


Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder do setor. Saiba Mais
A geração aumentada por recuperação (RAG) se tornou a maneira padrão de personalizar grandes modelos de linguagem (LLMs) para informações sob medida. No entanto, RAG envolve custos técnicos iniciais e pode ser lenta. Agora, graças aos avanços nos LLMs de longo contexto, as empresas podem contornar o RAG inserindo todas as informações proprietárias no prompt.
Um novo estudo da Universidade Nacional Chengchi em Taiwan mostra que, usando LLMs de longo contexto e técnicas de caching, é possível criar aplicações personalizadas que superam os pipelines RAG. Chamado de geração aumentada por cache (CAG), essa abordagem pode ser uma substituição simples e eficiente para o RAG em configurações empresariais onde o corpus de conhecimento pode caber na janela de contexto do modelo.
Limitações do RAG
O RAG é um método eficaz para lidar com perguntas de domínio aberto e tarefas especializadas. Ele utiliza algoritmos de recuperação para reunir documentos relevantes à solicitação e adiciona contexto para permitir que o LLM elabore respostas mais precisas.
No entanto, o RAG traz várias limitações para aplicações de LLM. A etapa adicional de recuperação introduz latência que pode degradar a experiência do usuário. O resultado também depende da qualidade da seleção e classificação dos documentos. Em muitos casos, as limitações dos modelos usados para a recuperação exigem que os documentos sejam divididos em pedaços menores, o que pode prejudicar o processo de recuperação.
Além disso, o RAG adiciona complexidade à aplicação do LLM, exigindo o desenvolvimento, integração e manutenção de componentes adicionais. Essa sobrecarga desacelera o processo de desenvolvimento.
Recuperação aumentada por cache
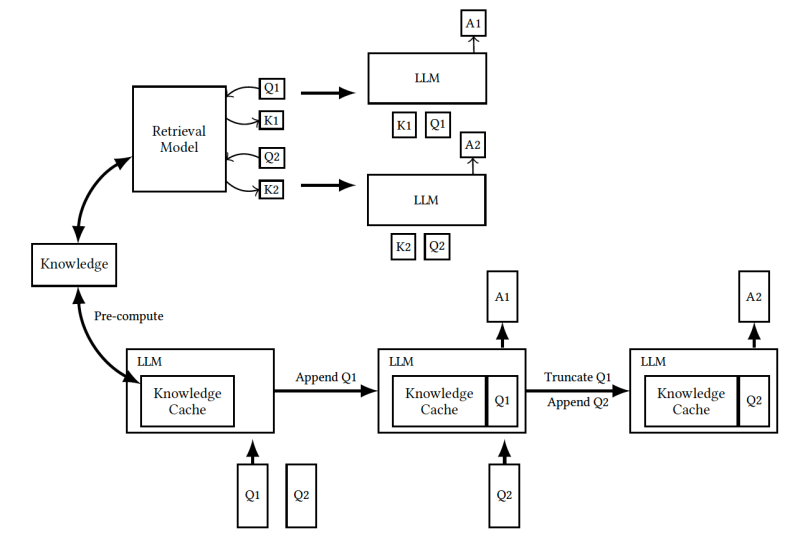
A alternativa a desenvolver um pipeline RAG é inserir todo o corpus de documentos no prompt e deixar o modelo escolher quais partes são relevantes para a solicitação. Essa abordagem elimina a complexidade do pipeline RAG e os problemas causados por erros de recuperação.
No entanto, há três desafios principais ao carregar todos os documentos no prompt. Primeiro, prompts longos retardarão o modelo e aumentarão os custos de inferência. Segundo, o tamanho da janela de contexto do LLM impõe limites ao número de documentos que podem caber no prompt. E finalmente, adicionar informações irrelevantes ao prompt pode confundir o modelo e reduzir a qualidade de suas respostas. Portanto, simplesmente encher o prompt com todos os seus documentos, em vez de escolher os mais relevantes, pode acabar prejudicando o desempenho do modelo.
A abordagem CAG proposta aproveita três tendências-chave para superar esses desafios.
Primeiro, técnicas de caching avançadas estão tornando mais rápido e barato processar templates de prompts. O pressuposto do CAG é que os documentos de conhecimento serão incluídos em todos os prompts enviados ao modelo. Portanto, você pode calcular os valores de atenção de seus tokens com antecedência, em vez de fazê-lo ao receber solicitações. Esse cálculo antecipado reduz o tempo necessário para processar as solicitações dos usuários.
Principais provedores de LLM, como OpenAI, Anthropic e Google, oferecem recursos de caching de prompt para partes repetitivas de seu prompt, que podem incluir os documentos de conhecimento e instruções que você insere no início do seu prompt. Com a Anthropic, você pode reduzir custos em até 90% e latência em 85% nas partes do prompt que são armazenadas em cache. Recursos de caching equivalentes foram desenvolvidos para plataformas de hospedagem de LLM de código aberto.
Segundo, LLMs de longo contexto estão facilitando a inclusão de mais documentos e conhecimento nos prompts. O Claude 3.5 Sonnet suporta até 200.000 tokens, enquanto o GPT-4o suporta 128.000 tokens e o Gemini, até 2 milhões de tokens. Isso torna possível incluir múltiplos documentos ou até mesmo livros inteiros no prompt.
E finalmente, métodos de treinamento avançados estão capacitando os modelos a realizar melhor recuperação, raciocínio e questionamento em sequências muito longas. No ano passado, pesquisadores desenvolveram vários benchmarks de LLM para tarefas de sequência longa, incluindo BABILong, LongICLBench e RULER. Esses benchmarks avaliam LLMs em problemas difíceis, como recuperação múltipla e questão-resposta de múltiplas etapas. Ainda há espaço para melhorias nessa área, mas laboratórios de IA continuam a fazer progresso.
À medida que gerações mais novas de modelos continuam a expandir suas janelas de contexto, eles poderão processar coleções de conhecimento maiores. Além disso, podemos esperar que os modelos continuem a melhorar em suas habilidades de extrair e usar informações relevantes de contextos longos.
“Essas duas tendências ampliarão significativamente a usabilidade de nossa abordagem, permitindo que ela lide com aplicações mais complexas e diversas”, afirmam os pesquisadores. “Consequentemente, nossa metodologia está bem posicionada para se tornar uma solução robusta e versátil para tarefas intensivas em conhecimento, aproveitando as capacidades crescentes dos LLMs de próxima geração.”
RAG vs CAG
Para comparar RAG e CAG, os pesquisadores realizaram experimentos em dois benchmarks de pergunta-resposta amplamente reconhecidos: SQuAD, que foca em Q&A com consciência de contexto a partir de documentos únicos, e HotPotQA, que requer raciocínio em múltiplas etapas através de vários documentos.
Eles utilizaram um modelo Llama-3.1-8B com uma janela de contexto de 128.000 tokens. Para o RAG, combinaram o LLM com dois sistemas de recuperação para obter trechos relevantes à pergunta: o básico algoritmo BM25 e embeddings da OpenAI. Para o CAG, inseriram múltiplos documentos do benchmark no prompt e deixaram o modelo determinar quais trechos utilizar para responder a pergunta. Seus experimentos mostram que o CAG superou ambos os sistemas RAG na maioria das situações.
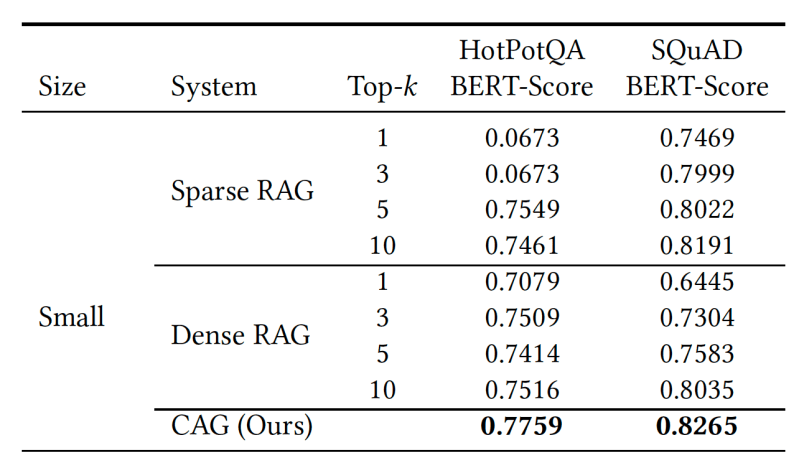
“Ao carregar todo o contexto do conjunto de testes, nosso sistema elimina erros de recuperação e assegura um raciocínio holístico sobre todas as informações relevantes,” escrevem os pesquisadores. “Essa vantagem é particularmente evidente em cenários onde os sistemas RAG podem recuperar trechos incompletos ou irrelevantes, levando a uma geração de respostas subótima.”
O CAG também reduz significativamente o tempo para gerar a resposta, especialmente à medida que o comprimento do texto de referência aumenta.
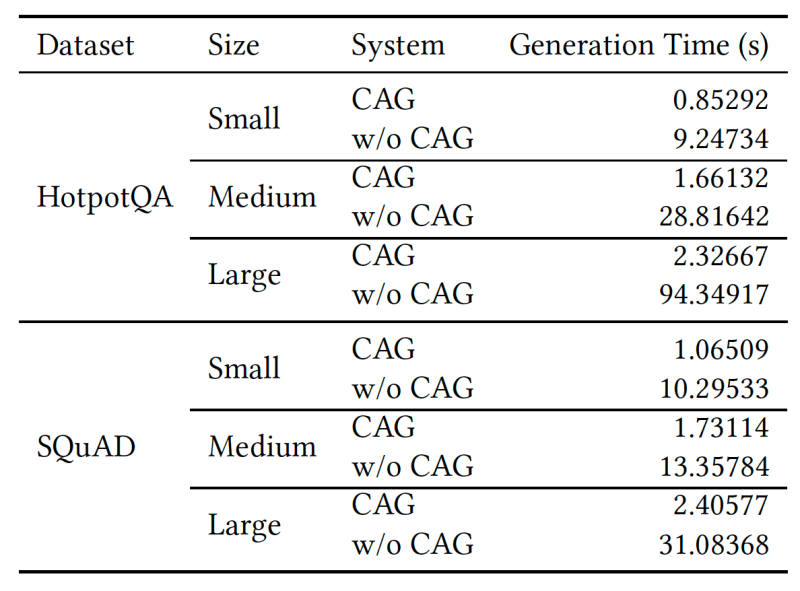
Dito isso, o CAG não é uma solução mágica e deve ser usado com cautela. Ele é bem adequado para configurações onde a base de conhecimento não muda com frequência e é pequena o suficiente para caber dentro da janela de contexto do modelo. As empresas também devem ter cuidado com casos em que seus documentos contenham fatos conflitantes com base no contexto dos documentos, o que pode confundir o modelo durante a inferência.
A melhor maneira de determinar se o CAG é adequado para seu caso de uso é realizar alguns experimentos. Felizmente, a implementação do CAG é muito simples e deve sempre ser considerada como um primeiro passo antes de investir em soluções RAG que exigem mais desenvolvimento.


Conteúdo relacionado

Meta revela uma API para seus modelos de IA Llama.
[the_ad id="145565"] Na sua conferência inaugural LlamaCon AI para desenvolvedores na terça-feira, a Meta anunciou uma API para sua série de modelos de IA Llama: a Llama API.…

Meta afirma que seus modelos de IA Llama foram baixados 1,2 bilhões de vezes.
[the_ad id="145565"] Em meados de março, a Meta anunciou que sua família de modelos de IA "abertos", Llama, atingiu 1 bilhão de downloads, um aumento em relação aos 650 milhões…

OpenAI reverte atualização que deixou o ChatGPT ‘muito bajulador’
[the_ad id="145565"] O CEO da OpenAI, Sam Altman, disse na terça-feira que a empresa está “desfazendo” a atualização mais recente do modelo padrão de IA que alimenta o ChatGPT,…