


No sábado, o CEO da Triplegangers, Oleksandr Tomchuk, foi alertado que o site de e-commerce de sua empresa estava fora do ar. Parecia ser algum tipo de ataque de negação de serviço distribuído.
Ele logo descobriu que o responsável era um bot da OpenAI que estava tentando incessantemente raspar todo o seu enorme site.
“Temos mais de 65.000 produtos, cada produto tem uma página,” disse Tomchuk ao TechCrunch. “Cada página possui pelo menos três fotos.”
A OpenAI estava enviando “dezena de milhares” de requisições ao servidor tentando baixar tudo, incluindo centenas de milhares de fotos e suas descrições detalhadas.
“A OpenAI usou 600 IPs para raspar dados, e ainda estamos analisando os logs da semana passada; pode ser muito mais,” disse ele sobre os endereços IP que o bot usou para tentar consumir seu site.
“Seus crawlers estavam destruindo nosso site,” afirmou ele. “Foi basicamente um ataque DDoS.”
O site da Triplegangers é seu negócio. A empresa, que conta com sete funcionários, passou mais de uma década montando o que chama de maior banco de dados de “doubles digitais humanos” da web, ou seja, arquivos de imagem 3D escaneados de modelos humanos reais.
Ela vende os arquivos de objetos 3D, bem como fotos — tudo, desde mãos a cabelo, pele e corpos inteiros — para artistas 3D, desenvolvedores de jogos, e qualquer um que precise recriar digitalmente características humanas autênticas.
A equipe de Tomchuk, baseada na Ucrânia, mas também licenciada nos EUA, em Tampa, Florida, tem uma página de termos de serviço em seu site que proíbe bots de usar suas imagens sem permissão. Mas isso por si só não foi suficiente. Os sites precisam usar um arquivo robot.txt corretamente configurado, com tags especificamente informando ao bot da OpenAI, GPTBot, para deixar o site em paz. (A OpenAI também possui outros bots, ChatGPT-User e OAI-SearchBot, que têm suas próprias tags, de acordo com sua página de informações sobre crawlers.)
O robot.txt, também conhecido como Protocolo de Exclusão de Robôs, foi criado para informar aos sites de motores de busca o que não devem rastrear enquanto indexam a web. A OpenAI afirma em sua página informativa que respeita tais arquivos quando configurados com seu próprio conjunto de tags de não rastrear, embora também avise que pode levar até 24 horas para que seus bots reconheçam um arquivo robot.txt atualizado.
Como Tomchuk vivenciou, se um site não usa corretamente o robot.txt, a OpenAI e outros interpretam isso como se pudessem raspar à vontade. Não é um sistema de opt-in.
Para agravar a situação, não só a Triplegangers ficou offline por causa do bot da OpenAI durante o horário comercial nos EUA, mas Tomchuk espera uma conta de AWS inflacionada devido a toda a atividade de CPU e download do bot.
O robot.txt também não é uma solução infalível. As empresas de IA respeitam voluntariamente. Outra startup de IA, Perplexity, foi chamada atenção um verão atrás por uma investigação da Wired quando algumas evidências implicaram que a Perplexity não estava respeitando isso.
Não se pode saber ao certo o que foi retirado
Na quarta-feira, após dias com o bot da OpenAI retornando, a Triplegangers teve um arquivo robot.txt corretamente configurado em vigor, e também uma conta no Cloudflare configurada para bloquear seu GPTBot e vários outros bots que ele descobriu, como Barkrowler (um crawler de SEO) e Bytespider (o crawler do TokTok). Tomchuk também espera ter bloqueado crawlers de outras empresas de modelos de IA. Na manhã de quinta-feira, o site não travou, disse ele.
Mas Tomchuk ainda não tem um meio razoável para descobrir exatamente o que a OpenAI conseguiu pegar ou para conseguir remover esse material. Ele não encontrou nenhuma maneira de contatar a OpenAI para perguntar. A OpenAI não respondeu ao pedido de comentário do TechCrunch. E a OpenAI até agora falhou em entregar sua tão prometida ferramenta de opt-out, como o TechCrunch relatou recentemente.
Este é um problema especialmente complicado para a Triplegangers. “Estamos em um negócio onde os direitos são uma questão séria, porque escaneamos pessoas reais,” disse ele. Com leis como o GDPR da Europa, “eles não podem simplesmente pegar uma foto de qualquer pessoa na web e usá-la.”
O site da Triplegangers também era uma descoberta especialmente valiosa para crawlers de IA. Startups avaliadas em bilhões de dólares, como a Scale AI, foram criadas onde humanos meticulosamente marcam imagens para treinar IA. O site da Triplegangers contém fotos marcadas em detalhes: etnia, idade, tatuagens versus cicatrizes, todos os tipos de corpos, e assim por diante.
A ironia é que a ganância do bot da OpenAI foi o que alertou a Triplegangers sobre quão exposto estava. Se ele tivesse raspado de forma mais gentil, Tomchuk nunca teria sabido, disse ele.
“É assustador porque parece haver uma brecha que essas empresas estão usando para raspar dados ao dizer ‘você pode optar por não participar se atualizar seu robot.txt com nossas tags,’” diz Tomchuk, “mas isso coloca a responsabilidade no proprietário do negócio para entender como bloqueá-los.
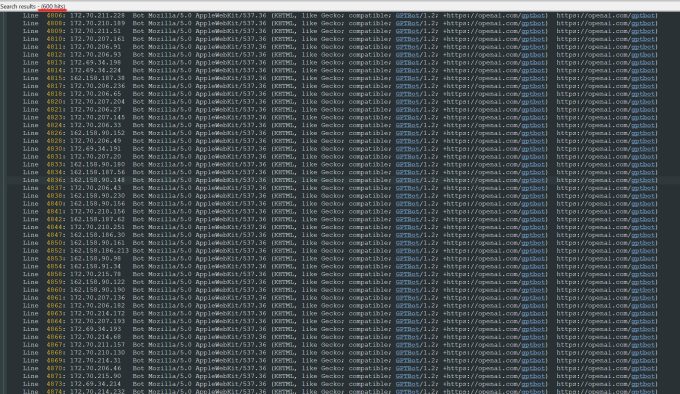
Ele quer que outros pequenos negócios online saibam que a única maneira de descobrir se um bot de IA está levando os pertences protegidos por direitos autorais de um site é monitorar ativamente. Ele certamente não está sozinho em ser atormentado por eles. Proprietários de outros sites recentemente contaram ao Business Insider como bots da OpenAI derrubaram seus sites e elevaram suas contas da AWS.
O problema cresceu em magnitude em 2024. Uma nova pesquisa da empresa de publicidade digital DoubleVerify encontrou que crawlers e scrapers de IA causaram um aumento de 86% no “tráfego inválido geral” em 2024 — ou seja, tráfego que não vem de um usuário real.
Ainda assim, “a maioria dos sites permanece sem noção de que foram raspados por esses bots,” alerta Tomchuk. “Agora temos que monitorar diariamente a atividade dos logs para detectar esses bots.”
Quando se pensa bem, todo o modelo opera um pouco como um esquema de máfia: Os bots de IA pegarão o que quiserem, a menos que você tenha proteção.
“Eles deveriam pedir permissão, e não apenas raspar dados,” diz Tomchuk.
O TechCrunch tem um boletim informativo focado em IA! Inscreva-se aqui para recebê-lo na sua caixa de entrada todas as quartas-feiras.

Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…