


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba mais
Pesquisadores da Sakana AI, um laboratório de pesquisa em IA focado em algoritmos inspirados na natureza, desenvolveram um modelo de linguagem auto-adaptativo que pode aprender novas tarefas sem a necessidade de ajuste fino. Chamado de Transformer² (Transformer-quadrado), o modelo utiliza truques matemáticos para alinhar seus pesos com os pedidos dos usuários durante a inferência.
Esse é o mais recente de uma série de técnicas que visam melhorar as habilidades dos grandes modelos de linguagem (LLMs) durante o tempo de inferência, tornando-os cada vez mais úteis para aplicações do dia a dia em diferentes domínios.
Ajustando pesos dinamicamente
Geralmente, configurar LLMs para novas tarefas requer um caro processo de ajuste fino, durante o qual o modelo é exposto a novos exemplos e seus parâmetros são ajustados. Uma abordagem mais econômica é a “adaptação de baixa ordem” (LoRA), na qual um pequeno subconjunto dos parâmetros do modelo relevantes para a tarefa alvo é identificado e modificado durante o ajuste fino.
Após o treinamento e ajuste fino, os parâmetros do modelo permanecem congelados, e a única maneira de reaproveitá-lo para novas tarefas é por meio de técnicas como aprendizado com poucos ou muitos exemplos.
Diferente do ajuste fino clássico, o Transformer-quadrado utiliza uma abordagem em dois passos para ajustar dinamicamente seus parâmetros durante a inferência. Primeiro, analisa a solicitação recebida para entender a tarefa e seus requisitos, em seguida, aplica ajustes específicos à tarefa nos pesos do modelo para otimizar seu desempenho para aquele pedido específico.
“Ao ajustar seletivamente componentes críticos dos pesos do modelo, nossa estrutura permite que os LLMs se adaptem dinamicamente a novas tarefas em tempo real,” escrevem os pesquisadores em um post no blog publicado no site da empresa.
Como funciona o Transformer-quadrado da Sakana
A habilidade central do Transformer-quadrado é ajustar dinamicamente componentes críticos de seus pesos durante a inferência.
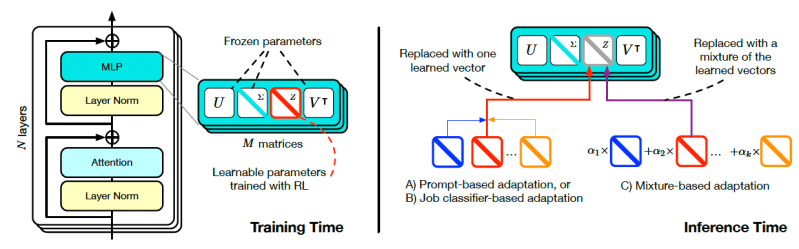
Para isso, ele precisa primeiro identificar os componentes-chave que podem ser ajustados durante a inferência. O Transformer-quadrado faz isso através da decomposição em valores singulares (SVD), um truque de álgebra linear que decompõe uma matriz em outras três matrizes que revelam sua estrutura interna e geometria. A SVD é frequentemente utilizada para compressão de dados ou para simplificar modelos de aprendizado de máquina.
Quando aplicada à matriz de pesos do LLM, a SVD obtém um conjunto de componentes que representam aproximadamente as diferentes habilidades do modelo, como matemática, compreensão de linguagem ou programação. Em seus experimentos, os pesquisadores descobriram que esses componentes podiam ser ajustados para modificar as habilidades do modelo em tarefas específicas.
Para aproveitar sistematicamente essas descobertas, eles desenvolveram um processo chamado ajuste fino de valores singulares (SVF). No tempo de treinamento, o SVF aprende um conjunto de vetores a partir dos componentes SVD do modelo. Esses vetores, chamados de vetores z, são representações compactas de habilidades individuais e podem ser utilizados como botões para amplificar ou atenuar a habilidade do modelo em tarefas específicas.
No tempo de inferência, o Transformer-quadrado usa um mecanismo de duas fases para adaptar o LLM a tarefas não vistas. Primeiro, examina o prompt para determinar as habilidades necessárias para tratar o problema (os pesquisadores propõem três técnicas diferentes para determinar as habilidades necessárias). Na segunda fase, o Transformer-quadrado configura os vetores z correspondentes ao pedido e executa o prompt pelo modelo e os pesos atualizados. Isso permite que o modelo forneça uma resposta personalizada a cada prompt.
Transformer-quadrado em ação
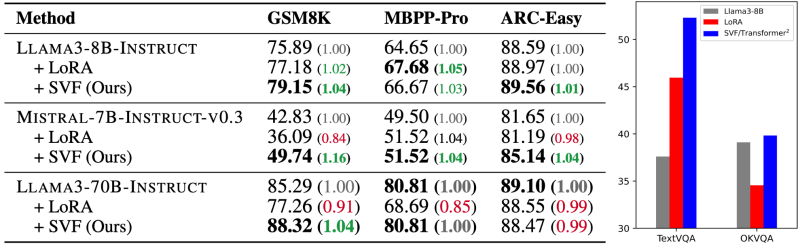
Os pesquisadores aplicaram o Transformer-quadrado aos LLMs Llama-3 e Mistral e os compararam ao LoRA em várias tarefas, incluindo matemática, programação, raciocínio e perguntas e respostas visuais. O Transformer-quadrado superou o LoRA em todos os benchmark enquanto tinha menos parâmetros. É notável também que, ao contrário do Transformer-quadrado, os modelos LoRA não podem adaptar seus pesos durante a inferência, o que os torna menos flexíveis.
Outra descoberta intrigante é que o conhecimento extraído de um modelo pode ser transferido para outro. Por exemplo, os vetores z obtidos dos modelos Llama poderiam ser aplicados aos modelos Mistral. Os resultados não atingiram o nível de criação de vetores z do zero para o modelo alvo, e a transferibilidade foi possível porque os dois modelos tinham arquiteturas semelhantes. Mas isso sugere a possibilidade de aprender vetores z generalizados que possam ser aplicados a uma ampla gama de modelos.
“O caminho a seguir reside na construção de modelos que se adaptem dinamicamente e colaborem com outros sistemas, combinando capacidades especializadas para resolver problemas complexos e multi-domínios,” escrevem os pesquisadores. “Sistemas auto-adaptativos como o Transformer² preenchem a lacuna entre a IA estática e a inteligência viva, pavimentando o caminho para ferramentas de IA eficientes, personalizadas e totalmente integradas que promovem o progresso em várias indústrias e em nossas vidas diárias.”
A Sakana AI disponibilizou o código para treinar os componentes do Transformer-quadrado no GitHub.
Truques de tempo de inferência
À medida que as empresas exploram diferentes aplicações de LLM, o último ano testemunhou uma mudança notável em direção ao desenvolvimento de técnicas de tempo de inferência. O Transformer-quadrado é uma das várias abordagens que permitem aos desenvolvedores personalizar LLMs para novas tarefas em tempo de inferência sem a necessidade de re-treinamento ou ajuste fino.
Titans, uma arquitetura desenvolvida por pesquisadores do Google, aborda o problema de uma maneira diferente, conferindo aos modelos de linguagem a capacidade de aprender e memorizar novas informações em tempo de inferência. Outras técnicas focam em permitir que LLMs de frontera aproveitem suas janelas de contexto cada vez maiores para aprender novas tarefas sem re-treinamento.
Com as empresas possuindo os dados e conhecimentos específicos para suas aplicações, os avanços nas técnicas de personalização em tempo de inferência tornarão os LLMs muito mais úteis.


Conteúdo relacionado

A xAI Holdings de Musk está supostamente arrecadando a segunda maior rodada de financiamento privado da história.
[the_ad id="145565"] A xAI Holdings de Elon Musk está em negociações para levantar US$ 20 bilhões em novos investimentos, o que pode avaliar a combinação de IA e mídias sociais…

Anthropic enviou um aviso de remoção a um desenvolvedor que tentava reverter o código de sua ferramenta.
[the_ad id="145565"] Na disputa entre duas ferramentas de código "agente" — Claude Code da Anthropic e Codex CLI da OpenAI — a última parece estar promovendo mais boa vontade…

O novo CEO da Intel sinaliza esforços de simplificação, mas não revela números exatos de demissões.
[the_ad id="145565"] Lip-Bu Tan, o novo CEO da Intel, enviou uma mensagem direta aos funcionários, afirmando que a empresa precisa se reorganizar para ser mais eficiente. Ele…