


Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba mais
Modelos de linguagem grandes (LLMs) estão transformando a forma como as empresas operam, mas sua natureza “caixa preta” frequentemente deixa as organizações lutando contra a imprevisibilidade. Para enfrentar esse desafio crítico, Anthropic recentemente tornou de código aberto sua ferramenta de rastreamento de circuitos, permitindo que desenvolvedores e pesquisadores compreendam e controlem diretamente o funcionamento interno dos modelos.
Esta ferramenta permite que os investigadores analisem erros inexplicáveis e comportamentos inesperados em modelos de pesos abertos. Ela também pode ajudar na afinação granular de LLMs para funções internas específicas.
Entendendo a lógica interna da IA
Essa ferramenta de rastreamento de circuitos funciona com base na “interpretabilidade mecanicista”, um campo crescente dedicado a entender como os modelos de IA funcionam a partir de suas ativações internas, em vez de apenas observar suas entradas e saídas.
Enquanto a pesquisa inicial da Anthropic sobre rastreamento de circuitos aplicou essa metodologia ao seu próprio modelo Claude 3.5 Haiku, a ferramenta de código aberto estende essa capacidade a modelos de pesos abertos. A equipe da Anthropic já utilizou a ferramenta para rastrear circuitos em modelos como Gemma-2-2b e Llama-3.2-1b e lançou um notebook Colab que ajuda a usar a biblioteca em modelos abertos.
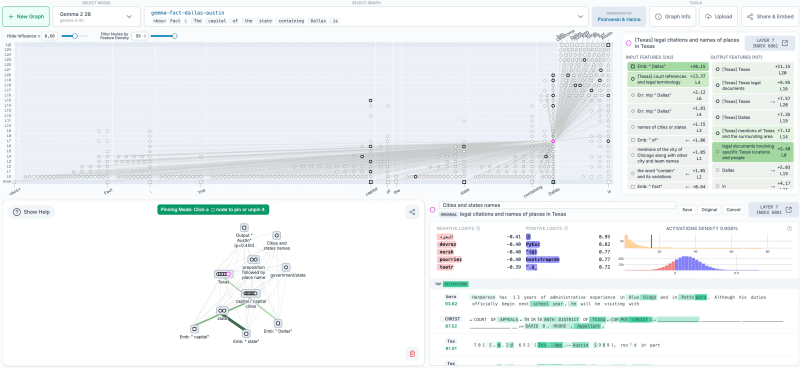
No cerne da ferramenta está a geração de gráficos de atribuição, mapas causais que rastreiam as interações entre características à medida que o modelo processa informações e gera saídas. (As características são padrões de ativação interna do modelo que podem ser vagamente mapeados para conceitos compreensíveis.) É como obter um diagrama detalhado da fiação do processo de pensamento interno da IA. Mais importante ainda, a ferramenta permite “experimentos de intervenção”, permitindo que pesquisadores modifiquem diretamente essas características internas e observem como as mudanças nos estados internos da IA impactam suas respostas externas, tornando possível depurar modelos.
A ferramenta integra-se ao Neuronpedia, uma plataforma aberta para compreensão e experimentação com redes neurais.
Práticas e impacto futuro para IA empresarial
A ferramenta de rastreamento de circuitos da Anthropic é um grande passo em direção à IA explicável e controlável, mas enfrenta desafios práticos, incluindo altos custos de memória associados à execução da ferramenta e a complexidade inerente à interpretação dos gráficos de atribuição detalhados.
No entanto, esses desafios são típicos de pesquisas de ponta. A interpretabilidade mecanicista é uma grande área de pesquisa, e a maioria dos grandes laboratórios de IA está desenvolvendo modelos para investigar o funcionamento interno dos modelos de linguagem grandes. Ao abrir o código da ferramenta de rastreamento de circuitos, a Anthropic permitirá que a comunidade desenvolva ferramentas de interpretabilidade que sejam mais escaláveis, automatizadas e acessíveis a um público mais amplo, abrindo caminho para aplicações práticas de todo o esforço que está sendo investido na compreensão dos LLMs.
À medida que as ferramentas amadurecem, a capacidade de entender por que um LLM toma uma certa decisão pode se traduzir em benefícios práticos para as empresas.
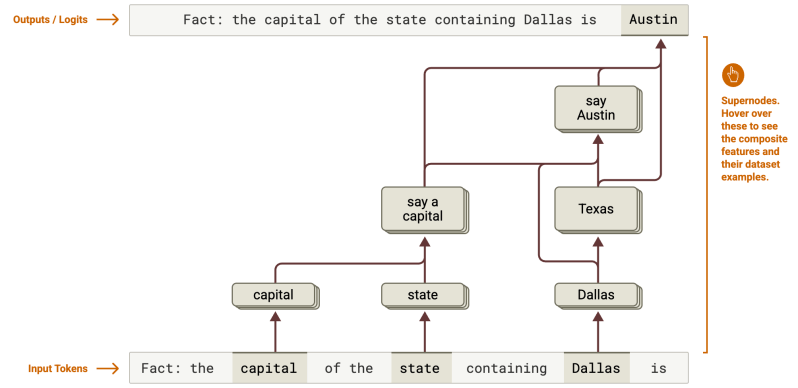
O rastreamento de circuitos explica como os LLMs realizam raciocínios complexos em várias etapas. Por exemplo, em seu estudo, os pesquisadores conseguiram rastrear como um modelo inferiu “Texas” a partir de “Dallas” antes de chegar a “Austin” como a capital. Também revelou mecanismos de planejamento avançados, como um modelo pré-selecionando palavras que rimam em um poema para guiar a composição de linhas. As empresas podem usar esses insights para analisar como seus modelos enfrentam tarefas complexas, como análise de dados ou raciocínio legal. Identificar etapas internas de planejamento ou raciocínio permite uma otimização direcionada, melhorando a eficiência e a precisão em processos comerciais complexos.
Além disso, o rastreamento de circuitos oferece uma melhor clareza sobre operações numéricas. Por exemplo, em seu estudo, os pesquisadores descobriram como os modelos lidam com aritmética, como 36+59=95, não por meio de algoritmos simples, mas através de caminhos paralelos e recursos de “tabela de consulta” para dígitos. As empresas podem usar tais insights para auditar cálculos internos que levam a resultados numéricos, identificar a origem de erros e implementar correções direcionadas para garantir a integridade dos dados e a precisão dos cálculos dentro de seus LLMs de código aberto.
Para implementações globais, a ferramenta fornece insights sobre consistência multilíngue. A pesquisa anterior da Anthropic mostra que os modelos utilizam circuitos tanto específicos de linguagem quanto circuitos “universais não dependentes de linguagem”, com modelos maiores demonstrando maior generalização. Isso pode potencialmente ajudar a solucionar desafios de localização ao implantar modelos em diferentes idiomas.
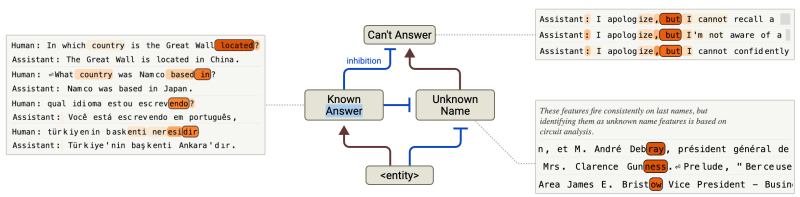
Por fim, a ferramenta pode ajudar a combater alucinações e melhorar a fundamentação factual. A pesquisa revelou que os modelos têm “circuitos de recusa padrão” para consultas desconhecidas, que são suprimidos por recursos de “resposta conhecida”. Alucinações podem ocorrer quando este circuito inibidor “dispara incorretamente”.
A compreensão mecanicista desbloqueia novas avenidas para afinar LLMs. Em vez de meramente ajustar o comportamento de saída por tentativas e erros, as empresas podem identificar e direcionar os mecanismos internos específicos que impulsionam atributos desejados ou indesejados. Por exemplo, compreender como a “persona Assistente” de um modelo incorpora inadvertidamente preconceitos de modelo de recompensa ocultos, como mostrado na pesquisa da Anthropic, permite que os desenvolvedores reajustem precisamente os circuitos internos responsáveis pelo alinhamento, levando a implantações de IA mais robustas e eticamente consistentes.
À medida que os LLMs se integram cada vez mais em funções empresariais críticas, sua transparência, interpretabilidade e controle se tornam cada vez mais essenciais. Esta nova geração de ferramentas pode ajudar a preencher a lacuna entre as poderosas capacidades da IA e a compreensão humana, construindo confiança fundamental e garantindo que as empresas possam implantar sistemas de IA que sejam confiáveis, auditáveis e alinhados com seus objetivos estratégicos.


Conteúdo relacionado

Google afirma que a prévia do Gemini 2.5 Pro supera o DeepSeek R1 e o Grok 3 Beta em desempenho de programação.
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira…

AMD contrata os funcionários por trás da Untether AI
[the_ad id="145565"] A AMD continua sua onda de aquisições. A gigante de semicondutores AMD adquiriu a equipe por trás da Untether AI, uma startup que desenvolve chips de…

Chefe de marketing da OpenAI se afasta para tratar câncer de mama.
[the_ad id="145565"] A chefe de marketing da OpenAI, Kate Rouch, anunciou que estará se afastando de sua função por três meses enquanto passa por tratamento para câncer de mama…