


Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta na indústria. Saiba mais
Uma nova arquitetura de rede neural desenvolvida por pesquisadores do Google pode resolver um dos grandes desafios para modelos de linguagem de grande porte (LLMs): expandir sua memória durante o tempo de inferência sem aumentar exponencialmente os custos de memória e computação. Chamado de Titans, a arquitetura permite que os modelos encontrem e armazenem durante a inferência pequenos pedaços de informação que são importantes em longas sequências.
Os Titans combinam blocos de atenção tradicionais de LLM com camadas de “memória neural” que permitem que os modelos lidem com tarefas de memória de curto e longo prazo de maneira eficiente. De acordo com os pesquisadores, LLMs que utilizam memória neural de longo prazo podem escalar até milhões de tokens e superar tanto LLMs clássicos quanto alternativas como o Mamba, enquanto possuem muitos menos parâmetros.
Camadas de atenção e modelos lineares
A arquitetura clássica do transformer usada em LLMs emprega o mecanismo de autoatenção para calcular as relações entre tokens. Esta é uma técnica eficaz que pode aprender padrões complexos e detalhados em sequências de tokens. No entanto, à medida que o comprimento da sequência aumenta, os custos de computação e memória do cálculo e armazenamento de atenção crescem quadraticamente.
Propostas mais recentes envolvem arquiteturas alternativas que têm complexidade linear e podem escalar sem explodir os custos de memória e computação. No entanto, os pesquisadores do Google argumentam que modelos lineares não apresentam desempenho competitivo em comparação com transformers clássicos, pois comprimem seus dados contextuais e tendem a perder detalhes importantes.
A arquitetura ideal, eles sugerem, deve ter diferentes componentes de memória que podem ser coordenados para usar o conhecimento existente, memorizar novos fatos e aprender abstrações a partir de seu contexto.
“Argumentamos que em um paradigma de aprendizado eficaz, semelhante ao [do] cérebro humano, existem módulos distintos, mas interconectados, cada um dos quais é responsável por um componente crucial do processo de aprendizado,” escrevem os pesquisadores.
Memória neural de longo prazo
“A memória é uma confederação de sistemas — ou seja, memória de curto prazo, de trabalho e de longo prazo — cada uma servindo a uma função diferente com diferentes estruturas neurais, e cada uma capaz de operar de forma independente,” tparam as ordens dos pesquisadores.
Para preencher a lacuna nos modelos de linguagem atuais, os pesquisadores propõem um módulo de “memória neural de longo prazo” que pode aprender novas informações em tempo de inferência sem as ineficiências do mecanismo de atenção completo. Em vez de armazenar informações durante o treinamento, o módulo de memória neural aprende uma função que pode memorizar novos fatos durante a inferência e adaptar dinamicamente o processo de memorização com base nos dados que encontra. Isso resolve o problema de generalização que outras arquiteturas de redes neurais enfrentam.
Para decidir quais pedaços de informação valem a pena armazenar, o módulo de memória neural utiliza o conceito de “surpresa”. Quanto mais uma sequência de tokens difere do tipo de informação armazenada nos pesos do modelo e na memória existente, mais surpreendente ela é e, portanto, mais vale a pena memorizá-la. Isso permite que o módulo utilize eficientemente sua memória limitada e armazene apenas pedaços de dados que adicionem informações úteis ao que o modelo já sabe.
Para lidar com sequências de dados muito longas, o módulo de memória neural possui um mecanismo de esquecimento adaptativo que lhe permite remover informações que não são mais necessárias, ajudando a gerenciar a capacidade limitada da memória.
O módulo de memória pode ser complementar ao mecanismo de atenção dos modelos transformer atuais, que os pesquisadores descrevem como “módulos de memória de curto prazo, atendendo ao tamanho da janela de contexto atual. Por outro lado, nossa memória neural com a capacidade de aprender continuamente a partir dos dados e armazená-los em seus pesos pode desempenhar o papel de uma memória de longo prazo.”
Arquitetura Titan
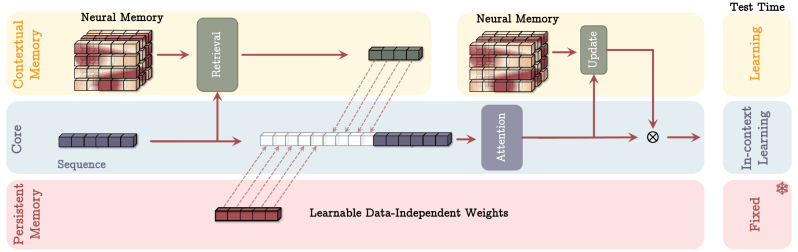
Os pesquisadores descrevem os Titans como uma família de modelos que incorporam blocos de transformer existentes com módulos de memória neural. O modelo possui três componentes principais: o módulo “core”, que atua como a memória de curto prazo e utiliza o mecanismo de atenção clássico para focar no segmento atual dos tokens de entrada que o modelo está processando; um módulo de “memória de longo prazo”, que utiliza a arquitetura de memória neural para armazenar informações além do contexto atual; e um módulo de “memória persistente”, os parâmetros aprendíveis que permanecem fixos após o treinamento e armazenam conhecimento independente do tempo.
Os pesquisadores propõem diferentes maneiras de conectar os três componentes. Mas, em geral, a principal vantagem dessa arquitetura é permitir que os módulos de atenção e memória se complementem. Por exemplo, as camadas de atenção podem usar o contexto histórico e atual para determinar quais partes da janela de contexto atual devem ser armazenadas na memória de longo prazo. Enquanto isso, a memória de longo prazo fornece conhecimento histórico que não está presente no contexto atual de atenção.
Os pesquisadores realizaram testes em pequena escala em modelos Titan, variando de 170 milhões a 760 milhões de parâmetros, em uma ampla variedade de tarefas, incluindo modelagem de linguagem e tarefas de linguagem de longa sequência. Eles compararam o desempenho dos Titans com vários modelos baseados em transformers, modelos lineares como Mamba e modelos híbridos como Samba.
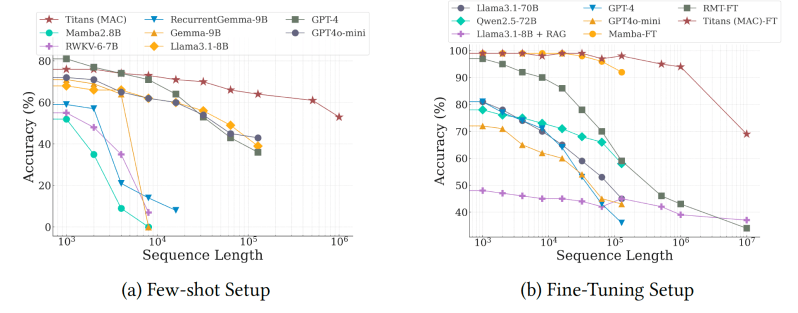
Os Titans demonstraram um desempenho sólido na modelagem de linguagem em comparação com outros modelos e superaram tanto transformers quanto modelos lineares de tamanhos semelhantes.
A diferença no desempenho é especialmente pronunciada em tarefas com sequências longas, como o “a Agulha em um Palheiro”, onde o modelo deve recuperar bits de informação de uma sequência muito longa, e o BABILong, onde o modelo deve raciocinar sobre fatos distribuídos em documentos muito longos. De fato, nessas tarefas, o Titan superou modelos com ordens de magnitude a mais de parâmetros, incluindo GPT-4 e GPT-4o-mini, além de um modelo Llama-3 aprimorado com geração aumentada por recuperação (RAG).
Além disso, os pesquisadores conseguiram estender a janela de contexto dos Titans para até 2 milhões de tokens, mantendo os custos de memória em um nível modesto.
Os modelos ainda precisam ser testados em tamanhos maiores, mas os resultados do artigo mostram que os pesquisadores ainda não atingiram o teto do potencial dos Titans.
O que isso significa para aplicações empresariais?
Com o Google na vanguarda dos modelos de longo contexto, podemos esperar que essa técnica encontre seu caminho em modelos privados e abertos, como Gemini e Gemma.
Com os LLMs suportando janelas de contexto mais longas, há um potencial crescente para criar aplicações onde você pode comprimir novos conhecimentos em seu prompt em vez de usar técnicas como RAG. O ciclo de desenvolvimento para criar e iterar sobre aplicações baseadas em prompt é muito mais rápido do que pipelines RAG complexos. Enquanto isso, arquiteturas como os Titans podem ajudar a reduzir os custos de inferência para sequências muito longas, tornando possível que empresas implantem aplicações de LLM para mais casos de uso.
O Google planeja liberar o código em PyTorch e JAX para treinar e avaliar os modelos Titans.


Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…