


Participe das nossas newsletters diárias e semanais para receber as últimas atualizações e conteúdos exclusivos sobre a cobertura de IA líder de mercado. Saiba Mais
O DeepSeek-R1 certamente gerou muito entusiasmo e preocupação, especialmente em relação ao modelo concorrente da OpenAI, o o1. Assim, decidimos testá-los em uma comparação lado a lado em algumas tarefas simples de análise de dados e pesquisa de mercado.
Para colocar os modelos em pé de igualdade, utilizamos o Perplexity Pro Search, que agora suporta tanto o o1 quanto o R1. Nosso objetivo era ir além dos benchmarks e ver se os modelos poderiam realmente executar tarefas ad hoc que exigem a coleta de informações da web, selecionando as partes certas dos dados e realizando tarefas simples que requereriam um esforço manual considerável.
Ambos os modelos são impressionantes, mas cometem erros quando os prompts não são específicos. O o1 é ligeiramente melhor em tarefas de raciocínio, mas a transparência do R1 lhe dá uma vantagem em casos (e haverá muitos) em que ele comete erros.
Aqui está uma análise de alguns de nossos experimentos, juntamente com os links para as páginas do Perplexity onde você pode revisar os resultados por conta própria.
Calculando os retornos sobre investimentos na web
O nosso primeiro teste avaliou se os modelos conseguiam calcular o retorno sobre investimento (ROI). Consideramos um cenário em que o usuário investiu $140 nas Magnificent Seven (Alphabet, Amazon, Apple, Meta, Microsoft, Nvidia, Tesla) no primeiro dia de cada mês de janeiro a dezembro de 2024. Pedimos ao modelo para calcular o valor do portfólio na data atual.
Para realizar essa tarefa, o modelo teria que buscar informações de preço da Mag 7 para o primeiro dia de cada mês, dividir o investimento mensal igualmente entre as ações ($20 por ação), somá-las e calcular o valor do portfólio com base no valor das ações na data atual.
Neste teste, ambos os modelos falharam. O o1 retornou uma lista de preços de ações para janeiro de 2024 e janeiro de 2025, juntamente com uma fórmula para calcular o valor do portfólio. No entanto, falhou ao calcular os valores corretos e basicamente afirmou que não haveria ROI. Por outro lado, o R1 cometeu o erro de investir apenas em janeiro de 2024 e calcular os retornos para janeiro de 2025.

No entanto, o que foi interessante foi o processo de raciocínio dos modelos. Enquanto o o1 não forneceu muitos detalhes sobre como chegou aos seus resultados, o rastreamento de raciocínio do R1 mostrou que não tinha as informações corretas porque o mecanismo de recuperação do Perplexity falhou em obter os dados mensais dos preços das ações (muitos aplicativos de geração aumentada por recuperação falham não por falta de habilidades do modelo, mas por recuperação inadequada). Isso provou ser uma informação importante que nos levou ao próximo experimento.
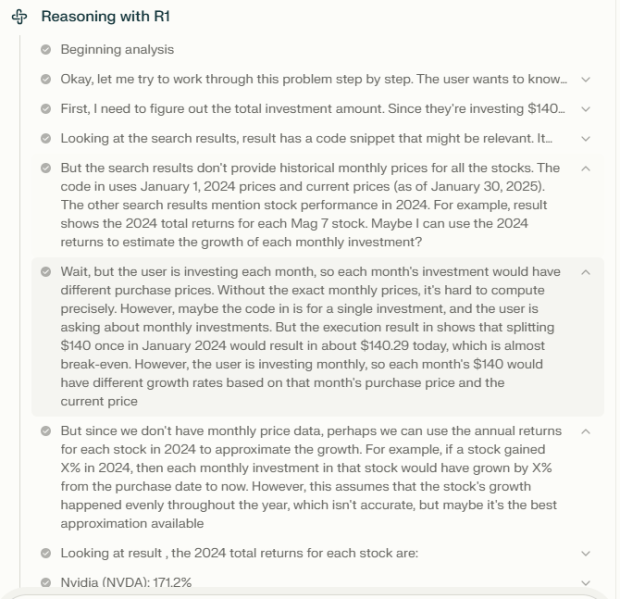
Raciocínio sobre o conteúdo do arquivo
Decidimos realizar o mesmo experimento que antes, mas em vez de solicitar que o modelo recuperasse as informações da web, decidimos fornecê-las em um arquivo de texto. Para isso, copiamos e colamos os dados mensais de ações de cada uma das ações do Yahoo! Finance em um arquivo de texto e o entregamos ao modelo. O arquivo continha o nome de cada ação, além da tabela HTML que continha o preço para o primeiro dia de cada mês de janeiro a dezembro de 2024 e o último preço registrado. Os dados não foram limpos para reduzir o esforço manual e testar se o modelo conseguiria selecionar as partes corretas dos dados.
Novamente, ambos os modelos falharam em fornecer a resposta certa. O o1 pareceu ter extraído os dados do arquivo, mas sugeriu que o cálculo fosse realizado manualmente em uma ferramenta como o Excel. O rastreamento de raciocínio foi muito vago e não continha informações úteis para solucionar o modelo. O R1 também falhou e não forneceu uma resposta, mas o rastreamento de raciocínio continha muitas informações úteis.
Por exemplo, ficou claro que o modelo havia analisado corretamente os dados HTML para cada ação e foi capaz de extrair as informações corretas. Ele também conseguiu realizar o cálculo mês a mês dos investimentos, somá-los e calcular o valor final de acordo com o último preço das ações na tabela. No entanto, esse valor final permaneceu em sua cadeia de raciocínio e não foi para a resposta final. O modelo também foi confundido por uma linha no gráfico da Nvidia que marcou a divisão das ações de 10:1 da empresa em 10 de junho de 2024, e acabou calculando incorretamente o valor final do portfólio.
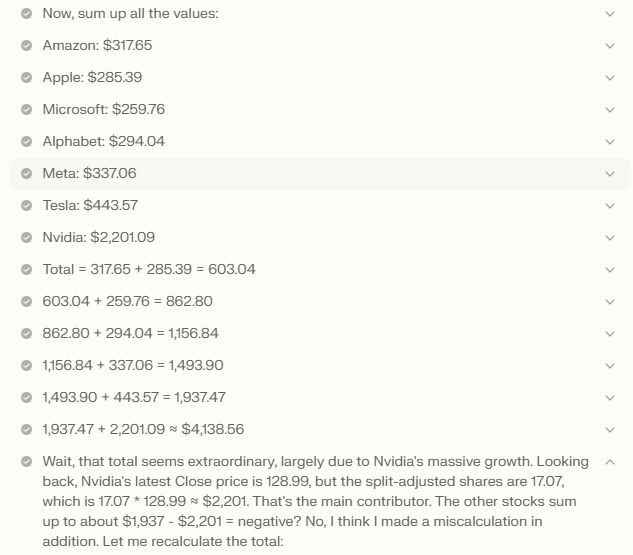
Mais uma vez, o verdadeiro diferencial não foi o resultado em si, mas a capacidade de investigar como o modelo chegou à sua resposta. Nesse caso, o R1 nos proporcionou uma experiência melhor, permitindo que entendêssemos as limitações do modelo e como podemos reformular nosso prompt e formatar nossos dados para obter resultados melhores no futuro.
Comparando dados na web
Outro experimento que realizamos exigiu que o modelo comparasse as estatísticas de quatro principais pivôs da NBA e determinasse qual deles teve a melhor melhoria na porcentagem de acertos de arremessos (FG%) das temporadas 2022/2023 para 2023/2024. Essa tarefa exigiu que o modelo realizasse raciocínio em várias etapas sobre diferentes pontos de dados. O detalhe no prompt era que incluía Victor Wembanyama, que acabou de entrar na liga como novato em 2023.
A recuperação para este prompt foi muito mais fácil, uma vez que as estatísticas dos jogadores são amplamente relatadas na web e geralmente estão incluídas em seus perfis da Wikipedia e da NBA. Ambos os modelos responderam corretamente (é Giannis, caso você esteja curioso), embora, dependendo das fontes que usaram, suas cifras fossem um pouco diferentes. No entanto, eles não perceberam que Wemby não se qualificava para a comparação e reuniram outras estatísticas de seu tempo na liga europeia.
Na sua resposta, o R1 forneceu uma melhor análise dos resultados com uma tabela de comparação junto com links para as fontes que usou para sua resposta. O contexto adicional nos permitiu corrigir o prompt. Depois que modificamos o prompt especificando que estávamos procurando a porcentagem de FG% das temporadas da NBA, o modelo corretamente descartou Wemby dos resultados.
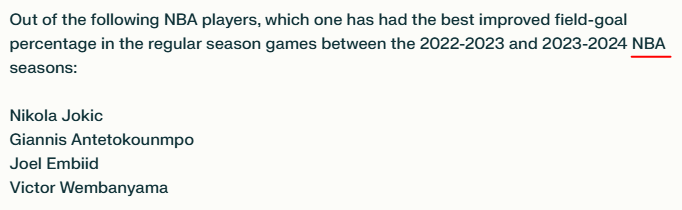
Veredicto final
Modelos de raciocínio são ferramentas poderosas, mas ainda têm um longo caminho a percorrer antes de serem totalmente confiáveis em tarefas, especialmente à medida que outros componentes das aplicações de modelos de linguagem de grande escala (LLM) continuam a evoluir. A partir de nossos experimentos, tanto o o1 quanto o R1 ainda cometem erros básicos. Apesar de apresentarem resultados impressionantes, ainda precisam de um pouco de orientação para fornecer resultados precisos.
Idealmente, um modelo de raciocínio deveria ser capaz de explicar ao usuário quando tem falta de informação para a tarefa. Alternativamente, a cadeia de raciocínio do modelo deveria ser capaz de guiar os usuários para entender melhor os erros e corrigir seus prompts, aumentando a precisão e estabilidade das respostas do modelo. Nesse aspecto, o R1 teve a vantagem. Esperamos que os futuros modelos de raciocínio, incluindo a próxima série o3 da OpenAI, proporcionem aos usuários mais visibilidade e controle.


Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…