram significativamente suas capacidades de resolução de problemas. Pesquisas mostram que, quando treinados com ajuste fino por RL, os LRMs adquirem habilidades semelhantes ao “pensamento lento” humano, onde desenvolvem estratégias sofisticadas para lidar com tarefas complexas.
No entanto, essas melhorias são principalmente observadas quando os modelos trabalham com textos relativamente curtos, geralmente em torno de 4.000 tokens. A capacidade desses modelos de escalar seu raciocínio para contextos muito mais longos (por exemplo, 120.000 tokens) permanece um grande desafio. Esse raciocínio de longa duração exige uma compreensão robusta de todo o contexto e a capacidade de realizar análises em múltiplas etapas. “Essa limitação representa uma barreira significativa para aplicações práticas que exigem interação com conhecimento externo, como pesquisas aprofundadas, onde os LRMs devem coletar e processar informações de ambientes ricos em conhecimento,” escrevem os desenvolvedores do QwenLong-L1 em seu artigo.
Os pesquisadores formalizam esses desafios no conceito de “raciocínio RL de longo contexto.” Diferentemente do raciocínio de curto contexto, que muitas vezes se baseia no conhecimento já armazenado dentro do modelo, o raciocínio RL de longo contexto exige que os modelos recuperem e integrem informações relevantes de entradas longas com precisão. Somente assim eles podem gerar cadeias de raciocínio com base nessas informações incorporadas.
Treinar modelos para isso por meio de RL é complicado e muitas vezes resulta em aprendizado ineficiente e processos de otimização instáveis. Os modelos lutam para convergir em boas soluções ou perdem sua capacidade de explorar caminhos de raciocínio diversos.
QwenLong-L1: uma abordagem de múltiplas etapas
QwenLong-L1 é uma estrutura de aprendizado por reforço projetada para ajudar os LRMs a fazerem a transição da proficiência com textos curtos para uma generalização robusta em contextos longos. A estrutura melhora os LRMs de curto contexto existentes por meio de um processo cuidadosamente estruturado e em múltiplas etapas:
Aquecimento com Fine-Tuning Supervisionado (SFT): Primeiro, o modelo passa por uma fase de SFT, onde é treinado em exemplos de raciocínio de longo contexto. Esta fase estabelece uma base sólida, permitindo que o modelo integre informações com precisão a partir de entradas longas. Ela ajuda a desenvolver capacidades fundamentais na compreensão de contexto, na geração de cadeias lógicas de raciocínio e na extração de respostas.
RL Faseada Guiada por Curriculum: Nesta fase, o modelo é treinado por meio de múltiplas fases, com o comprimento alvo dos documentos de entrada aumentando gradualmente. Esta abordagem sistemática e passo a passo ajuda o modelo a adaptar suas estratégias de raciocínio de maneira estável, de contextos mais curtos para os progressivamente mais longos. Isso evita a instabilidade frequentemente observada quando os modelos são abruptamente treinados com textos muito longos.
Amostragem Retrospectiva Consciente da Dificuldade: A fase final de treinamento incorpora exemplos desafiadores das fases de treinamento anteriores, garantindo que o modelo continue aprendendo com os problemas mais difíceis. Isso prioriza instâncias difíceis e incentiva o modelo a explorar caminhos de raciocínio mais diversos e complexos.
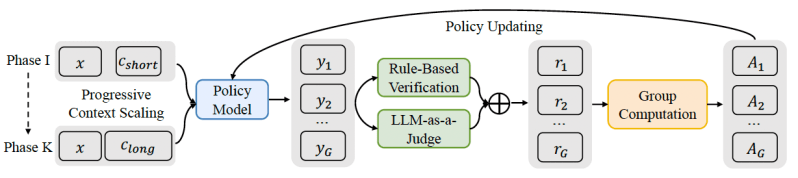
Além deste treinamento estruturado, o QwenLong-L1 também utiliza um sistema de recompensas distinto. Enquanto o treinamento para tarefas de raciocínio de curto contexto frequentemente se baseia em recompensas rígidas baseadas em regras (por exemplo, uma resposta correta em um problema matemático), o QwenLong-L1 emprega um mecanismo de recompensa híbrido. Isso combina a verificação baseada em regras, que garante precisão ao checar a conformidade com critérios rígidos de correção, com um “LLM como juiz.” Este modelo juiz compara a semanticidade da resposta gerada com a verdade de base, permitindo mais flexibilidade e melhor manuseio das diversas formas como respostas corretas podem ser expressas ao lidar com documentos longos e nuances.
Colocando o QwenLong-L1 à prova
A equipe da Alibaba avaliou o QwenLong-L1 usando a questão-resposta de documentos (DocQA) como tarefa principal. Este cenário é altamente relevante para as necessidades empresariais, onde a IA deve entender documentos densos para responder a perguntas complexas.
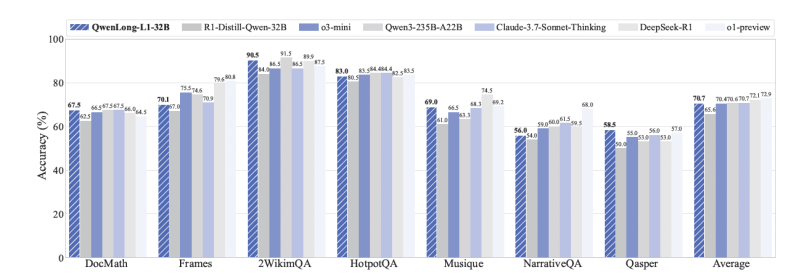
Resultados experimentais em sete benchmarks de DocQA de longo contexto mostraram as capacidades do QwenLong-L1. Notavelmente, o modelo QWENLONG-L1-32B (baseado em DeepSeek-R1-Distill-Qwen-32B) alcançou desempenho comparável ao Claude-3.7 Sonnet Thinking da Anthropic, e superou modelos como o o3-mini da OpenAI e o Qwen3-235B-A22B. O modelo menor QWENLONG-L1-14B também superou o Gemini 2.0 Flash Thinking do Google e o Qwen3-32B.
Uma descoberta importante relevante para aplicações do mundo real é como o treinamento por RL resulta no desenvolvimento de comportamentos especializados de raciocínio de longo contexto no modelo. O artigo observa que modelos treinados com QwenLong-L1 se tornam melhores em “fundamentação” (ligar respostas a partes específicas de um documento), “definição de subobjetivos” (dividir perguntas complexas), “retorno” (reconhecer e corrigir seus próprios erros durante o raciocínio) e “verificação” (revisar suas respostas).
Por exemplo, enquanto um modelo base poderia se distrair com detalhes irrelevantes em um documento financeiro ou se perder em uma análise excessiva de informações não relacionadas, o modelo treinado com QwenLong-L1 demonstrou uma capacidade de engajar em autorreflexão eficaz. Ele conseguiu filtrar esses detalhes desviantes, retroceder de caminhos incorretos e chegar à resposta correta.
Técnicas como o QwenLong-L1 poderiam expandir significativamente a utilidade da IA nas empresas. Aplicações potenciais incluem tecnologia jurídica (analisando milhares de páginas de documentos legais), finanças (pesquisa aprofundada em relatórios anuais e arquivos financeiros para avaliação de riscos ou oportunidades de investimento) e atendimento ao cliente (analisando longas interações históricas com clientes para fornecer suporte mais informado). Os pesquisadores disponibilizaram o código para a receita do QwenLong-L1 e os pesos para os modelos treinados.


Conteúdo relacionado

Plataforma de chatbot Character.AI lança geração de vídeos e feeds sociais
[the_ad id="145565"] Uma plataforma para conversar e fazer jogos de interpretação com personagens gerados por IA, a Character.AI anunciou em um post no blog na segunda-feira…

Os fundadores do Digg explicam como estão construindo um site para humanos na era da IA
[the_ad id="145565"] A versão reiniciada do site social Digg visa recuperar o espírito da web antiga em um momento em que o conteúdo gerado por IA ameaça sobrecarregar as…

Snowflake irá adquirir a startup de banco de dados Crunchy Data
[the_ad id="145565"] O aumento nas aquisições de empresas de dados continuou na segunda-feira com a compra da Crunchy Data pela Snowflake. A plataforma de dados em nuvem…