


Participe de nossos boletins diários e semanais para receber as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder da indústria. Saiba mais
À medida que os grandes modelos de linguagem (LLMs) continuam a melhorar na codificação, os benchmarks usados para avaliar seu desempenho tornam-se cada vez menos úteis.
Isso acontece porque, embora muitos LLMs tenham pontuações altas semelhantes nesses benchmarks, entender quais usar em projetos específicos de desenvolvimento de software e empresas pode ser difícil.
Um novo artigo da Universidade de Yale e da Universidade Tsinghua apresenta um método inovador para testar a capacidade dos modelos de enfrentar problemas de “geração de código auto-invocável” que exigem raciocínio, geração de código e reutilização de código existente na resolução de problemas.
A geração de código auto-invocável é muito mais semelhante a cenários de programação realistas e fornece uma melhor compreensão da capacidade atual dos LLMs para resolver problemas de codificação do mundo real.
Geração de código auto-invocável
Dois benchmarks populares usados para avaliar as habilidades de codificação dos LLMs são HumanEval e MBPP (Principalmente Problemas Básicos em Python). Esses são conjuntos de dados de problemas elaborados que exigem que o modelo escreva código para tarefas simples.
No entanto, esses benchmarks cobrem apenas um subconjunto dos desafios que os desenvolvedores de software enfrentam na vida real. Em cenários práticos, os desenvolvedores de software não apenas escrevem novo código—eles também precisam entender e reutilizar o código existente e criar componentes reutilizáveis para resolver problemas complexos.
“A capacidade de entender e aproveitar o próprio código gerado, ou seja, a geração de código auto-invocável, desempenha um papel importante para os LLMs utilizarem suas capacidades de raciocínio na geração de código que os benchmarks atuais não conseguem capturar,” escrevem os pesquisadores.
Para testar a capacidade dos LLMs na geração de código auto-invocável, os pesquisadores criaram dois novos benchmarks, HumanEval Pro e MBPP Pro, que expandem os conjuntos de dados existentes. Cada problema em HumanEval Pro e MBPP Pro se baseia em um exemplo existente no conjunto de dados original e introduz elementos adicionais que exigem que o modelo resolva o problema base e invoque a solução para resolver um problema mais complexo.

Por exemplo, o problema original pode ser algo simples, como escrever uma função que substitui todas as ocorrências de um determinado caractere em uma string por um novo caractere.
O problema ampliado seria escrever uma função que altera as ocorrências de vários caracteres em uma string com suas substituições dadas. Isso exigiria que o modelo escrevesse uma nova função que invocasse a função anterior que foi gerada no problema simples.
“Essa avaliação da geração de código auto-invocável oferece insights mais profundos sobre as capacidades de programação dos LLMs, estendendo-se além do escopo da geração de código de problema único,” escrevem os pesquisadores.
LLMs têm desempenho ruim na geração de código auto-invocável
Os pesquisadores testaram HumanEval Pro e MBPP Pro em mais de 20 modelos abertos e privados, incluindo GPT-4o, OpenAI o1-mini, Claude 3.5 Sonnet, além das séries Qwen, DeepSeek e Codestral.
Seus achados mostram uma disparidade significativa entre os benchmarks de codificação tradicionais e as tarefas de geração de código auto-invocável. “Enquanto os LLMs de ponta se destacam na geração de fragmentos de código individuais, eles frequentemente lutam para utilizar efetivamente seu próprio código gerado para resolver problemas mais complexos,” escrevem os pesquisadores.
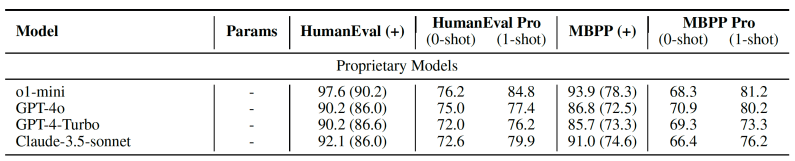
Por exemplo, com uma única geração (pass@1), o o1-mini alcança 96,2% no HumanEval, mas apenas 76,2% no HumanEval Pro.
Outro achado interessante é que, enquanto o ajuste fino por instrução proporciona melhorias significativas em tarefas de codificação simples, ele mostra retornos decrescentes na geração de código auto-invocável. Os pesquisadores observam que “as abordagens atuais de ajuste fino baseadas em instruções são insuficientemente eficazes para tarefas mais complexas de geração de código auto-invocável,” sugerindo que é necessário repensar como treinamos modelos base para tarefas de codificação e raciocínio.
Para avançar a pesquisa em geração de código auto-invocável, os pesquisadores propõem uma técnica para reutilizar automaticamente benchmarks de codificação existentes para a geração de código auto-invocável. A abordagem utiliza LLMs de ponta para gerar problemas auto-invocáveis com base nos problemas originais. Em seguida, eles geram soluções candidatas e verificam sua correção executando o código e rodando casos de teste. O pipeline minimiza a necessidade de revisão manual de código para ajudar a gerar mais exemplos com menos esforço.
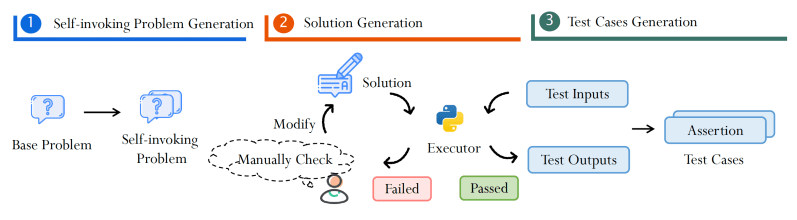
Um cenário complexo
Essa nova família de benchmarks surge em um momento em que os antigos benchmarks de codificação estão rapidamente sendo conquistados por modelos de ponta. Modelos de ponta atuais, como GPT-4o, o1 e Claude 3.5 Sonnet, já têm pontuações muito altas no HumanEval e MBPP, bem como em suas versões mais avançadas, HumanEval+ e MBPP+.
Ao mesmo tempo, existem benchmarks mais complexos, como SWE-Bench, que avaliam as capacidades dos modelos em tarefas de engenharia de software de ponta a ponta que exigem uma ampla gama de habilidades, como o uso de bibliotecas externas e arquivos, e a gestão de ferramentas DevOps. O SWE-Bench é um benchmark muito difícil e mesmo os modelos mais avançados estão apresentando desempenho modesto. Por exemplo, o OpenAI o1 mostra inconsistência no SWE-Bench Verified.
https://twitter.com/alex_cuadron/status/1876017241042587964?s=46
A geração de código auto-invocável está situada em algum lugar entre os benchmarks simples e o SWE-Bench. Ela ajuda a avaliar um tipo muito específico de capacidade de raciocínio: usar código existente dentro de um módulo para enfrentar problemas complexos. Os benchmarks de código auto-invocável podem se provar um proxy muito prático para a utilidade dos LLMs em configurações do mundo real, onde programadores humanos estão no controle e os IA copilotos ajudam a realizar tarefas específicas de codificação no processo de desenvolvimento de software.
“HumanEval Pro e MBPP Pro estão posicionados para servir como benchmarks valiosos para avaliações relacionadas a código e para inspirar o desenvolvimento futuro de LLM, iluminando as atuais deficiências do modelo e incentivando inovações nas metodologias de treinamento,” escrevem os pesquisadores.


Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…