


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder na indústria. Saiba mais
As empresas precisam saber se os modelos que alimentam suas aplicações e agentes funcionam em cenários da vida real. Essa avaliação pode ser complexa, pois é difícil prever cenários específicos. Uma versão reformulada do benchmark RewardBench busca dar às organizações uma melhor ideia do desempenho real de um modelo.
O Instituto Allen de IA (Ai2) lançou o RewardBench 2, uma versão atualizada de seu benchmark de modelo de recompensa, RewardBench, que eles afirmam fornecer uma visão mais holística do desempenho do modelo e avaliar como os modelos se alinham com os objetivos e padrões de uma empresa.
A Ai2 construiu o RewardBench com tarefas de classificação que medem correlações por meio de computação em tempo de inferência e treinamento posterior. O RewardBench lida principalmente com modelos de recompensa (RM), que podem atuar como juízes e avaliar as saídas de LLM. Os RMs atribuem uma pontuação ou uma “recompensa” que orienta o aprendizado por reforço com feedback humano (RHLF).
Nathan Lambert, um cientista sênior de pesquisa na Ai2, disse ao VentureBeat que o primeiro RewardBench funcionou como pretendido quando foi lançado. No entanto, o ambiente do modelo evoluiu rapidamente, e os benchmarks também deveriam.
“À medida que os modelos de recompensa se tornaram mais avançados e os casos de uso mais sutis, reconhecemos rapidamente com a comunidade que a primeira versão não capturava totalmente a complexidade das preferências humanas no mundo real”, afirmou.
Lambert acrescentou que, com o RewardBench 2, “buscamos melhorar tanto a amplitude quanto a profundidade da avaliação—incorporando prompts mais diversos e desafiadores e refinando a metodologia para refletir melhor como os humanos realmente julgam as saídas da IA na prática.” Ele declarou que a segunda versão usa prompts humanos não vistos, possui uma configuração de pontuação mais desafiadora e novos domínios.
Usando avaliações para modelos que avaliam
Enquanto os modelos de recompensa testam quão bem os modelos funcionam, também é importante que os RMs estejam alinhados com os valores da empresa; do contrário, o processo de ajuste fino e aprendizado por reforço pode reforçar comportamentos indesejados, como alucinações, reduzir a generalização e pontuar respostas prejudiciais de forma exagerada.
O RewardBench 2 cobre seis domínios diferentes: factualidade, seguir instruções precisas, matemática, segurança, foco e laços.
“As empresas devem usar o RewardBench 2 de duas maneiras diferentes, dependendo de sua aplicação. Se estiverem realizando RLHF por conta própria, devem adotar as melhores práticas e conjuntos de dados dos modelos líderes em seus próprios fluxos, porque os modelos de recompensa precisam de receitas de treinamento em política (ou seja, modelos de recompensa que espelham o modelo que estão tentando treinar com RL). Para escalabilidade em tempo de inferência ou filtragem de dados, o RewardBench 2 mostrou que podem selecionar o melhor modelo para seu domínio e observar um desempenho correlacionado,” disse Lambert.
Lambert observou que benchmarks como o RewardBench oferecem aos usuários uma maneira de avaliar os modelos que estão escolhendo com base nas “dimensões que mais importam para eles, em vez de depender de uma pontuação padronizada e restrita.” Ele afirmou que a ideia de desempenho, que muitos métodos de avaliação afirmam avaliar, é muito subjetiva, pois uma boa resposta de um modelo depende muito do contexto e dos objetivos do usuário. Ao mesmo tempo, as preferências humanas são bastante sutis.
A Ai2 lançou a primeira versão do RewardBench em março de 2024. Na ocasião, a empresa disse que era o primeiro benchmark e leaderboard para modelos de recompensa. Desde então, vários métodos para benchmarking e melhoria de RM surgiram. Pesquisadores do FAIR da Meta lançaram o reWordBench. DeepSeek lançou uma nova técnica chamada Tuning de Crítica Autoprincipiada para um RM mais inteligente e escalável.
Desempenho dos modelos
Dado que o RewardBench 2 é uma versão atualizada do RewardBench, a Ai2 testou tanto modelos existentes quanto recém-treinados para ver se continuam a ter um bom desempenho. Isso incluiu uma variedade de modelos, como versões do Gemini, Claude, GPT-4.1 e Llama-3.1, juntamente com conjuntos de dados e modelos como Qwen, Skywork e seu próprio Tulu.
A empresa descobriu que modelos de recompensa maiores apresentam melhor desempenho no benchmark porque seus modelos base são mais fortes. No geral, os modelos com melhor desempenho são variantes do Llama-3.1 Instruct. Em termos de foco e segurança, os dados do Skywork “são particularmente úteis”, e o Tulu se destacou em factualidade.
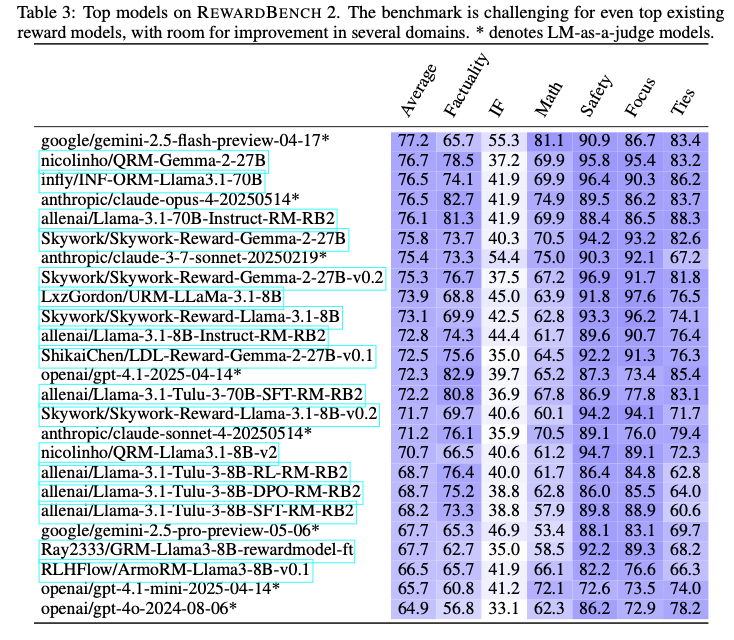
A Ai2 afirmou que, embora acreditem que o RewardBench 2 “é um avanço na avaliação de precisão ampla e multi-domínio” para modelos de recompensa, alertaram que a avaliação de modelos deve ser usada principalmente como um guia para escolher modelos que funcionem melhor com as necessidades de uma empresa.


Conteúdo relacionado

A Amazon lança novo grupo de P&D focado em IA agentiva e robótica.
[the_ad id="145565"] A gigante da tecnologia Amazon planeja lançar um novo grupo dentro de sua divisão de produtos de consumo que se concentrará em IA agentiva. A Amazon…

Perplexity recebeu 780 milhões de consultas no mês passado, diz CEO.
[the_ad id="145565"] Perplexity recebeu 780 milhões de consultas em maio, compartilhou o CEO Aravind Srinivas no palco da Cúpula de Tecnologia da Bloomberg na quinta-feira.…

A Anysphere da Cursor atinge uma avaliação de $9,9 bilhões e supera $500 milhões em ARR.
[the_ad id="145565"] A Anysphere, fabricante do assistente de codificação AI Cursor, arrecadou US$ 900 milhões com uma avaliação de US$ 9,9 bilhões, reportou a Bloomberg. A…