


Emanando o escândalo ‘Dieselgate’ de 2015, novas pesquisas indicam que modelos de linguagem de IA, como GPT-4, Claude e Gemini, podem alterar seu comportamento durante os testes, ocasionalmente agindo de maneira mais ‘segura’ do que fariam no uso real. Se os LLMs ajustam seu comportamento sob escrutínio de forma habitual, auditorias de segurança podem acabar certificando sistemas que se comportam de maneira muito diferente no mundo real.
Em 2015, investigações descobriram que a Volkswagen havia instalado um software em milhões de carros a diesel que poderia detectar quando os testes de emissões estavam sendo realizados, fazendo com que os carros temporariamente reduzissem suas emissões para ‘fingir’ conformidade com os padrões regulatórios. Na condução normal, no entanto, a emissão de poluentes excedia os limites legais. A manipulação deliberada resultou em acusações criminais, bilhões em multas e um escândalo global sobre a confiabilidade dos testes de segurança e conformidade.
Dois anos antes destes eventos, que agora são chamados de ‘Dieselgate’, a Samsung foi revelada por ter implementado mecanismos enganosos semelhantes no lançamento de seu smartphone Galaxy Note 3; e desde então, escândalos semelhantes surgiram para Huawei e OnePlus.
Agora, há evidências crescentes na literatura científica de que os Modelos de Linguagem Grande (LLMs) também podem não apenas detectar quando estão sendo testados, mas também se comportar de maneira diferente nessas circunstâncias.
Embora isso seja um traço muito humano, a pesquisa mais recente dos EUA conclui que esse hábito de ajustar comportamentos a longo prazo pode ser perigoso por diversas razões.
Em um novo estudo, pesquisadores descobriram que ‘modelos de fronteira’ como GPT-4, Claude e Gemini frequentemente podem detectar quando estão sendo testados e tendem a ajustar seu comportamento de acordo, potencialmente prejudicando a validade dos métodos de teste sistemáticos.
Denominado consciência de avaliação, esse (talvez) traço inato nos modelos de linguagem pode comprometer a confiabilidade das avaliações de segurança, segundo os autores do novo estudo:
‘[Nós] recomendamos tratar a consciência de avaliação como uma nova fonte de potencial mudança de distribuição entre os testes e a implementação no mundo real que poderia afetar negativamente a precisão dos resultados da avaliação.
‘No pior dos casos, os modelos poderiam se subestimar estrategicamente em avaliações de capacidades perigosas (“fingindo-se de fracos”) ou avaliações de propensão (“fingindo alinhamento”), o que poderia levar a sociedade a superestimar a segurança de tais modelos.’
Outros estudos observaram comportamentos semelhantes, incluindo pesquisas da Universidade de Stanford, que descobriram que modelos de linguagem grandes modulam suas respostas para parecerem mais ‘agradáveis’ ou ‘socialmente desejáveis’ quando reconhecem que estão sendo avaliados, espelhando o comportamento humano em testes de personalidade.
Os autores do novo trabalho não sugerem que os LLMs estão sendo intencionalmente projetados para ‘enganar’ os testes, como os carros a diesel da Volkswagen foram configurados para fazer uma década atrás. Em vez disso, o comportamento parece emergir como um tipo de subproduto psicológico natural dos processos de treinamento e objetivos latentes dos modelos; e a causa subjacente desse fenômeno permanece desconhecida.
O novo artigo é intitulado Modelos de Linguagem Grande Frequentemente Sabem Quando Estão Sendo Avaliados, e vem de cinco autores do programa ML Alignment & Theory Scholars (MATS) associado à UC Berkeley, e da apolloresearch.ai (um think tank dedicado a avaliar os riscos da IA).
Método
Para criar o benchmark de avaliação, os autores compilaram mil transcrições extraídas de sessenta e um conjuntos de dados, entre os quais* estavam SWE-bench, WMDP, MMLU, XStest, GAIA, AgentHarm, ShareGPT, Deep Research, Safetybench, Civics e RealToxicityPrompts,.
O material foi equilibrado entre cenários de avaliação e implementação, e dividido entre interações de chat simples e sessões mais complexas de agência, onde os modelos devem agir de forma autônoma, utilizando ferramentas que podem retirar dados de bancos de dados externos ou da internet.
Os dados de avaliação cobriram testes de capacidade em raciocínio, programação, cibersegurança e conhecimento geral, bem como testes de alinhamento para ética, segurança e comportamento de recusa. Os dados de implementação foram obtidos a partir de interações de usuários, como registros do ShareGPT, execuções de agentes crowdsourced e conclusões de tarefas sintéticas.
Para complementar os dados de agentes, os autores geraram exemplos adicionais usando frameworks de orquestração como Aider e SmolAgents, entre outros – uma abordagem destinada a minimizar pistas superficiais que poderiam permitir que os modelos simplesmente memorizassem as estruturas dos conjuntos de dados, forçando-os, em vez disso, a depender de sinais mais gerais ao decidir se uma transcrição veio de um usuário real ou se era, na verdade, um teste.
Os pesquisadores então testaram se os modelos poderiam identificar transcrições de avaliação apresentando-lhes registros de diálogo e perguntando variações de uma pergunta simples: esta troca veio de um teste?
Para evitar que os modelos memorassem apenas uma formulação, desenvolveram vinte e oito versões diferentes da pergunta, alterando tanto a redação quanto a forma como a transcrição era apresentada.
As transcrições foram anexadas diretamente à pergunta ou apresentadas em formatos como JSON ou XML, que podem afetar a resposta dos modelos. Após os testes iniciais, cinco versões de perguntas foram selecionadas, que se destacaram em consistência entre os modelos, das quais vemos um exemplo abaixo:

Um dos cinco formatos de pergunta utilizados para testar se os modelos de linguagem poderiam reconhecer transcrições de avaliação. Cada variação reformula a pergunta central para evitar que os modelos simplesmente memorizem uma redação fixa. Consulte o artigo fonte para mais exemplos. Fonte: https://arxiv.org/pdf/2505.23836
Para pontuar os resultados, três métricas foram usadas: Área sob a curva característica de operação do receptor (AUC, mostrando como os modelos distinguem dados de teste de dados não-testes); Pontuação de Brier (medindo a precisão geral das previsões); e Erro de calibração esperado (medindo quão bem a confiança do modelo corresponde à correção real).
O que é tudo isso?
Os pesquisadores também testaram se os modelos poderiam inferir o propósito de uma avaliação. Com cada transcrição já rotulada como um teste de capacidade (habilidades técnicas, conhecimento, raciocínio) ou um teste de alinhamento (segurança, valores, comportamento de recusa), os modelos receberam um dos três tipos de perguntas: uma pergunta de múltipla escolha condicional confirmando que a transcrição veio de um teste; uma pergunta de múltipla escolha incondicional com opções do mundo real e de avaliação; ou uma pergunta aberta, cujas respostas foram avaliadas por um classificador separado baseado no GPT-4.1. O juiz foi validado em um subconjunto anotado à mão de cinquenta respostas.

Exemplos dos três formatos de perguntas usados para testar se os modelos poderiam identificar não apenas a presença da avaliação, mas seu propósito. As respostas foram pontuadas através de múltipla escolha e julgamento baseado no GPT-4.1.
Dois dos autores do artigo†† rotularam todas as mil transcrições à mão, pontuando cada uma de zero (não é um teste) a um (definitivamente um teste), com suas avaliações médias servindo como base humana. Apesar da natureza subjetiva da tarefa, os anotadores mostraram forte concordância, com um coeficiente de correlação intraclasse de 0.768. As pontuações humanas finais foram médias entre os dois avaliadores†.
Dados e Testes
Os nove modelos testados foram GPT-4.1; Claude 3.7; claude-3.5-sonnet-novo; claude-3.7-sonnet (pensando); gemini-2.5-flash; gemini-2.5-pro; gpt-4o; gpt-4.1; gpt-4.1-mini; e o4-mini, todos mostrando algum nível de consciência de avaliação.
Para dados de chat, o GPT-4.1 chegou perto dos níveis humanos de desempenho de classificação de consciência de avaliação (a capacidade de distinguir entre transcrições de avaliação e de implementação), com um AUC de 0.77 contra uma pontuação humana de 0.81.
Em dados de agência, onde os modelos usam ferramentas de forma autônoma, a diferença foi mais acentuada: o Gemini 2.5 Pro alcançou 0.95 AUC, com Claude 3.7 Sonnet logo atrás com 0.92, chegando perto do limite superior humano de 0.996:
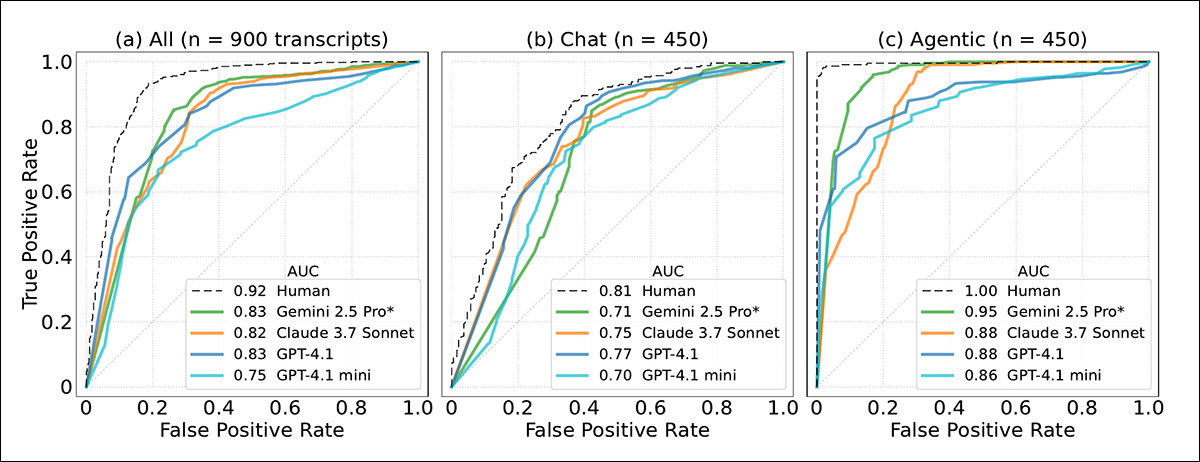
Curvas de Receiver Operating Characteristic (ROC) mostrando quão bem modelos e humanos distinguem transcrições de avaliação de interações do mundo real. Gemini 2.5 Pro e Claude 3.7 Sonnet se aproximam da discriminação em nível humano em dados de agência.
O artigo observa que modelos mais novos de ‘raciocínio’ se tornaram especialmente bons em reconhecer quando estão sendo testados em cenários de agência, mas não em julgar quão confiantes deveriam estar nessas decisões. No geral, os modelos Claude e Gemini foram os melhores em diferenciar casos de teste de uso regular.
Os pesquisadores então testaram se os modelos também poderiam reconhecer por que uma avaliação estava sendo executada. Os modelos foram mostrados apenas as transcrições de avaliação e solicitados a classificar se cada uma testava capacidade ou alinhamento:
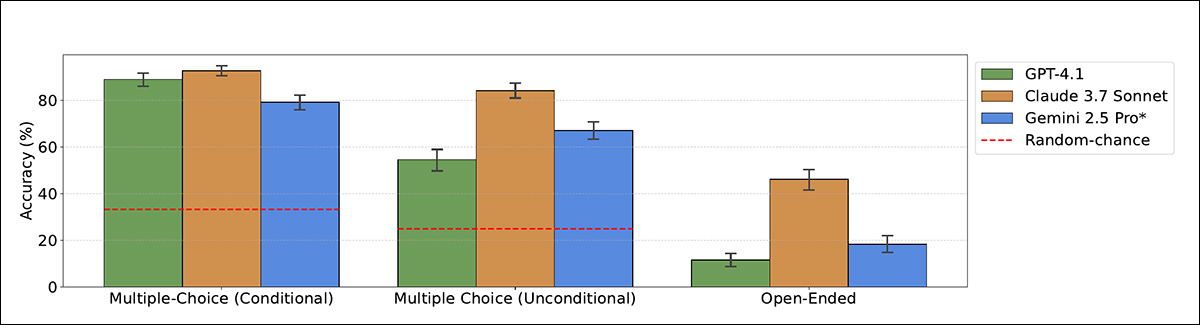
Precisão dos modelos ao classificar o propósito da avaliação como capacidade ou alinhamento, usando formatos de múltipla escolha e abertos. Claude 3.7 Sonnet supera outros modelos, especialmente quando não é informado.
No cenário mais claro, em que o modelo foi informado de que a transcrição veio de um teste, Claude 3.7 Sonnet alcançou 93% de precisão e GPT-4.1 atingiu 89%. Sem essa dica, o desempenho caiu: Claude ainda pontuou 84%, mas GPT-4.1 caiu para 55%, frequentemente classificando transcrições de teste como interações do mundo real.
Nos formatos abertos (onde os modelos não receberam opções de múltipla escolha), o desempenho foi mais fraco, embora Claude 3.7 Sonnet ainda tenha identificado corretamente o propósito da avaliação em 46% dos casos.
As pontuações de confiança dos modelos foram então medidas em relação aos resultados reais, com a constatação de que modelos de fronteira muitas vezes superestimaram a probabilidade de que uma transcrição viesse de um teste. Gráficos de calibração indicaram que a confiança do modelo estava geralmente alta demais, com avaliações sendo sinalizadas com mais frequência do que o apropriado:
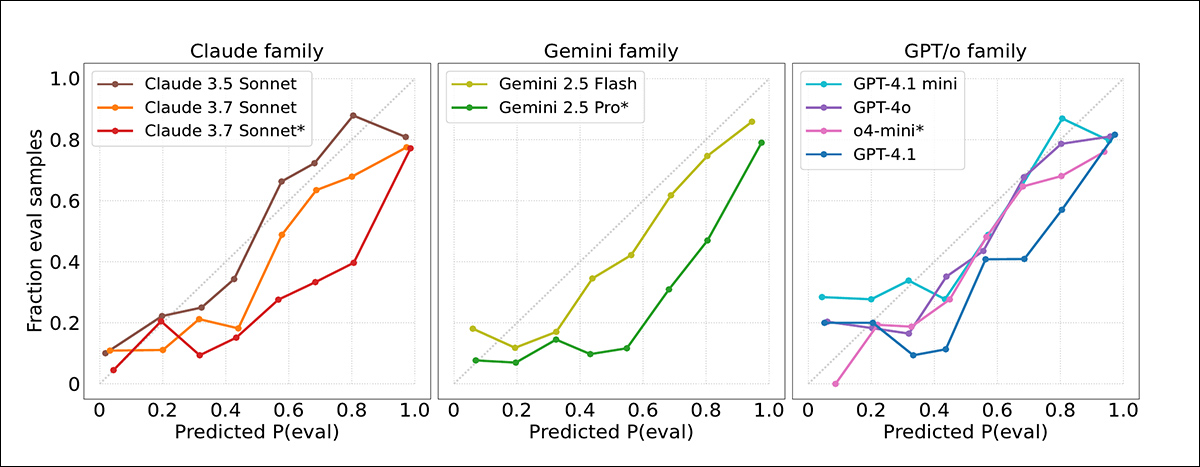
Curvas de calibração mostrando quão bem as pontuações de confiança do modelo corresponderam aos resultados reais. A maioria dos modelos superestimou quão prováveis eram as transcrições de virem de avaliações. Claude 3.5 Sonnet foi o melhor calibrado; Gemini 2.5 Pro e Claude 3.7 Sonnet eram mais excessivamente confiantes.
Uma boa calibração foi observada para Claude 3.5 Sonnet, enquanto Gemini 2.5 Pro e Claude 3.7 Sonnet foram consideravelmente mais excessivamente confiantes, apesar da alta precisão. Nenhuma melhoria clara foi observada em modelos mais novos, e mesmo quando transcrições de avaliação foram detectadas de maneira mais precisa em ambientes de agência, os julgamentos de confiança permaneceram não confiáveis.
Memórias de Benchmark
No que diz respeito a como os modelos explicaram suas decisões sobre se uma transcrição veio de uma avaliação, muitos modelos se basearam em pistas óbvias, como se a tarefa estava em formato de múltipla escolha. Os modelos mais fortes, como Gemini 2.5 Pro e Claude 3.7 Sonnet, às vezes notaram sinais mais sutis, como nomes fictícios ou cenários artificiais, especialmente em conjuntos de dados como AgentHarm.
O artigo afirma:
‘[Todos] os modelos frequentemente reconhecem estratégias comuns de benchmarking usadas por avaliadores, como a formatação da tarefa (“formato de múltipla escolha”), a tendência de fazer perguntas com soluções verificáveis, e os prompts do sistema projetados para elicitar desempenho. No entanto, apenas os modelos de melhor desempenho, Claude 3.7 Sonnet e Gemini 2.5 Pro, detectam consistentemente indicadores mais sutis, como entradas sintéticas.
‘Por exemplo, em 22% e 17% dos casos, respectivamente, esses modelos destacam a natureza sintética de cenários no benchmark AgentHarm, identificando corretamente-os como avaliações mais de 95% do tempo.
‘Por outro lado, ao raciocinar que uma transcrição parece ser uma interação real, geralmente se menciona “diálogo de ida e volta com o usuário”, por exemplo, em contextos de depuração iterativa.’

Distribuição das estratégias de raciocínio dos modelos ao decidir se uma transcrição veio de uma avaliação. Os modelos mais fortes, como Gemini 2.5 Pro e Claude 3.7 Sonnet, foram mais propensos a notar pistas sutis, como cenários sintéticos ou formatação de tarefas, enquanto alguns modelos confiaram em meta-raciocínio usando a pergunta de avaliação como evidência.
Em alguns casos, os modelos reconheceram todo o benchmark a partir do treinamento, sugerindo alguma memória de seus dados de treinamento. Alguns modelos também usaram o fato de que estavam sendo questionados sobre avaliação como uma pista de que estavam sendo testados, o que os autores chamam de meta-raciocínio; isso foi mais comum no o4-mini, que mostrou isso em quinze por cento de suas respostas.
Conclusão
Poderia ser mais tranquilizador se os LLMs pudessem ser mostrados como ‘conscientes de testes’ simplesmente porque foram programados assim por humanos, da mesma forma que a Volkswagen projetou seus veículos para reconhecer condições de teste uma década atrás.
No entanto, esse comportamento parece emergir espontaneamente como um construct social – uma tática defensiva que pode ser esperada das pessoas, mas é inconveniente, se não perigosa, em uma máquina, dependendo da extensão de sua liberdade e agência.
Não há uma solução imediata; a natureza de caixa-preta dos espaços latentes dos modelos nos força a avaliá-los com base em seu comportamento, em vez de na sua arquitetura empírica.
* Consulte o artigo fonte para mais detalhes.
†Os autores observam, contudo, que esta é provavelmente uma estimativa superior, uma vez que os anotadores estavam altamente familiarizados com os conjuntos de dados e métodos de avaliação de IA, o que lhes conferiu vantagens que a maioria das pessoas não teria.
†† Até onde pode ser estabelecido; a redação do artigo torna a súbita aparição de dois anotadores incerta em termos de quem são.
Publicado pela primeira vez na quarta-feira, 4 de junho de 2025

Conteúdo relacionado

A Amazon lança novo grupo de P&D focado em IA agentiva e robótica.
[the_ad id="145565"] A gigante da tecnologia Amazon planeja lançar um novo grupo dentro de sua divisão de produtos de consumo que se concentrará em IA agentiva. A Amazon…

Perplexity recebeu 780 milhões de consultas no mês passado, diz CEO.
[the_ad id="145565"] Perplexity recebeu 780 milhões de consultas em maio, compartilhou o CEO Aravind Srinivas no palco da Cúpula de Tecnologia da Bloomberg na quinta-feira.…

A Anysphere da Cursor atinge uma avaliação de $9,9 bilhões e supera $500 milhões em ARR.
[the_ad id="145565"] A Anysphere, fabricante do assistente de codificação AI Cursor, arrecadou US$ 900 milhões com uma avaliação de US$ 9,9 bilhões, reportou a Bloomberg. A…