


A divisão de pesquisa da Disney está apresentando um novo método de compressão de imagens, utilizando o modelo de código aberto Stable Diffusion V1.2 para produzir imagens mais realistas em bitrates mais baixos do que métodos concorrentes.

O método de compressão da Disney comparado a abordagens anteriores. Os autores afirmam uma recuperação melhorada de detalhes, enquanto oferecem um modelo que não requer centenas de milhares de dólares em treinamento e que opera mais rapidamente do que o método concorrente mais próximo. Fonte: https://studios.disneyresearch.com/app/uploads/2024/09/Lossy-Image-Compression-with-Foundation-Diffusion-Models-Paper.pdf
A nova abordagem (definida como um ‘codec’ apesar de sua complexidade aumentada em comparação com codecs tradicionais como JPEG e AV1) pode operar sobre qualquer Modelo de Difusão Latente (LDM). Em testes quantitativos, ela supera métodos anteriores em termos de precisão e detalhes, e requer significativamente menos custo de treinamento e computação.
A principal descoberta do novo trabalho é que erro de quantização (um processo central em toda compressão de imagem) é semelhante ao ruído (um processo central em modelos de difusão).
Portanto, uma imagem ‘tradicionalmente’ quantizada pode ser tratada como uma versão ruidosa da imagem original e usada no processo de desruído de um LDM em vez do ruído aleatório, para reconstruir a imagem em um bitrate alvo.

Comparações adicionais do novo método da Disney (destacado em verde), em contraste com abordagens rivais.
Os autores afirmam:
‘[Nós] formulamos a remoção do erro de quantização como uma tarefa de desruído, usando a difusão para recuperar informações perdidas na imagem transmitida de latente. Nossa abordagem nos permite realizar menos de 10% do processo completo de geração de difusão e não requer mudanças arquitetônicas no modelo de difusão, permitindo o uso de modelos fundacionais como um forte prévio sem ajuste adicional da base.
‘Nosso codec proposto supera métodos anteriores em métricas de realismo quantitativo, e verificamos que nossas reconstruções são qualitativamente preferidas pelos usuários finais, mesmo quando outros métodos usam o dobro do bitrate.’
Contudo, assim como outros projetos que buscam explorar as capacidades de compressão de modelos de difusão, a saída pode alucinar detalhes. Em contraste, métodos com perdas como JPEG produzem claramente áreas distorcidas ou excessivamente suavizadas, que podem ser reconhecidas como limitações de compressão pelo observador casual.
Em vez disso, o codec da Disney pode alterar detalhes a partir de um contexto que não estava presente na imagem fonte, devido à natureza grosseira do Variational Autoencoder (VAE) usado em modelos típicos treinados em dados de escala hiperscala.
‘Semelhante a outras abordagens generativas, nosso método pode descartar certos recursos da imagem enquanto sintetiza informações similares no lado do receptor. Em casos específicos, no entanto, isso pode resultar em reconstruções imprecisas, como curvar linhas retas ou distorcer a borda de pequenos objetos.
‘Esses são problemas bem conhecidos do modelo fundacional sobre o qual nos baseamos, que podem ser atribuídos à dimensão de recurso relativamente baixa de seu VAE.’
Embora isso tenha algumas implicações para representações artísticas e a veracidade de fotografias casuais, pode ter um impacto mais crítico em casos onde pequenos detalhes constituem informações essenciais, como evidências para processos judiciais, dados para reconhecimento facial, escaneamentos para Reconhecimento Óptico de Caracteres (OCR), e uma ampla variedade de outros possíveis casos de uso, na eventualidade da popularização de um codec com essa capacidade.
Neste estágio inicial do progresso da compressão de imagem aprimorada por IA, todos esses cenários possíveis estão distantes no futuro. No entanto, o armazenamento de imagens é um desafio global de escala hiperscala, tocando em questões relacionadas ao armazenamento de dados, streaming e consumo de eletricidade, além de outras preocupações. Portanto, a compressão baseada em IA poderia oferecer um compromisso tentador entre precisão e logística. A história mostra que os melhores codecs nem sempre ganham a maior base de usuários, quando questões como licenciamento e captura de mercado por formatos proprietários são fatores na adoção.
A Disney tem experimentado com aprendizado de máquina como método de compressão há bastante tempo. Em 2020, um dos pesquisadores do novo artigo esteve envolvido em um projeto baseado em VAE para compressão de vídeo aprimorada.
O novo artigo da Disney foi atualizado no início de outubro. Hoje, a empresa lançou um vídeo no YouTube que o acompanha. O projeto é intitulado Compressão de Imagem com Perdas com Modelos de Difusão de Fundação, e vem de quatro pesquisadores da ETH Zürich (afiliados aos projetos baseados em IA da Disney) e da Pesquisa Disney. Os pesquisadores também oferecem um artigo suplementar.
Método
O novo método usa um VAE para codificar uma imagem em sua representação latente comprimida. Neste estágio, a imagem de entrada consiste em recursos derivados – representações vetoriais de baixo nível. A incorporação latente é então quantizada de volta em um bitstream e de volta para o espaço de pixels.
Essa imagem quantizada é então usada como um modelo para o ruído que geralmente inicia uma imagem baseada em difusão, com um número variável de etapas de desruído (onde muitas vezes há um compromisso entre aumento de etapas de desruído e maior precisão, versus menor latência e maior eficiência).
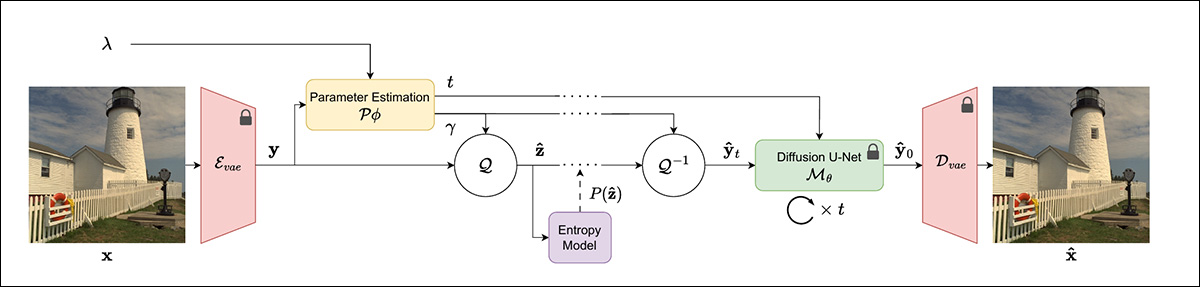
Esquema do novo método de compressão da Disney.
Tanto os parâmetros de quantização quanto o número total de etapas de desruído podem ser controlados sob o novo sistema, através do treinamento de uma rede neural que prevê as variáveis relevantes relacionadas a esses aspectos da codificação. Esse processo é chamado de quantização adaptativa, e o sistema da Disney usa a estrutura Entroformer como modelo de entropia que impulsiona o procedimento.
Os autores afirmam:
‘Intuitivamente, nosso método aprende a descartar informações (através da transformação de quantização) que podem ser sintetizadas durante o processo de difusão. Como os erros introduzidos durante a quantização são semelhantes a adicionar [ruído] e modelos de difusão são funcionalmente modelos de desruído, eles podem ser usados para remover o ruído de quantização introduzido durante a codificação.’
O Stable Diffusion V2.1 é a espinha dorsal de difusão para o sistema, escolhido porque o código inteiro e os pesos base são publicamente disponíveis. No entanto, os autores enfatizam que seu esquema é aplicável a um número maior de modelos.
Pivotal para a economia do processo é a previsão de timestep, que avalia o número ótimo de etapas de desruído – um ato de equilibrar eficiência e desempenho.

Previsões de timestep, com o número ótimo de etapas de desruído indicado com borda vermelha. Por favor, consulte o PDF de origem para resolução precisa.
A quantidade de ruído na incorporação latente deve ser considerada ao fazer uma previsão para o melhor número de etapas de desruído.
Dados e Testes
O modelo foi treinado no conjunto de dados Vimeo-90k. As imagens foram cortadas aleatoriamente para 256x256px para cada época (ou seja, cada ingestão completa do conjunto de dados refinado pela arquitetura de treinamento do modelo).
O modelo foi otimizado para 300.000 etapas a uma taxa de aprendizado de 1e-4. Essa é a mais comum entre projetos de visão computacional, e também o valor mais baixo e mais fino geralmente prático, como um compromisso entre a ampla generalização dos conceitos e traços do conjunto de dados, e uma capacidade de reprodução de detalhes finos.
Os autores comentam sobre algumas das considerações logísticas para um sistema econômico, mas eficaz*:
‘Durante o treinamento, é proibitivamente caro retropropagar o gradiente através de múltiplas execuções do modelo de difusão enquanto ele roda durante o amostragem DDIM. Portanto, realizamos apenas uma iteração de amostragem DDIM e usamos diretamente [isso] como os dados totalmente desruídos.’
Os conjuntos de dados usados para testar o sistema foram Kodak; CLIC2022; e COCO 30k. O conjunto de dados foi pré-processado de acordo com a metodologia delineada na oferta do Google de 2023 Compressão de Imagem Multi-Realismo com um Gerador Condicional.
Métricas utilizadas foram a Razão Pico-Sinal/Ruído (PSNR); Métricas de Similaridade Perceptual Aprendidas (LPIPS); Índice de Similaridade Estrutural Multiescalar (MS-SSIM); e Distância de Fréchet de Inception (FID).
As estruturas rivais anteriores testadas foram divididas entre sistemas mais antigos que usavam Redes Adversariais Generativas (GANs) e ofertas mais recentes baseadas em modelos de difusão. Os sistemas de GAN testados foram Compressão de Imagem Generativa de Alta Fidelidade (HiFiC); e ILLM (que oferece algumas melhorias em relação ao HiFiC).
Os sistemas baseados em difusão foram Compressão de Imagem com Perdas com Modelos de Difusão Condicional (CDC) e Compressão de Imagem de Alta Fidelidade com Modelos Generativos Baseados em Pontos (HFD).
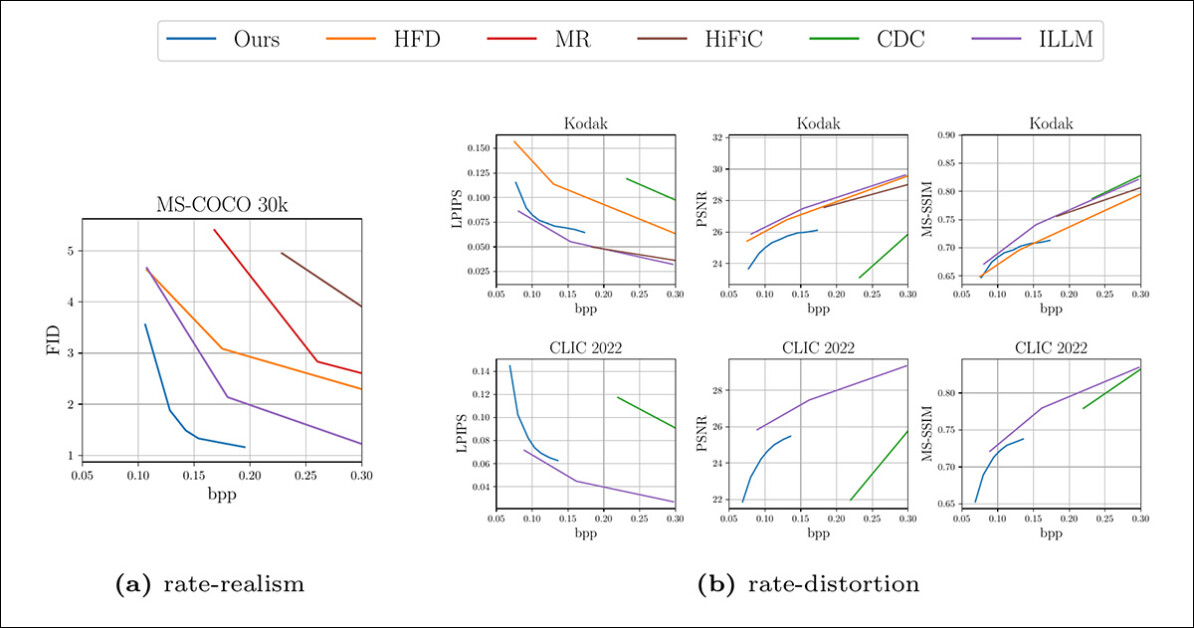
Resultados quantitativos contra estruturas anteriores sobre vários conjuntos de dados.
Para os resultados quantitativos (visualizados acima), os pesquisadores afirmam:
‘Nosso método estabelece um novo estado da arte em realismo de reconstruções de imagens, superando todas as bases nas curvas FID-bitrate. Em algumas métricas de distorção (nomeadamente, LPIPS e MS-SSIM), superamos todos os codecs baseados em difusão enquanto permanecemos competitivos com os codecs generativos de maior desempenho.
‘Como esperado, nosso método e outros métodos generativos sofrem quando medidos em PSNR, pois favorecemos reconstruções perceptualmente agradáveis em vez da replicação exata dos detalhes.’
No estudo com usuários, foi utilizado um método de escolha forçada de duas alternativas (2AFC), em um contexto de torneio onde as imagens preferidas avançariam para rodadas posteriores. O estudo utilizou o sistema de classificação Elo desenvolvido originalmente para torneios de xadrez.
Portanto, os participantes visualizariam e selecionariam o melhor de duas imagens apresentadas de 512x512px entre os vários métodos generativos. Um experimento adicional foi realizado no qual todas as comparações de imagens do mesmo usuário foram avaliadas, através de uma simulação de Monte Carlo ao longo de 10.000 iterações, com a mediana apresentada nos resultados.
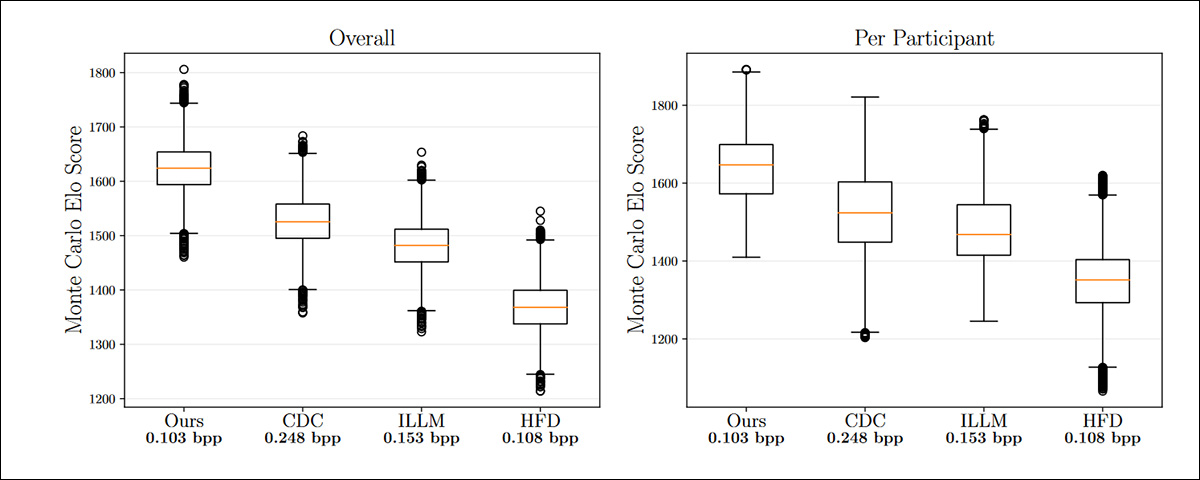
Classificações Elo estimadas para o estudo com usuários, apresentando torneios Elo para cada comparação (esquerda) e também para cada participante, com valores mais altos sendo melhores.
Aqui os autores comentam:
‘Como pode ser visto nas pontuações Elo, nosso método supera significativamente todos os outros, mesmo em comparação com CDC, que usa em média o dobro dos bits do nosso método. Isso permanece verdadeiro independentemente da estratégia de torneio Elo utilizada.’
No artigo original, bem como no PDF suplementar, os autores fornecem mais comparações visuais, uma das quais é mostrada anteriormente neste artigo. No entanto, devido à granularidade da diferença entre as amostras, remetemos o leitor ao PDF de origem, para que esses resultados possam ser julgados de forma justa.
O artigo conclui observando que seu método proposto opera duas vezes mais rápido que o rival CDC (3,49 contra 6,87 segundos, respectivamente). Também observa que o ILLM pode processar uma imagem em 0,27 segundos, mas que esse sistema requer um treinamento exigente.
Conclusão
Os pesquisadores da ETH/Disney estão claros, na conclusão do artigo, sobre o potencial de seu sistema de gerar detalhes falsos. No entanto, nenhuma das amostras oferecidas no material se concentra nesse problema.
Para ser justo, esse problema não é limitado à nova abordagem da Disney, mas é um efeito colateral inevitável do uso de modelos de difusão – uma arquitetura inventiva e interpretativa – para comprimir imagens.
Curiosamente, apenas cinco dias atrás, dois outros pesquisadores da ETH Zürich produziram um artigo intitulado Alucinações Condicionais para Compressão de Imagem, que examina a possibilidade de um ‘nível ótimo de alucinação’ em sistemas de compressão baseados em IA.
Os autores lá fazem um caso para a desejabilidade de alucinações onde o domínio é genérico (e, por assim dizer, ‘inofensivo’) o suficiente:
‘Para conteúdos semelhantes a texturas, como grama, sardas e paredes de pedra, gerar pixels que correspondam realisticamente a uma determinada textura é mais importante do que reconstruir valores de pixel precisos; gerar qualquer amostra da distribuição de uma textura geralmente é suficiente.’
Assim, este segundo artigo faz um caso para que a compressão seja otimamente ‘criativa’ e representativa, em vez de recriar o mais precisamente possível os traços e detalhes essenciais da imagem original não comprimida.
Fica a dúvida sobre o que a comunidade fotográfica e criativa pensaria sobre essa redefinição bastante radical de ‘compressão’.
*Minha conversão das citações inline dos autores em hyperlinks.
Publicado pela primeira vez na quarta-feira, 30 de outubro de 2024



Conteúdo relacionado

Anthropic enviou um aviso de remoção a um desenvolvedor que tentava reverter o código de sua ferramenta.
[the_ad id="145565"] Na disputa entre duas ferramentas de código "agente" — Claude Code da Anthropic e Codex CLI da OpenAI — a última parece estar promovendo mais boa vontade…

O novo CEO da Intel sinaliza esforços de simplificação, mas não revela números exatos de demissões.
[the_ad id="145565"] Lip-Bu Tan, o novo CEO da Intel, enviou uma mensagem direta aos funcionários, afirmando que a empresa precisa se reorganizar para ser mais eficiente. Ele…

Um pesquisador da OpenAI que trabalhou no GPT-4.5 teve seu green card negado.
[the_ad id="145565"] Kai Chen, um pesquisador de IA canadense que trabalha na OpenAI e mora nos EUA há 12 anos, teve seu pedido de green card negado, de acordo com Noam Brown,…