


Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne as pessoas que estão construindo uma verdadeira estratégia de IA empresarial. Saiba mais
Um novo framework de pesquisadores da Universidade de Illinois, Urbana-Champaign e Universidade da Califórnia, Berkeley oferece aos desenvolvedores mais controle sobre como modelos de linguagem de grande escala (LLMs) “pensam”, melhorando suas capacidades de raciocínio e utilizando de forma mais eficiente o seu orçamento de inferência.
O framework, chamado AlphaOne (α1), é uma técnica de escalonamento em tempo de teste, ajustando o comportamento de um modelo durante a inferência sem a necessidade de retrainings dispendiosos. Ele fornece um método universal para modular o processo de raciocínio de LLMs avançados, oferecendo aos desenvolvedores flexibilidade para melhorar o desempenho em tarefas complexas de uma maneira mais controlada e econômica do que as abordagens existentes.
O desafio do pensamento lento
Nos últimos anos, desenvolvedores de grandes modelos de raciocínio (LRMs), como OpenAI o3 e DeepSeek-R1, incorporaram mecanismos inspirados pelo “Sistema 2” de pensamento—o modo lento, deliberado e lógico da cognição humana. Isso se distingue do “Sistema 1”, que é rápido, intuitivo e automático. Incorporar capacidades do Sistema 2 permite que modelos resolvam problemas complexos em domínios como matemática, codificação e análise de dados.
Os modelos são treinados para gerar automaticamente tokens de transição como “esperar”, “hum” ou “alternativamente” para ativar o pensamento lento. Quando um desses tokens aparece, o modelo faz uma pausa para se auto-refletir sobre os passos anteriores e corrigir seu curso, muito parecido com uma pessoa que pausa para repensar um problema difícil.
No entanto, os modelos de raciocínio nem sempre utilizam suas capacidades de pensamento lento de forma eficaz. Estudos diferentes mostram que eles tendem a “pensar demais” em problemas simples, desperdiçando recursos computacionais, ou “pensar de menos” em problemas complexos, levando a respostas incorretas.
Como observa o artigo do AlphaOne, “Isso se deve à incapacidade dos LRMs de encontrar a transição ideal de raciocínio de sistema-1-para-2 e capacidades limitadas de raciocínio, resultando em um desempenho de raciocínio insatisfatório.”
Existem dois métodos comuns para abordar isso. O escalonamento paralelo, como a abordagem “best-of-N”, executa um modelo várias vezes e seleciona a melhor resposta, o que é dispendioso em termos computacionais. O escalonamento sequencial tenta modular o processo de pensamento durante uma única execução. Por exemplo, s1 é uma técnica que força mais raciocínio lento ao adicionar tokens “esperar” no contexto do modelo, enquanto o método “Chain of Draft” (CoD) orienta o modelo a usar menos palavras, reduzindo assim seu orçamento de pensamento. Esses métodos, no entanto, oferecem soluções rígidas, de tamanho único, que muitas vezes são ineficientes.
Um framework universal para raciocínio
Em vez de simplesmente aumentar ou reduzir o orçamento de pensamento, os pesquisadores do AlphaOne fizeram uma pergunta mais fundamental: É possível desenvolver uma estratégia melhor para transitar entre pensamento lento e rápido que possa modular orçamentos de raciocínio de forma universal?
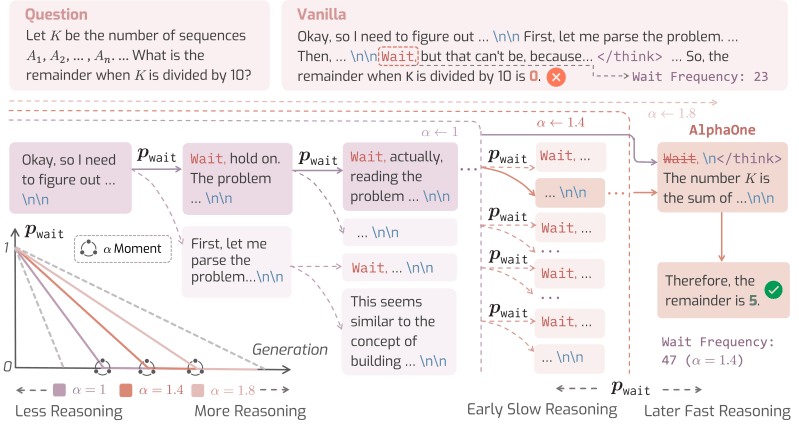
O seu framework, AlphaOne, dá aos desenvolvedores controle detalhado sobre o processo de raciocínio do modelo em tempo de teste. O sistema funciona introduzindo Alpha (α), um parâmetro que atua como um dial para escalar o orçamento da fase de pensamento do modelo.
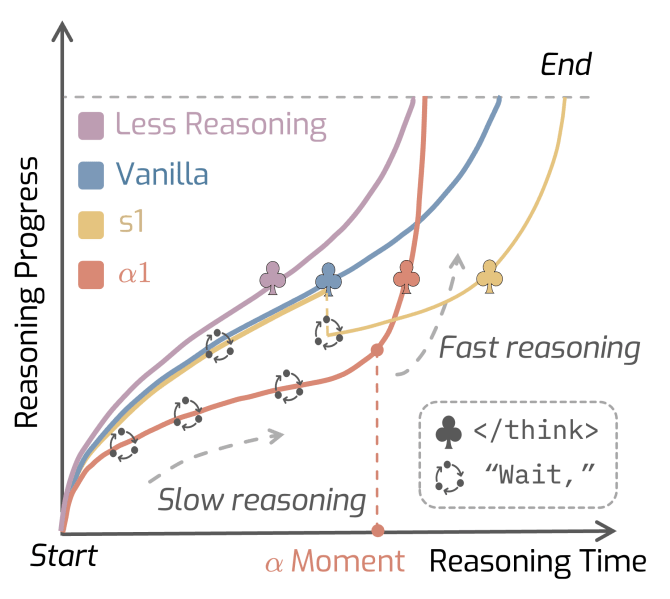
Antes de um certo ponto na geração, que os pesquisadores chamam de “momento α”, o AlphaOne agenda estrategicamente a frequência de inserção de um token “esperar” para incentivar um pensamento lento e deliberado. Isso permite o que o artigo descreve como “pensamento controlável e escalável”.
Uma vez que o “momento α” é alcançado, o framework insere um token no contexto do modelo, encerrando o processo de pensamento lento e forçando o modelo a mudar para o raciocínio rápido e produzir sua resposta final.
Técnicas anteriores tipicamente aplicavam o que os pesquisadores chamam de “modulação esparsa”, fazendo apenas alguns ajustes isolados, como adicionar um token “esperar” uma ou duas vezes durante todo o processo. O AlphaOne, em contraste, pode ser configurado para intervir com frequência (densa) ou raramente (esparsa), dando aos desenvolvedores mais controle granular do que outros métodos.
“Vemos o AlphaOne como uma interface unificada para raciocínio deliberado, complementar ao prompting em cadeia de pensamentos ou ajuste baseado em preferências, e capaz de evoluir junto com as arquiteturas de modelos”, disse a equipe do AlphaOne ao VentureBeat em comentários por escrito. “A grande conclusão não está amarrada a detalhes de implementação, mas sim ao princípio geral: a modulação estruturada de pensamento lento para rápido do processo de raciocínio aprimora a capacidade e a eficiência.”
AlphaOne em ação
Os pesquisadores testaram o AlphaOne em três modelos diferentes de raciocínio, com tamanhos de parâmetros variando de 1,5 bilhão a 32 bilhões. Eles avaliaram seu desempenho em seis benchmarks desafiadores em matemática, geração de código e resolução de problemas científicos.
Compararam o AlphaOne contra três baselines: o modelo original, não modificado; o método s1 que aumenta monotonamente o pensamento lento; e o método Chain of Draft (CoD) que o diminui monotonamente.
Os resultados produziram várias descobertas-chave que são particularmente relevantes para desenvolvedores que constroem aplicações de IA.
Primeiro, uma estratégia de “pensar lentamente primeiro, depois rapidamente” leva a um melhor desempenho de raciocínio em LRMs. Isso destaca uma lacuna fundamental entre LLMs e a cognição humana, que geralmente é estruturada com base no pensamento rápido seguido pelo pensamento lento. Ao contrário dos humanos, os pesquisadores descobriram que modelos se beneficiam de um pensamento lento imposto antes de agir rapidamente.
“Isso sugere que raciocínio eficaz em IA não surge da imitação de especialistas humanos, mas da modulação explícita da dinâmica de raciocínio, o que está alinhado com práticas como engenharia de prompts e inferência em estágios já utilizadas em aplicações do mundo real”, disse a equipe do AlphaOne. “Para os desenvolvedores, isso significa que o design do sistema deve impor ativamente um cronograma de raciocínio lento-para-rápido para melhorar o desempenho e a confiabilidade, pelo menos por enquanto, enquanto o raciocínio dos modelos permanece imperfeito.”
Outra descoberta interessante foi que investir em pensamento lento pode levar a uma inferência mais eficiente em geral. “Embora o pensamento lento desacelere o raciocínio, o comprimento total de tokens é significativamente reduzido com α1, induzindo um progresso de raciocínio mais informativo trazido pelo pensamento lento”, afirma o artigo. Isso significa que, embora o modelo demore mais para “pensar”, ele produz um caminho de raciocínio mais conciso e preciso, reduzindo, em última análise, o número total de tokens gerados e diminuindo os custos de inferência.
Comparado aos baselines do tipo s1, o AlphaOne reduz o uso médio de tokens em ~21%, resultando em menor sobrecarga computacional, ao mesmo tempo que aumenta a precisão do raciocínio em 6,15%, mesmo em problemas de matemática, ciência e código de nível de doutorado.
“Para aplicações empresariais como resposta a consultas complexas ou geração de código, esses ganhos se traduzem em um benefício duplo: qualidade de geração aprimorada e economias significativas de custos”, disse o AlphaOne. “Isso pode levar a menores custos de inferência enquanto melhora as taxas de sucesso em tarefas e a satisfação do usuário.”
Por fim, o estudo descobriu que inserir tokens “esperar” com alta frequência é útil, com o AlphaOne alcançando melhores resultados ao anexar o token muito mais frequentemente do que métodos anteriores.
Ao fornecer aos desenvolvedores um novo nível de controle, o framework AlphaOne, cujo código deve ser lançado em breve, pode ajudá-los a criar aplicações mais estáveis, confiáveis e eficientes sobre a próxima geração de modelos de raciocínio.
“Para empresas que usam modelos de código aberto ou personalizados, especialmente aqueles treinados com tokens de transição durante a fase de pré-treinamento, o AlphaOne foi projetado para ser fácil de integrar”, disse a equipe do AlphaOne ao VentureBeat. “Na prática, a integração geralmente requer alterações mínimas, como simplesmente atualizar o nome do modelo nos scripts de configuração.”


Conteúdo relacionado

DeepCoder-14B: O Modelo de IA Open Source que Aumenta a Produtividade e Inovação dos Desenvolvedores
[the_ad id="145565"] A Inteligência Artificial (IA) está mudando a forma como o software é desenvolvido. Geradores de código impulsionados por IA tornaram-se ferramentas…

Os modelos de raciocínio realmente pensam ou não? Pesquisa da Apple gera um debate acalorado.
[the_ad id="145565"] Participe do evento confiável pelos líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que constroem uma verdadeira estratégia de IA…

Além da arquitetura GPT: Por que a abordagem de Difusão do Google pode redefinir a implementação de LLMs
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira estratégia…