


A Nvidia está implementando seus chips de IA em data centers e no que a empresa chama de fábricas de IA ao redor do mundo, e anunciou hoje que seus chips Blackwell estão liderando os benchmarks de IA.
A Nvidia e seus parceiros estão acelerando o treinamento e a implantação de aplicações de IA de próxima geração que utilizam os mais recentes avanços em treinamento e inferência.
A arquitetura Nvidia Blackwell foi projetada para atender às crescentes exigências de desempenho dessas novas aplicações. Na mais recente rodada do MLPerf Training — a 12ª desde a introdução do benchmark em 2018 — a plataforma de IA da Nvidia entregou o maior desempenho em escala em todos os benchmarks e alimentou todos os resultados submetidos no teste mais desafiador do benchmark, focado em grandes modelos de linguagem (LLM): pré-treinamento do Llama 3.1 405B.

A plataforma Nvidia foi a única que submeteu resultados em todos os benchmarks do MLPerf Training v5.0 — ressaltando seu desempenho excepcional e versatilidade em uma ampla gama de cargas de trabalho de IA, abrangendo LLMs, sistemas de recomendação, LLMs multimodais, detecção de objetos e redes neurais gráficas.
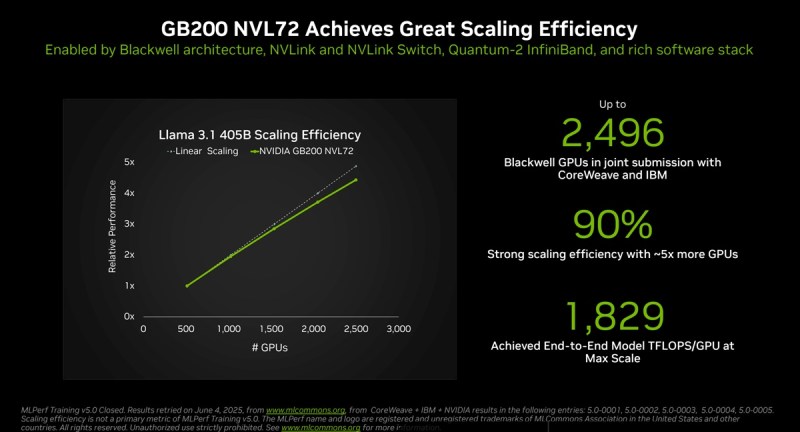
As submissões em grande escala utilizaram dois supercomputadores de IA alimentados pela plataforma Nvidia Blackwell: Tyche, construído com sistemas de rack Nvidia GB200 NVL72, e Nyx, baseado em sistemas Nvidia DGX B200. Além disso, a Nvidia colaborou com a CoreWeave e a IBM para enviar resultados do GB200 NVL72 usando um total de 2.496 GPUs Blackwell e 1.248 CPUs Nvidia Grace.
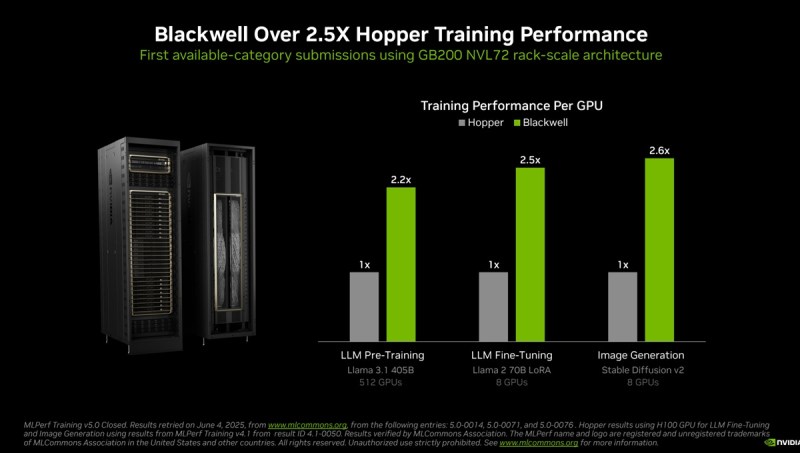
No novo benchmark de pré-treinamento Llama 3.1 405B, o Blackwell entregou um desempenho 2,2 vezes maior em comparação com a arquitetura da geração anterior na mesma escala.

No benchmark de ajuste fino Lora do Llama 2 70B, os sistemas Nvidia DGX B200, alimentados por oito GPUs Blackwell, entregaram 2,5 vezes mais desempenho em comparação com uma submissão usando o mesmo número de GPUs na rodada anterior.
Essas melhorias de desempenho destacam os avanços na arquitetura Blackwell, incluindo racks com resfriamento líquido de alta densidade, 13,4TB de memória coerente por rack, quinta geração de tecnologias de interconexão Nvidia NVLink e Nvidia NVLink Switch para escalonamento, e networking Nvidia Quantum-2 InfiniBand para expansão. Além disso, inovações no stack de software Nvidia NeMo Framework elevam o padrão para o treinamento de LLMs multimodais de próxima geração, fundamentais para levar aplicações de IA agente a mercado.
Essas aplicações com IA agente um dia funcionarão em fábricas de IA — os motores da economia de IA agente. Essas novas aplicações gerarão tokens e inteligência valiosa que podem ser aplicadas em quase todas as indústrias e domínios acadêmicos.
A plataforma de data center da Nvidia inclui GPUs, CPUs, tecidos de alta velocidade e networking, assim como uma vasta gama de softwares como as bibliotecas Nvidia CUDA-X, o NeMo Framework, Nvidia TensorRT-LLM e Nvidia Dynamo. Esse conjunto altamente ajustado de tecnologias de hardware e software capacita organizações a treinar e implantar modelos mais rapidamente, acelerando dramaticamente o tempo para gerar valor.
O ecossistema de parceiros da Nvidia participou extensivamente nesta rodada do MLPerf. Além da submissão com CoreWeave e IBM, outras submissões interessantes vieram de ASUS, Cisco, Giga Computing, Lambda, Lenovo Quanta Cloud Technology e Supermicro.
As primeiras submissões de MLPerf Training usando GB200 foram desenvolvidas pela Associação MLCommons com mais de 125 membros e afiliados. Sua métrica de tempo para treinar garante que o processo de treinamento produza um modelo que atenda à precisão exigida. E suas regras de execução padronizadas garantem comparações de desempenho justas. Os resultados são revisados por pares antes da publicação.
Os fundamentos sobre benchmarks de treinamento
Dave Salvator é alguém que eu conhecia quando fazia parte da imprensa de tecnologia. Agora ele é diretor de produtos de computação acelerada no Grupo de Computação Acelerada da Nvidia. Em um briefing à imprensa, Salvator observou que o CEO da Nvidia, Jensen Huang, fala sobre essa noção de leis de escalonamento para IA. Elas incluem pré-treinamento, onde você está essencialmente ensinando o modelo de IA. Isso começa do zero. É uma carga computacional pesada que é a espinha dorsal da IA, disse Salvator.
A partir daí, a Nvidia passa para o escalonamento pós-treinamento. Este é o lugar onde os modelos vão para a escola, e onde você pode fazer coisas como ajuste fino, por exemplo, onde traz um conjunto de dados diferente para ensinar um modelo pré-treinado que já foi treinado até um ponto, para fornecer um conhecimento adicional sobre seu conjunto de dados específico.

E por último, há o escalonamento de tempo-test ou raciocínio, ou às vezes chamado de IA agente. É a IA que pode realmente pensar, raciocinar e resolver problemas, onde você basicamente faz uma pergunta e obtém uma resposta relativamente simples. O escalonamento de teste de tempo e raciocínio pode, na verdade, trabalhar em tarefas muito mais complicadas e fornecer análises enriquecidas.
Além disso, há também a IA generativa, que pode gerar conteúdo conforme necessário, que pode incluir sumarização de texto, traduções, mas também conteúdo visual e até mesmo conteúdo de áudio. Existem muitos tipos de escalonamento que ocorrem no mundo da IA. Para os benchmarks, a Nvidia se concentrou nos resultados de pré-treinamento e pós-treinamento.
“É aqui que a IA começa o que chamamos de fase de investimento da IA. E quando você chega à inferência e implementa esses modelos e, em seguida, gera basicamente esses tokens, é aí que você começa a obter seu retorno sobre o investimento em IA,” disse ele.
O benchmark MLPerf está em sua 12ª rodada e remonta a 2018. O consórcio que o apoia tem mais de 125 membros e tem sido usado para testes de inferência e treinamento. A indústria vê os benchmarks como robustos.
“Como muitos de vocês sabem, às vezes as reivindicações de desempenho no mundo da IA podem ser um pouco como o Velho Oeste. O MLPerf busca trazer alguma ordem a esse caos,” afirmou Salvator. “Todos têm que realizar o mesmo esforço. Todos são mantidos ao mesmo padrão em termos de convergência. E uma vez que os resultados são submetidos, esses resultados são então revisados e verificados por todos os outros participantes, e as pessoas podem fazer perguntas e até contestar resultados.”
A métrica mais intuitiva em torno do treinamento é quanto tempo leva para treinar um modelo de IA até o que é chamado de convergência. Isso significa atingir um nível especificado de precisão. É uma comparação justa, disse Salvator, e leva em conta cargas de trabalho em constante mudança.
Este ano, há uma nova carga de trabalho Llama 3.140 5b, que substitui a carga de trabalho ChatGPT 170 5b que estava no benchmark anteriormente. Nos benchmarks, Salvator observou que a Nvidia teve vários recordes. As fábricas de IA Nvidia GB200 NVL72 estão fresquinhas das fábricas de fabricação. De uma geração de chips (Hopper) para a próxima (Blackwell), a Nvidia viu uma melhoria de 2,5 vezes nos resultados de geração de imagens.
“Ainda estamos relativamente no início do ciclo de vida do produto Blackwell, então esperamos obter mais desempenho com o tempo da arquitetura Blackwell, à medida que continuarmos a refinar nossas otimizações de software e à medida que novas cargas de trabalho, francamente mais pesadas, entram no mercado,” disse Salvator.
Ele observou que a Nvidia foi a única empresa a ter submetido entradas para todos os benchmarks.
“O grande desempenho que estamos alcançando vem de uma combinação de fatores. É nossa quinta geração de NVLink e NVSwitch entregando até 2,66 vezes mais desempenho, juntamente com outras melhorias arquitetônicas na Blackwell, além de nossas contínuas otimizações de software que tornam esse desempenho possível,” afirmou Salvator.
Ele acrescentou: “Devido à herança da Nvidia, fomos conhecidos por muito tempo como os caras das GPUs. Certamente fabricamos ótimas GPUs, mas passamos de ser apenas uma empresa de chips para não apenas ser uma empresa de sistemas com nossos servidores DGX, mas agora construindo racks inteiros e data centers com designs de racks, que agora são designs de referência para ajudar nossos parceiros a chegarem ao mercado mais rápido, até construir data centers inteiros, que, em última análise, constroem toda a infraestrutura, que agora nos referimos como fábricas de IA. Tem sido realmente uma jornada muito interessante.”

Conteúdo relacionado

A Amazon lança novo grupo de P&D focado em IA agentiva e robótica.
[the_ad id="145565"] A gigante da tecnologia Amazon planeja lançar um novo grupo dentro de sua divisão de produtos de consumo que se concentrará em IA agentiva. A Amazon…

Perplexity recebeu 780 milhões de consultas no mês passado, diz CEO.
[the_ad id="145565"] Perplexity recebeu 780 milhões de consultas em maio, compartilhou o CEO Aravind Srinivas no palco da Cúpula de Tecnologia da Bloomberg na quinta-feira.…

A Anysphere da Cursor atinge uma avaliação de $9,9 bilhões e supera $500 milhões em ARR.
[the_ad id="145565"] A Anysphere, fabricante do assistente de codificação AI Cursor, arrecadou US$ 900 milhões com uma avaliação de US$ 9,9 bilhões, reportou a Bloomberg. A…