


Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira estratégia de IA empresarial. Saiba mais
No mês passado, juntamente com uma suite abrangente de novas ferramentas e inovações de IA, Google DeepMind revelou Gemini Diffusion. Este modelo de pesquisa experimental utiliza uma abordagem baseada em difusão para gerar texto. Tradicionalmente, grandes modelos de linguagem (LLMs), como o GPT e o próprio Gemini, têm dependido da autoregressão, uma abordagem passo a passo onde cada palavra é gerada com base na anterior. Modelos de linguagem de difusão (DLMs), também conhecidos como grandes modelos de linguagem baseados em difusão (dLLMs), empregam um método mais comum em geração de imagens, começando com ruído aleatório e refinando-o gradualmente em um resultado coerente. Essa abordagem aumenta drasticamente a velocidade de geração e pode melhorar a coerência e a consistência.
O Gemini Diffusion está atualmente disponível como uma demonstração experimental; inscreva-se na lista de espera aqui para obter acesso.
(Nota do editor: Vamos explorar mudanças de paradigma como modelos de linguagem baseados em difusão—e o que é necessário para operá-los em produção—no VB Transform, de 24 a 25 de junho em São Francisco, ao lado do Google DeepMind, LinkedIn e outros líderes em IA empresarial.)
Entendendo difusão vs. autoregressão
A difusão e a autoregressão são abordagens fundamentalmente diferentes. A abordagem autoregressiva gera texto sequencialmente, com tokens previstos um de cada vez. Embora esse método assegure uma forte coerência e rastreamento de contexto, pode ser intensivo em computação e lento, especialmente para conteúdo longo.
Modelos de difusão, em contrapartida, começam com ruído aleatório, que é gradualmente denoiseado em um output coerente. Quando aplicado à linguagem, a técnica tem várias vantagens. Blocos de texto podem ser processados em paralelo, potencialmente produzindo segmentos inteiros ou sentenças a uma taxa muito maior.
O Gemini Diffusion pode gerar, segundo relatos, de 1.000 a 2.000 tokens por segundo. Em contraste, o Gemini 2.5 Flash tem uma velocidade média de saída de 272,4 tokens por segundo. Além disso, erros na geração podem ser corrigidos durante o processo de refinamento, melhorando a precisão e reduzindo o número de alucinações. Pode haver trade-offs em termos de precisão fina e controle em nível de token; no entanto, o aumento de velocidade será uma mudança radical para inúmeras aplicações.
Como funciona a geração de texto baseada em difusão?
Durante o treinamento, os DLMs corrompem gradualmente uma frase com ruído ao longo de muitas etapas, até que a frase original se torne completamente irreconhecível. O modelo é então treinado para reverter esse processo, etapa por etapa, reconstruindo a frase original a partir de versões cada vez mais barulhentas. Através do refinamento iterativo, ele aprende a modelar toda a distribuição de frases plausíveis nos dados de treinamento.
Embora os detalhes do Gemini Diffusion ainda não tenham sido divulgados, a metodologia de treinamento típica para um modelo de difusão envolve estas etapas principais:
Difusão direta: Com cada amostra no conjunto de dados de treinamento, o ruído é adicionado progressivamente ao longo de múltiplos ciclos (normalmente de 500 a 1.000) até que se torne indistinguível do ruído aleatório.
Difusão reversa: O modelo aprende a reverter cada etapa do processo de adição de ruído, essencialmente aprendendo como “denoisear” uma frase corrompida uma etapa de cada vez, restaurando eventualmente a estrutura original.
Esse processo é repetido milhões de vezes com amostras diversas e níveis de ruído, permitindo que o modelo aprenda uma função de denoise confiável.
Uma vez treinado, o modelo é capaz de gerar frases completamente novas. Os DLMs geralmente requerem uma condição ou input, como um prompt, rótulo de classe ou embedding, para guiar a geração em direção a resultados desejados. A condição é injetada em cada etapa do processo de denoise, que molda uma blob inicial de ruído em texto estruturado e coerente.
Vantagens e desvantagens dos modelos baseados em difusão
Em uma entrevista ao VentureBeat, Brendan O’Donoghue, cientista de pesquisa da Google DeepMind e um dos líderes do projeto Gemini Diffusion, elaborou algumas das vantagens das técnicas baseadas em difusão em comparação com a autoregressão. Segundo O’Donoghue, as principais vantagens das técnicas de difusão são as seguintes:
- Menores latências: Modelos de difusão podem produzir uma sequência de tokens em muito menos tempo do que modelos autoregressivos.
- Cálculo adaptável: Modelos de difusão convergem para uma sequência de tokens em taxas diferentes dependendo da dificuldade da tarefa. Isso permite que o modelo consuma menos recursos (e tenha latências menores) em tarefas fáceis e mais em tarefas mais difíceis.
- Raciocínio não causal: Devido à atenção bidirecional no denoiseador, tokens podem considerar futuros tokens dentro do mesmo bloco de geração. Isso permite que o raciocínio não causal ocorra e possibilita que o modelo faça edições globais dentro de um bloco para produzir texto mais coerente.
- Refinamento iterativo / autocorreção: O processo de denoise envolve amostragem, o que pode introduzir erros como em modelos autoregressivos. No entanto, ao contrário dos modelos autoregressivos, os tokens são passados de volta para o denoiseador, que então tem a oportunidade de corrigir o erro.
O’Donoghue também observou as principais desvantagens: “custo mais alto de serviço e um tempo de espera para o primeiro token (TTFT) ligeiramente maior, uma vez que os modelos autoregressivos produzem o primeiro token imediatamente. Para a difusão, o primeiro token só pode aparecer quando toda a sequência de tokens estiver pronta.”
Referências de desempenho
O Google afirma que o desempenho do Gemini Diffusion é comparável ao Gemini 2.0 Flash-Lite.
| Benchmark | Tipo | Gemini Diffusion | Gemini 2.0 Flash-Lite |
|---|---|---|---|
| LiveCodeBench (v6) | Código | 30.9% | 28.5% |
| BigCodeBench | Código | 45.4% | 45.8% |
| LBPP (v2) | Código | 56.8% | 56.0% |
| SWE-Bench Verified* | Código | 22.9% | 28.5% |
| HumanEval | Código | 89.6% | 90.2% |
| MBPP | Código | 76.0% | 75.8% |
| GPQA Diamond | Ciência | 40.4% | 56.5% |
| AIME 2025 | Matemática | 23.3% | 20.0% |
| BIG-Bench Extra Hard | Raciocínio | 15.0% | 21.0% |
| Global MMLU (Lite) | Multilíngue | 69.1% | 79.0% |
* Avaliação não agente (apenas edição de turno único), comprimento máximo do prompt de 32K.
Os dois modelos foram comparados usando vários benchmarks, com as pontuações baseadas em quantas vezes o modelo produziu a resposta correta na primeira tentativa. O Gemini Diffusion teve um bom desempenho em testes de codificação e matemática, enquanto o Gemini 2.0 Flash-lite teve a vantagem em raciocínio, conhecimento científico e capacidades multilíngues.
À medida que o Gemini Diffusion evolui, não há razão para pensar que seu desempenho não alcance o de modelos mais estabelecidos. Segundo O’Donoghue, a diferença entre as duas técnicas está “basicamente fechada em termos de desempenho no benchmark, pelo menos nos tamanhos relativamente pequenos que escalamos. Na verdade, pode haver alguma vantagem de desempenho para a difusão em alguns domínios onde a consistência não local é importante, por exemplo, codificação e raciocínio.”
Testando o Gemini Diffusion
O VentureBeat teve acesso à demonstração experimental. Ao colocar o Gemini Diffusion à prova, a primeira coisa que notamos foi a velocidade. Ao executar os prompts sugeridos fornecidos pelo Google, incluindo a construção de aplicativos HTML interativos como Xylophone e Planet Tac Toe, cada solicitação foi concluída em menos de três segundos, com velocidades variando de 600 a 1.300 tokens por segundo.
Para testar seu desempenho em uma aplicação do mundo real, pedimos ao Gemini Diffusion para construir uma interface de chat por vídeo com o seguinte prompt:
Construa uma interface para um aplicativo de chat por vídeo. Deve ter uma janela de pré-visualização que acesse a câmera do meu dispositivo e exiba sua saída. A interface também deve ter um medidor de nível de som que mede a saída do microfone do dispositivo em tempo real.Em menos de dois segundos, o Gemini Diffusion criou uma interface funcional com pré-visualização de vídeo e um medidor de áudio.
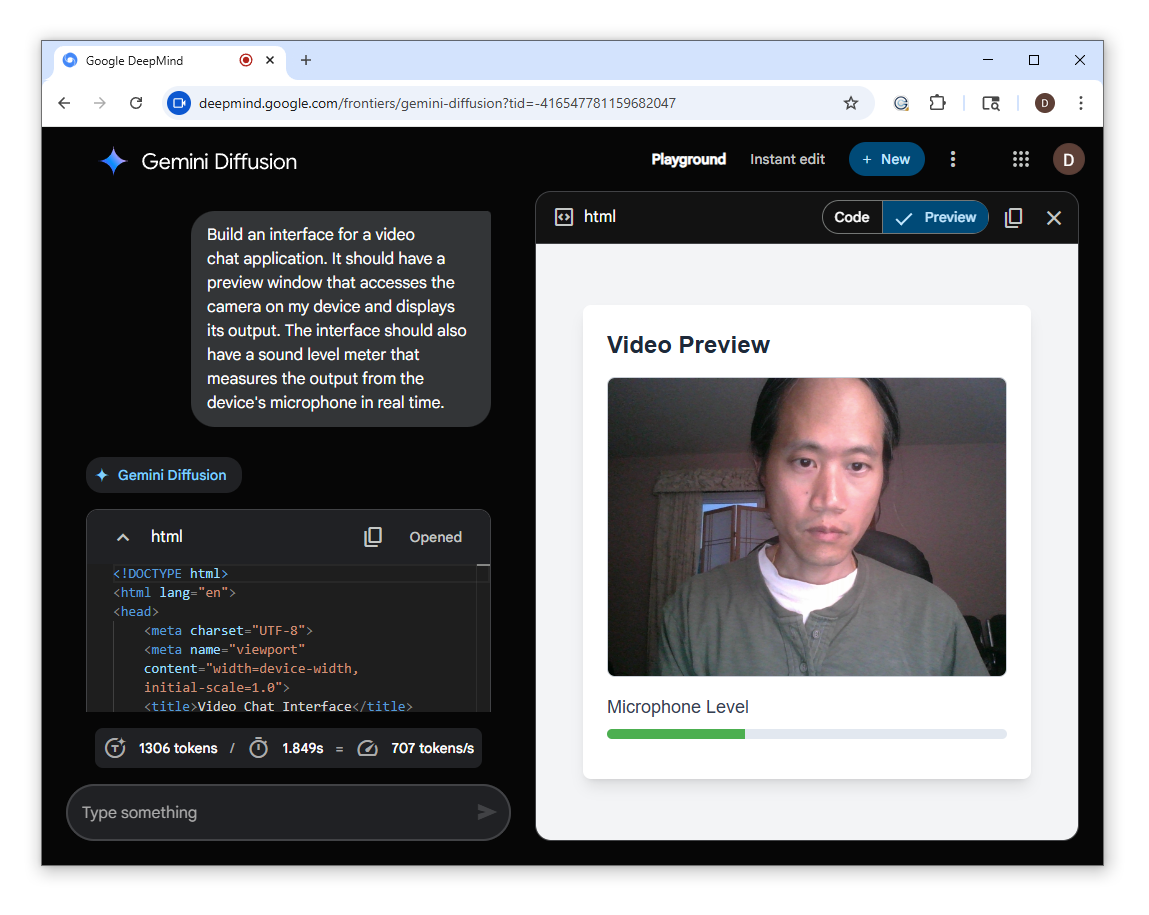
Embora esta não tenha sido uma implementação complexa, pode ser o início de um MVP que pode ser finalizado com mais alguns prompts. Observe que o Gemini 2.5 Flash também produziu uma interface funcional, embora a uma velocidade ligeiramente mais lenta (aproximadamente sete segundos).
O Gemini Diffusion também apresenta o modo “Edição Instantânea”, onde texto ou código podem ser colados e editados em tempo real com um mínimo de prompting. A Edição Instantânea é eficaz para muitos tipos de edição de texto, incluindo correção de gramática, atualização de texto para direcionar diferentes personas de leitor ou adição de palavras-chave para SEO. Também é útil para tarefas como refatoração de código, adição de novos recursos a aplicativos ou conversão de uma base de código existente para uma linguagem diferente.
Casos de uso corporativos para DLMs
É seguro afirmar que qualquer aplicação que exija um tempo de resposta rápido se beneficiará da tecnologia DLM. Isso inclui aplicações em tempo real e de baixa latência, como IA conversacional e chatbots, transcrição e tradução ao vivo, ou autocompletar IDE e assistentes de codificação.
Segundo O’Donoghue, com aplicações que aproveitam “edição in-line, por exemplo, pegando um pedaço de texto e fazendo algumas alterações no local, os modelos de difusão são aplicáveis de maneiras que os modelos autoregressivos não são.” Os DLMs também têm uma vantagem com problemas de raciocínio, matemática e codificação, devido ao “raciocínio não causal proporcionado pela atenção bidirecional.”
Os DLMs ainda estão em sua infância; no entanto, a tecnologia pode transformar potencialmente como os modelos de linguagem são construídos. Não apenas geram texto a uma taxa muito mais alta do que os modelos autoregressivos, mas sua capacidade de voltar e corrigir erros significa que, eventualmente, eles também podem produzir resultados com maior precisão.
O Gemini Diffusion entra em um ecossistema crescente de DLMs, com dois exemplos notáveis sendo Mercury, desenvolvido pela Inception Labs, e LLaDa, um modelo open-source da GSAI. Juntos, esses modelos refletem o crescente impulso por trás da geração de linguagem baseada em difusão e oferecem uma alternativa escalável e paralelizável às arquiteturas autoregressivas tradicionais.


Conteúdo relacionado

O Ato RISE do Senador exigiria que desenvolvedores de IA listassem dados de treinamento e métodos de avaliação em troca de ‘porto seguro’ contra processos judiciais.
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne as pessoas que estão construindo uma verdadeira…

O argumento a favor da incorporação de trilhas de auditoria em sistemas de IA antes da escalabilidade
[the_ad id="145565"] Participe do evento que é confiável por líderes empresariais há quase duas décadas. O VB Transform reúne as pessoas que estão construindo estratégias…

6 Novos Recursos de Projetos do ChatGPT que Você Precisa Conhecer
[the_ad id="145565"] Os Projetos do ChatGPT acabaram de receber sua atualização mais significativa desde o lançamento, e as implicações para a produtividade são substanciais. A…