


Participe de nossas newsletters diárias e semanais para receber as últimas atualizações e conteúdos exclusivos sobre a cobertura de IA líder no setor. Saiba Mais
Um novo agente de IA surgiu da empresa mãe do TikTok para assumir o controle do seu computador e realizar fluxos de trabalho complexos.
Semelhante ao Computer Use da Anthropic, o novo UI-TARS da ByteDance entende interfaces gráficas (GUIs), aplica raciocínio e toma ações autônomas passo a passo.
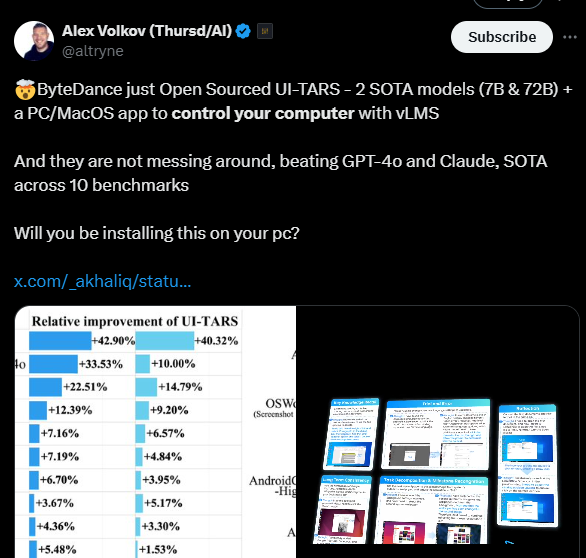
Treinado com aproximadamente 50 bilhões de tokens e disponível em versões de 7 bilhões e 72 bilhões de parâmetros, o agente para PC/MacOS alcança desempenho de ponta (SOTA) em mais de 10 benchmarks de GUI, abrangendo desempenho, percepção, ancoragem e capacidades gerais do agente, superando consistentemente o GPT-4o da OpenAI, Claude e o Gemini do Google.
“Através de treinamento iterativo e afinação de reflexão, o UI-TARS aprende continuamente com seus erros e se adapta a situações imprevistas com intervenção humana mínima,” escrevem os pesquisadores da ByteDance e da Universidade de Tsinghua em um novo artigo de pesquisa.
Como o UI-TARS explica seu raciocínio
O UI-TARS opera em aplicações de desktop, móveis e web, utilizando entradas multimodais (texto, imagens, interações) para entender ambientes visuais.
Suas funcionalidades de interface incluem duas abas — uma à esquerda, mostrando seu “pensamento” passo a passo, e uma maior à direita, onde ele acessa arquivos, websites e aplicativos, tomando ações automaticamente.
Por exemplo, em um vídeo de demonstração publicado hoje, o modelo é solicitado a “Encontrar voos de ida e volta de SEA para NYC no dia 5 e retornar no dia 10 do próximo mês e filtrar por preço em ordem ascendente.”
Em resposta, o UI-TARS navega até o site da Delta Airlines, preenche os campos “de” e “para”, seleciona as datas relevantes e ordena e filtra por preço, explicando cada passo em sua caixa de raciocínio antes de tomar ação.
Em outro cenário, ele é instruído a instalar uma extensão autoDocstring no VS Code. Aqui está seu raciocínio passo a passo enquanto conclui essa tarefa:
- Ele primeiro relata que “para proceder com a instalação da extensão autoDocstring no VS Code, primeiro preciso abrir o aplicativo VS Code.”
- Reconhecendo que a janela do VS Code não carregou completamente, o modelo observa que “é necessário esperar que o aplicativo termine de inicializar antes de prosseguir com a instalação da extensão autoDocstring. Isso garante que todas as funcionalidades necessárias estejam disponíveis para os próximos passos.”
- Em seguida, explica que deve acessar a visualização de Extensões no VS Code, o que pode ser feito clicando em uma aba na barra lateral esquerda.
- Ao enfrentar um pequeno problema, raciocina: “A tentativa anterior de clicar na aba ‘Extensões’ pode não ter sido precisa o suficiente, então tentarei clicar novamente para garantir que a visualização de Extensões seja aberta com sucesso.”
- Assim que estiver na visualização de Extensões, ele digita ‘autoDocstring’ antes de concluir: “Como o processo de instalação já foi iniciado, não há mais nenhuma ação necessária neste momento. Vou aguardar a conclusão da instalação e confirmar seu sucesso assim que o processo for finalizado.”

Superando seus rivais
Em uma variedade de benchmarks, os pesquisadores relatam que o UI-TARS consistentemente superou o GPT-4o da OpenAI; o Claude-3.5-Sonnet da Anthropic; o Gemini-1.5-Pro e o Gemini-2.0; quatro modelos Qwen; e numerosos modelos acadêmicos.
Por exemplo, no VisualWebBench — que mede a capacidade de um modelo de ancorar elementos da web, incluindo garantia de qualidade de página web e reconhecimento óptico de caracteres — o UI-TARS 72B marcou 82,8%, superando o GPT-4o (78,5%) e o Claude 3.5 (78,2%).
Ele também se saiu significativamente melhor nos benchmarks WebSRC (entendimento do conteúdo semântico e layout em contextos web) e ScreenQA-short (compreensão de layouts complexos de tela móvel e estrutura web). O UI-TARS-7B alcançou pontuações líderes de 93,6% no WebSRC, enquanto o UI-TARS-72B atingiu 88,6% no ScreenQA-short, superando Qwen, Gemini, Claude 3.5 e GPT-4o.
“Esses resultados demonstram as capacidades superiores de percepção e compreensão do UI-TARS em ambientes web e móveis,” escrevem os pesquisadores. “Essa habilidade perceptual estabelece a base para tarefas de agente, onde a compreensão precisa do ambiente é crucial para a execução de tarefas e tomada de decisões.”
O UI-TARS também obteve resultados impressionantes nas avaliações ScreenSpot Pro e ScreenSpot v2, que avaliam a capacidade de um modelo de entender e localizar elementos em GUIs. Além disso, os pesquisadores testaram suas capacidades no planejamento de ações em múltiplos passos e em tarefas de baixo nível em ambientes móveis, e o avaliaram no OSWorld (que avalia tarefas abertas no computador) e no AndroidWorld (que pontua agentes autônomos em 116 tarefas programáticas em 20 aplicativos móveis).
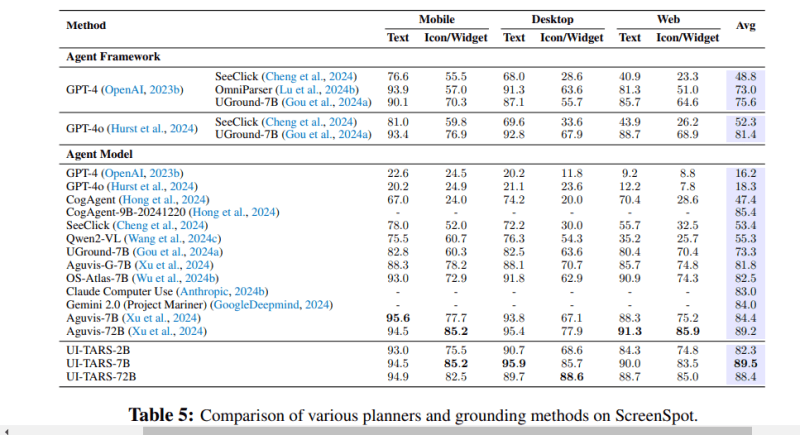
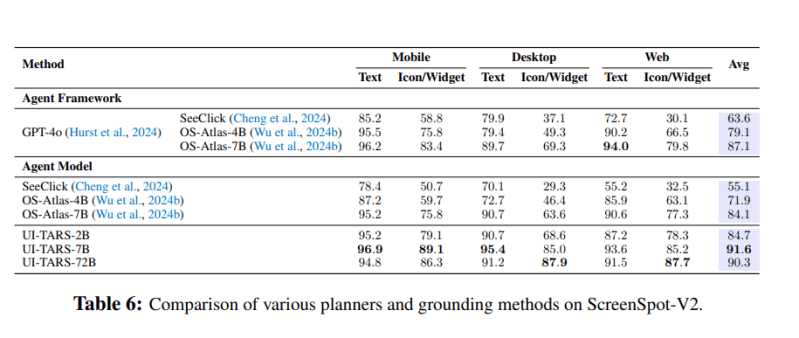
Sob o capô
Para ajudá-lo a realizar ações passo a passo e reconhecer o que está vendo, o UI-TARS foi treinado em um conjunto de dados em larga escala de capturas de tela que analisavam metadados incluindo descrição e tipo de elemento, descrição visual, caixas delimitadoras (informações de posição), função do elemento e texto de vários sites, aplicações e sistemas operacionais. Isso permite que o modelo forneça uma descrição abrangente e detalhada de uma captura de tela, capturando não apenas elementos, mas também relações espaciais e o layout geral.
O modelo também utiliza legendas de transição de estado para identificar e descrever as diferenças entre duas capturas de tela consecutivas e determinar se uma ação — como um clique do mouse ou uma entrada de teclado — ocorreu. Enquanto isso, o prompting set-of-mark (SoM) permite sobrepor marcas distintas (letras, números) em regiões específicas de uma imagem.
O modelo está equipado com memória de curto e longo prazo para lidar com tarefas em andamento, enquanto também retém interações históricas para melhorar a tomada de decisões posterior. Os pesquisadores treinaram o modelo para realizar tanto raciocínio do Sistema 1 (rápido, automático e intuitivo) quanto do Sistema 2 (lento e deliberado). Isso permite uma tomada de decisão em múltiplos passos, “pensamento reflexivo”, reconhecimento de marcos e correção de erros.
Os pesquisadores enfatizaram que é crítico que o modelo consiga manter metas consistentes e se envolver em tentativa e erro para formular hipóteses, testar e avaliar ações potenciais antes de concluir uma tarefa. Eles introduziram dois tipos de dados para apoiar isso: correção de erros e dados de pós-reflexão. Para a correção de erros, identificaram erros e etiquetaram ações corretivas; para a pós-reflexão, simularam etapas de recuperação.
“Essa estratégia garante que o agente não apenas aprenda a evitar erros, mas também se adapte dinamicamente quando eles ocorrem,” escrevem os pesquisadores.
Claramente, o UI-TARS exibe capacidades impressionantes, e será interessante ver suas aplicações em evolução no cada vez mais competitivo espaço de agentes de IA. Como observam os pesquisadores: “Olhando para o futuro, enquanto os agentes nativos representam um avanço significativo, o futuro reside na integração de aprendizado ativo e vitalício, onde os agentes conduzem autonomamente seu próprio aprendizado por meio de interações contínuas no mundo real.”
Os pesquisadores apontam que o Claude Computer Use “se destaca em tarefas baseadas na web, mas enfrenta dificuldades significativas em cenários móveis, indicando que a capacidade de operação de GUI do Claude não foi bem transferida para o domínio móvel.”
Por outro lado, “o UI-TARS exibe desempenho excelente tanto no domínio web quanto no móvel.”


Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…