


Participe das nossas newsletters diárias e semanais para atualizações e conteúdos exclusivos sobre as últimas novidades em cobertura de IA. Saiba Mais
O modelo o1 da OpenAI demonstrou que o escalonamento em tempo de inferência — usar mais computação durante a inferência — pode aumentar significativamente as habilidades de raciocínio de um modelo de linguagem. O LLaVA-o1, um novo modelo desenvolvido por pesquisadores de várias universidades na China, traz esse paradigma para modelos de linguagem de visão de código aberto (VLMs).
Modelos de VLMs de código aberto geralmente utilizam uma abordagem de previsão direta, gerando respostas sem raciocinar sobre o prompt e os passos necessários para resolver o problema. Sem um processo de raciocínio estruturado, eles são menos eficazes em tarefas que requerem raciocínio lógico. Tecnologias avançadas de prompting, como o prompting de cadeia de pensamento (CoT), onde o modelo é incentivado a gerar passos intermediários de raciocínio, trazem algumas melhorias marginais. Contudo, os VLMs frequentemente cometem erros ou alucinam.
Os pesquisadores observaram que um problema chave é que o processo de raciocínio nos VLMs existentes não é suficientemente sistemático e estruturado. Os modelos não geram cadeias de raciocínio e frequentemente ficam presos em processos de raciocínio nos quais não sabem em que estágio estão e qual problema específico precisam resolver.
“Observamos que os VLMs frequentemente iniciam respostas sem organizar adequadamente o problema e as informações disponíveis”, escrevem os pesquisadores. “Além disso, eles frequentemente se desviam de um raciocínio lógico em direção a conclusões, em vez de apresentar uma conclusão prematuramente e, em seguida, tentar justificá-la. Dado que os modelos de linguagem geram respostas token por token, uma vez que uma conclusão errônea é introduzida, o modelo normalmente continua ao longo de um caminho de raciocínio falho.”
Raciocínio em várias etapas
O modelo o1 da OpenAI utiliza o escalonamento em tempo de inferência para resolver o problema de raciocínio sistemático e estruturado, permitindo que o modelo pause e revise seus resultados enquanto resolve gradualmente o problema. Embora a OpenAI não tenha divulgado muitos detalhes sobre o mecanismo subjacente do o1, seus resultados mostram direções promissoras para melhorar as habilidades de raciocínio de modelos fundamentais.
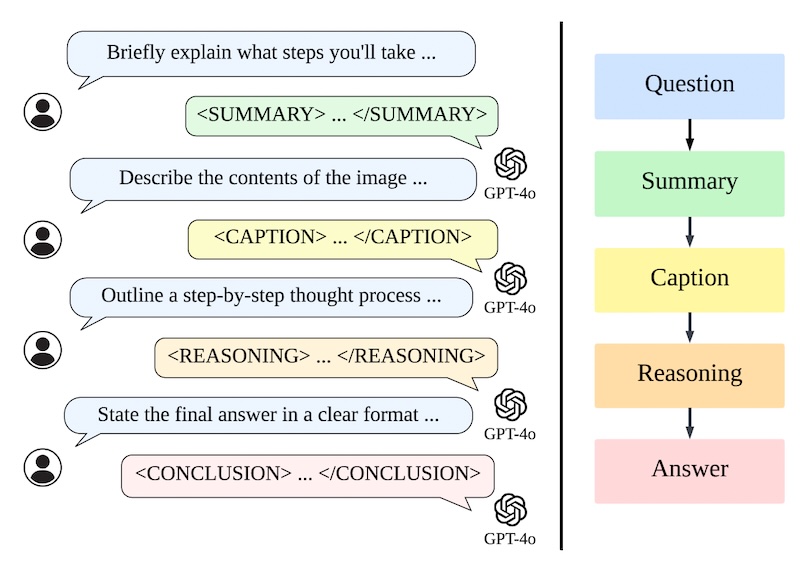
Inspirados pelo o1, os pesquisadores projetaram o LLaVA-o1 para executar um raciocínio em etapas. Em vez de gerar uma cadeia de raciocínio direta, o LLaVA-o1 divide o processo de raciocínio em quatro etapas distintas:
Resumo: O modelo primeiro fornece um resumo de alto nível da questão, delineando o problema central que precisa ser abordado.
Legenda: Se uma imagem estiver presente, o modelo descreve as partes relevantes, focando em elementos relacionados à questão.
Raciocínio: Com base no resumo, o modelo executa um raciocínio lógico estruturado para derivar uma resposta preliminar.
Conclusão: Finalmente, o modelo apresenta um resumo conciso da resposta com base no raciocínio anterior.
Apenas a etapa de conclusão é visível para o usuário; as outras três etapas representam o processo de raciocínio interno do modelo, semelhante ao rastreamento de raciocínio oculto do o1. Essa abordagem estruturada permite que o LLaVA-o1 gerencie seu processo de raciocínio de forma independente, levando a um desempenho aprimorado em tarefas complexas.
“Essa abordagem estruturada permite que o modelo gerencie de forma independente seu processo de raciocínio, melhorando sua adaptabilidade e desempenho em tarefas de raciocínio complexo”, escrevem os pesquisadores.
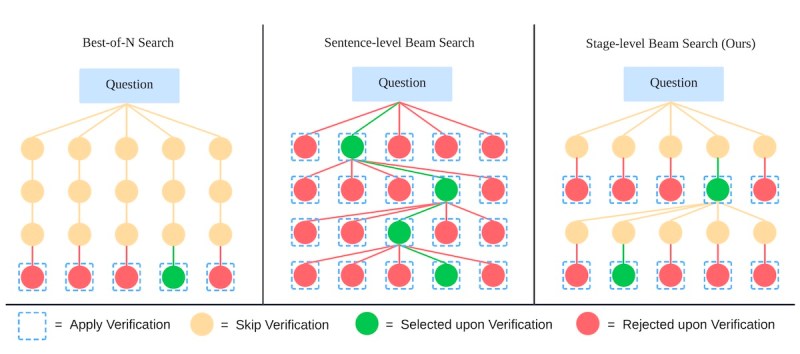
O LLaVA-o1 também introduz uma nova técnica de escalonamento em tempo de inferência chamada “busca de feixes em nível de estágio.” A busca de feixes em nível de estágio gera várias saídas candidatas em cada etapa de raciocínio. Em seguida, ele seleciona a melhor candidata em cada fase para continuar o processo de geração. Isso é contrastante com a abordagem clássica de melhor entre N, na qual o modelo é solicitado a gerar várias respostas completas antes de selecionar uma.
“Notavelmente, é o design de saída estruturado do LLaVA-o1 que torna essa abordagem viável, permitindo a verificação eficiente e precisa em cada etapa,” escrevem os pesquisadores. “Isso valida a eficácia da saída estruturada em melhorar o escalonamento em tempo de inferência.”
Treinamento do LLaVA-o1
Para treinar o LLaVA-o1, os pesquisadores compilaram um novo conjunto de dados de cerca de 100.000 pares de imagem-pergunta-resposta obtidos de vários conjuntos de dados de VQA amplamente utilizados. O conjunto de dados cobre uma variedade de tarefas, desde perguntas e respostas de múltiplas rodadas até interpretação de gráficos e raciocínio geométrico.
Os pesquisadores usaram o GPT-4o para gerar os detalhados processos de raciocínio em quatro etapas para cada exemplo, incluindo as etapas de resumo, legenda, raciocínio e conclusão.
Os pesquisadores então ajustaram finamente o modelo Llama-3.2-11B-Vision-Instruct com esse conjunto de dados para obter o modelo final LLaVA-o1. Os pesquisadores ainda não liberaram o modelo, mas planejam liberar o conjunto de dados, chamado de LLaVA-o1-100k.
LLaVA-o1 em ação
Os pesquisadores avaliaram o LLaVA-o1 em vários benchmarks de raciocínio multimodal. Apesar de ter sido treinado apenas com 100.000 exemplos, o LLaVA-o1 apresentou melhorias significativas de desempenho em relação ao modelo base Llama, com um aumento médio de 6,9% na pontuação de benchmark.
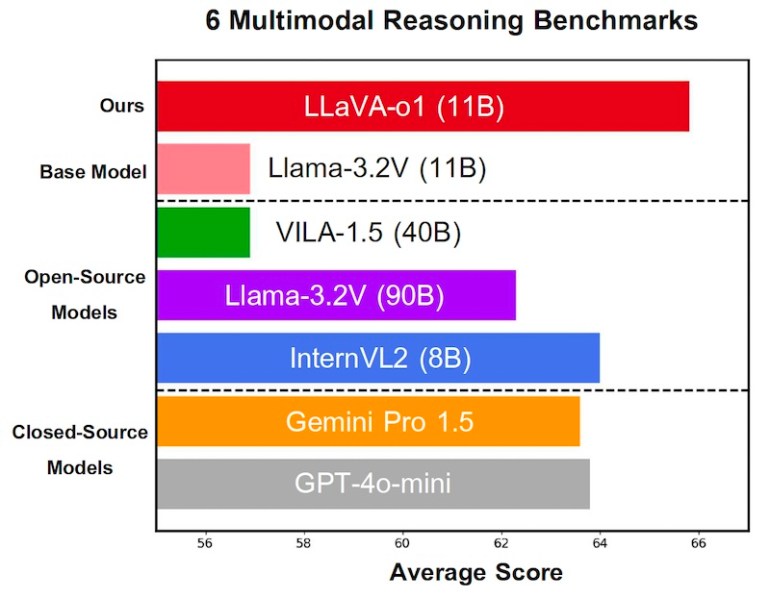
Além disso, a busca de feixes em nível de estágio levou a ganhos adicionais de desempenho, demonstrando a eficácia do escalonamento em tempo de inferência. Devido a limitações nos recursos computacionais, os pesquisadores conseguiram testar a técnica apenas com um tamanho de feixe de 2. Eles esperam melhorias ainda maiores com tamanhos de feixe maiores.
Impressionantemente, o LLaVA-o1 superou não apenas outros modelos de código aberto do mesmo tamanho ou maiores, mas também alguns modelos de código fechado, como o GPT-4-o-mini e o Gemini 1.5 Pro.
“O LLaVA-o1 estabelece um novo padrão para raciocínio multimodal em VLMs, oferecendo um desempenho robusto e escalabilidade, especialmente em tempo de inferência”, escrevem os pesquisadores. “Nosso trabalho abre caminho para futuras pesquisas sobre raciocínio estruturado em VLMs, incluindo expansões potenciais com verificadores externos e o uso de aprendizado por reforço para aprimorar ainda mais as capacidades de raciocínio multimodal complexo.”

Conteúdo relacionado

Anthropic enviou um aviso de remoção a um desenvolvedor que tentava reverter o código de sua ferramenta.
[the_ad id="145565"] Na disputa entre duas ferramentas de código "agente" — Claude Code da Anthropic e Codex CLI da OpenAI — a última parece estar promovendo mais boa vontade…

O novo CEO da Intel sinaliza esforços de simplificação, mas não revela números exatos de demissões.
[the_ad id="145565"] Lip-Bu Tan, o novo CEO da Intel, enviou uma mensagem direta aos funcionários, afirmando que a empresa precisa se reorganizar para ser mais eficiente. Ele…

Um pesquisador da OpenAI que trabalhou no GPT-4.5 teve seu green card negado.
[the_ad id="145565"] Kai Chen, um pesquisador de IA canadense que trabalha na OpenAI e mora nos EUA há 12 anos, teve seu pedido de green card negado, de acordo com Noam Brown,…