


Este artigo faz parte da edição especial da VentureBeat, “IA em Escala: Da Visão à Viabilidade.” Leia mais dessa edição especial aqui.
À medida que encerramos 2024, podemos refletir e reconhecer que a inteligência artificial fez avanços impressionantes e inovadores. Com o ritmo atual, prever quais surpresas 2025 tem reservado para a IA é praticamente impossível. No entanto, várias tendências pintam um quadro convincente do que as empresas podem esperar no próximo ano e como podem se preparar para tirar pleno proveito disso.
A queda drástica nos custos de inferência
No último ano, os custos dos modelos de fronteira diminuíram de forma constante. O preço por milhão de tokens do modelo de linguagem de grande escala (LLM) de alto desempenho da OpenAI caiu mais de 200 vezes nos últimos dois anos.
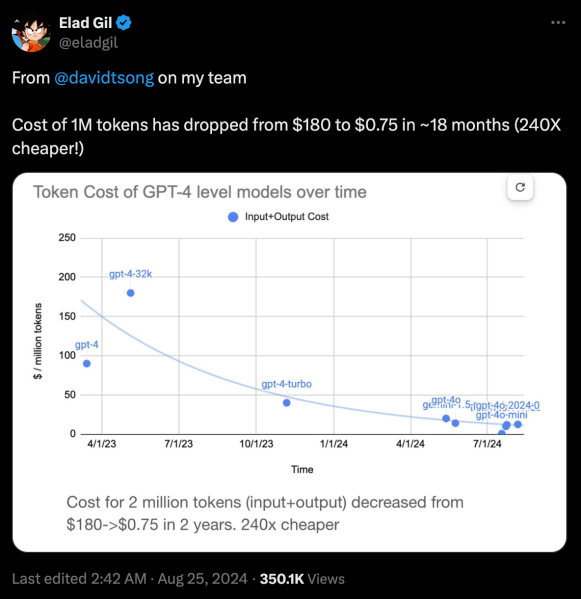
Um fator chave que está reduzindo o preço da inferência é a crescente concorrência. Para muitas aplicações empresariais, a maioria dos modelos de fronteira será apropriada, o que facilita a troca de um para outro, deslocando a competição para o preço. Melhorias em chips de aceleração e hardware de inferência especializado também estão permitindo que laboratórios de IA ofereçam seus modelos a custos mais baixos.
Para aproveitar essa tendência, as empresas devem começar a experimentar com os LLMs mais avançados e construir protótipos de aplicações em torno deles, mesmo que os custos possam ser altos no momento. A redução contínua nos preços dos modelos significa que muitas dessas aplicações logo serão escaláveis. Ao mesmo tempo, as capacidades dos modelos continuam a melhorar, o que significa que você pode fazer muito mais com o mesmo orçamento do que poderia no ano passado.
A ascensão dos grandes modelos de raciocínio
A liberação do OpenAI o1 desencadeou uma nova onda de inovação no espaço dos LLMs. A tendência de permitir que modelos “pensem” por períodos mais longos e revisem suas respostas torna possível resolver problemas de raciocínio que eram impossíveis com chamadas de inferência únicas. Embora a OpenAI não tenha divulgado os detalhes do o1, suas capacidades impressionantes provocaram uma nova corrida no espaço da IA. Atualmente, existem muitos modelos de código aberto que replicam as habilidades de raciocínio do o1 e estão estendendo o paradigma para novos campos, como responder a perguntas abertas.
Avanços em modelos semelhantes ao o1, que às vezes são chamados de grandes modelos de raciocínio (LRMs), podem ter duas implicações importantes para o futuro. Primeiro, dada a imensa quantidade de tokens que os LRMs devem gerar para suas respostas, podemos esperar que empresas de hardware sejam mais incentivadas a criar aceleradores de IA especializados com maior capacidade de token.
Em segundo lugar, os LRMs podem ajudar a solucionar um dos gargalos importantes da próxima geração de modelos de linguagem: dados de treinamento de alta qualidade. Já existem relatos de que a OpenAI está usando o o1 para gerar exemplos de treinamento para sua próxima geração de modelos. Também podemos esperar que os LRMs ajudem a originar uma nova geração de pequenos modelos especializados que tenham sido treinados em dados sintéticos para tarefas muito específicas.
Para tirar proveito desses desenvolvimentos, as empresas devem alocar tempo e orçamento para experimentar as possíveis aplicações dos LRMs de fronteira. Elas devem sempre testar os limites dos modelos de fronteira e pensar sobre que tipos de aplicações seriam possíveis se a próxima geração de modelos superasse essas limitações. Combinados à incessante redução nos custos de inferência, os LRMs podem desbloquear muitas novas aplicações no próximo ano.
Alternativas aos transformadores estão ganhando força
O gargalo de memória e computação dos transformadores, a principal arquitetura de aprendizado profundo usada em LLMs, deu origem a um campo de modelos alternativos com complexidade linear. A arquitetura mais popular entre estas, o modelo de estado-espaço (SSM), teve muitos avanços no último ano. Outros modelos promissores incluem redes neurais líquidas (LNNs), que usam novas equações matemáticas para fazer muito mais com muitas menos neurônios artificiais e ciclos de computação.
No último ano, pesquisadores e laboratórios de IA lançaram modelos SSM puros, bem como modelos híbridos que combinam as forças dos transformadores e dos modelos lineares. Embora esses modelos ainda não tenham se apresentado no nível dos melhores modelos baseados em transformadores, eles estão alcançando rapidamente e já são ordens de magnitude mais rápidos e mais eficientes. Se o progresso nesse campo continuar, muitas aplicações LLM mais simples podem ser transferidas para esses modelos e executadas em dispositivos de borda ou servidores locais, onde as empresas podem usar dados específicos sem enviá-los a terceiros.
Mudanças nas leis de escalonamento
As leis de escalonamento dos LLMs estão em constante evolução. O lançamento do GPT-3 em 2020 provou que aumentar o tamanho do modelo continuaria a proporcionar resultados impressionantes e a permitir que os modelos realizassem tarefas para as quais não foram explicitamente treinados. Em 2022, a DeepMind lançou o paper Chinchilla, que estabeleceu uma nova direção nas leis de escalonamento de dados. O Chinchilla provou que treinando um modelo em um conjunto de dados imenso que é várias vezes maior que o número de seus parâmetros, você pode continuar a obter melhorias. Esse desenvolvimento permitiu que modelos menores competissem com modelos de fronteira com centenas de bilhões de parâmetros.
Hoje, há preocupações de que ambas as leis de escalonamento estejam próximas de seus limites. Relatórios indicam que laboratórios de fronteira estão enfrentando retornos decrescentes ao treinar modelos maiores. Ao mesmo tempo, os conjuntos de dados de treinamento já cresceram para dezenas de trilhões de tokens e obter dados de qualidade está se tornando cada vez mais difícil e caro.
Enquanto isso, os LRMs estão prometendo um novo vetor: escalonamento em tempo de inferência. Onde o tamanho do modelo e do conjunto de dados falham, podemos ser capazes de abrir novos caminhos permitindo que os modelos realizem mais ciclos de inferência e corrijam seus próprios erros.
Ao entrarmos em 2025, o cenário de IA continua a evoluir de maneiras inesperadas, com novas arquiteturas, capacidades de raciocínio e modelos econômicos remodelando o que é possível. Para as empresas dispostas a experimentar e se adaptar, essas tendências representam não apenas avanços tecnológicos, mas uma mudança fundamental em como podemos aproveitar a IA para resolver problemas do mundo real.


Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…