


As manchetes continuam a surgir. Os modelos da DeepSeek têm desafiado referências, estabelecendo novos padrões e gerando muito barulho. No entanto, algo interessante acaba de acontecer na cena de pesquisa em IA que também merece sua atenção.
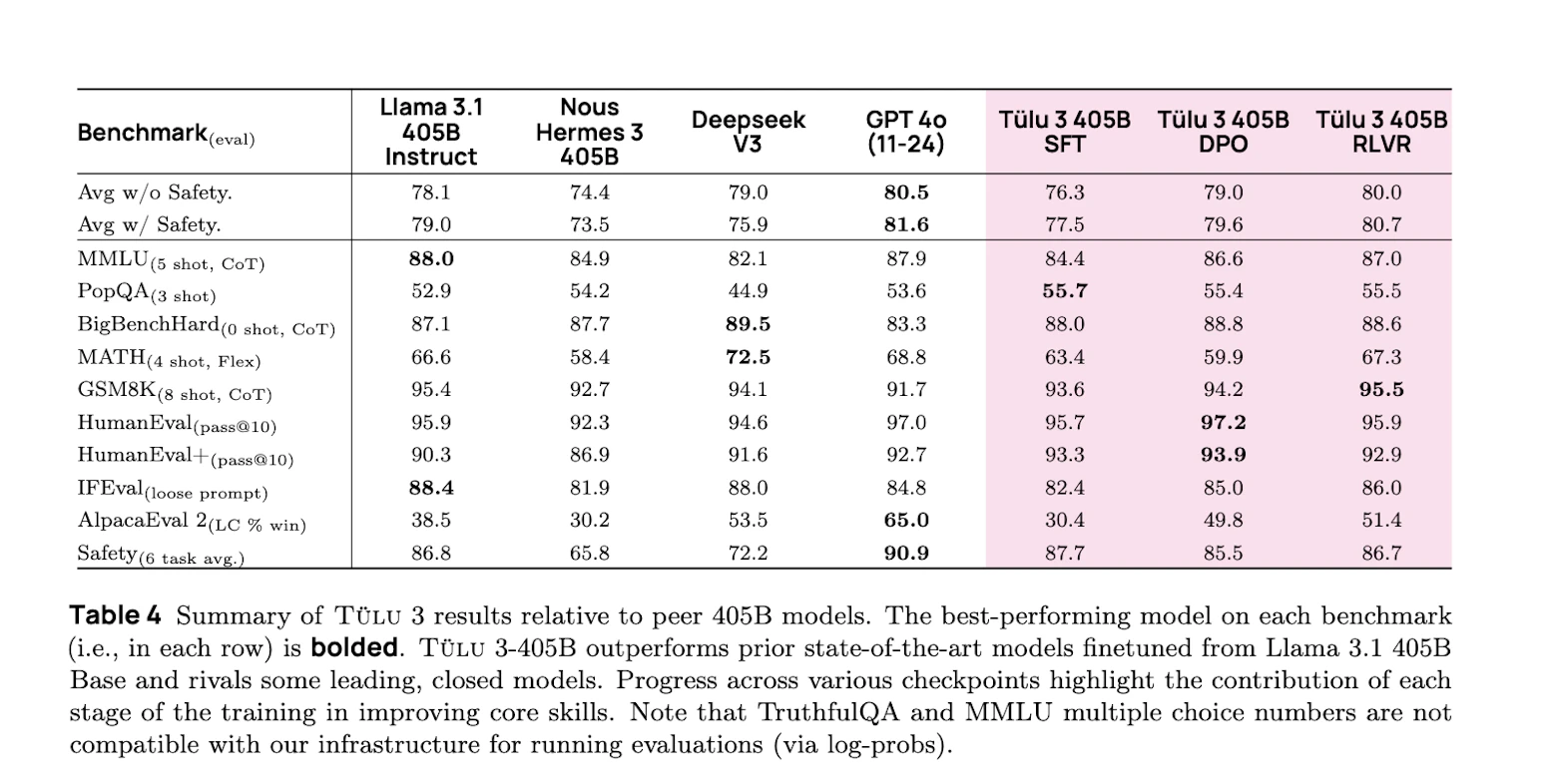
Allen AI lançou discretamente sua nova família de modelos Tülu 3, e sua versão de 405 bilhões de parâmetros não está apenas competindo com a DeepSeek – ela está igualando ou superando em benchmarks importantes.
Vamos colocar isso em perspectiva.
O modelo Tülu 3 de 405 bilhões de parâmetros está se enfrentando com os principais desempenhos, como o DeepSeek V3, em uma variedade de tarefas. Estamos vendo um desempenho comparável ou superior em áreas como problemas matemáticos, desafios de programação e seguimento de instruções precisas. E eles fazem isso com uma abordagem totalmente aberta.
Eles liberaram todo o pipeline de treinamento, o código e até mesmo seu novo método de aprendizado por reforço chamado Aprendizado por Reforço com Recompensas Verificáveis (RLVR), que viabilizou isso.
Desenvolvimentos como esses nas últimas semanas estão realmente mudando a maneira como acontece o desenvolvimento de IA de alto nível. Quando um modelo totalmente de código aberto pode igualar os melhores modelos fechados, isso abre possibilidades que antes estavam trancadas atrás de muros corporativos privados.
A Batalha Técnica
O que fez o Tülu 3 se destacar? Tudo se resume a um processo de treinamento único em quatro estágios que vai além das abordagens tradicionais.
Vamos analisar como a Allen AI construiu este modelo:
Estágio 1: Seleção Estratégica de Dados
A equipe sabia que a qualidade do modelo começa com a qualidade dos dados. Eles combinaram conjuntos de dados estabelecidos, como WildChat e Open Assistant, com conteúdo gerado customizadamente. Mas aqui está a chave: eles não apenas agregaram dados – eles criaram conjuntos de dados direcionados para habilidades específicas, como raciocínio matemático e proficiência em programação.
Estágio 2: Construindo Respostas Melhores
No segundo estágio, a Allen AI concentrou-se em ensinar suas habilidades específicas ao modelo. Eles criaram diferentes conjuntos de dados de treinamento – alguns para matemática, outros para programação e mais para tarefas gerais. Ao testar essas combinações repetidamente, podiam ver exatamente onde o modelo se destacava e onde precisava de melhorias. Esse processo iterativo revelou o verdadeiro potencial do que o Tülu 3 poderia alcançar em cada área.
Estágio 3: Aprendendo com Comparações
É aqui que a Allen AI foi criativa. Eles construíram um sistema que poderia comparar instantaneamente as respostas do Tülu 3 com outros modelos de topo. Mas também resolveram um problema persistente na IA – a tendência dos modelos de escrever respostas longas apenas pela extensão. Sua abordagem, utilizando otimização de preferência normalizada por comprimento (DPO), fez com que o modelo aprendesse a valorizar qualidade em vez de quantidade. O resultado? Respostas tanto precisas quanto intencionais.
Quando os modelos de IA aprendem com as preferências (qual resposta é melhor, A ou B?), eles tendem a desenvolver um viés frustrante: começam a pensar que respostas mais longas são sempre melhores. É como se eles estivessem tentando vencer dizendo mais, em vez de dizer as coisas bem.
A normalização do comprimento do DPO corrige isso, ajustando como o modelo aprende com as preferências. Em vez de apenas examinar qual resposta foi preferida, considera o comprimento de cada resposta. Pense nisso como julgar respostas pela qualidade por palavra, não apenas pelo impacto total.
Por que isso importa? Porque ajuda o Tülu 3 a aprender a ser preciso e eficiente. Em vez de acrescentar palavras extras para parecer mais abrangente, aprende a oferecer valor no comprimento que realmente é necessário.
Isso pode parecer um pequeno detalhe, mas é crucial para construir IA que se comunica naturalmente. Os melhores especialistas humanos sabem quando ser concisos e quando elaborar – e isso é exatamente o que o DPO normalizado por comprimento ajuda a ensinar ao modelo.
Estágio 4: A Inovação RLVR
Essa é a inovação técnica que merece atenção. O RLVR substitui modelos de recompensa subjetivos por verificações concretas.
A maioria dos modelos de IA aprende através de um sistema complexo de modelos de recompensa – essencialmente, palpites educados sobre o que faz uma boa resposta. Mas a Allen AI tomou um caminho diferente com o RLVR.
Pense sobre como normalmente treinamos modelos de IA. Geralmente, precisamos de outros modelos de IA (chamados de modelos de recompensa) para julgar se uma resposta é boa ou não. É subjetivo, complexo e muitas vezes inconsistente. Algumas respostas podem parecer boas, mas contêm erros sutis que escapam.
O RLVR inverte essa abordagem. Em vez de depender de julgamentos subjetivos, usa resultados concretos e verificáveis. Quando o modelo tenta um problema matemático, não há área cinza – a resposta está certa ou errada. Quando escreve código, esse código funciona corretamente ou não.
Aqui é onde fica interessante:
- O modelo recebe feedback imediato e binário: 10 pontos para respostas corretas, 0 para incorretas
- Não há espaço para crédito parcial ou avaliação confusa
- O aprendizado se torna focado e preciso
- O modelo aprende a priorizar a precisão em vez de respostas plausíveis, mas incorretas
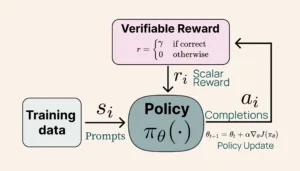
Treinamento RLVR (Allen AI)
Os resultados? O Tülu 3 demonstrou melhorias significativas em tarefas onde a correção é mais importante. Seu desempenho em raciocínio matemático (benchmark GSM8K) e desafios de programação aumentou notavelmente. Mesmo seu seguimento de instruções se tornou mais preciso porque o modelo aprendeu a valorizar a exatidão concreta em vez de respostas aproximadas.
O que torna isso particularmente emocionante é como isso muda o jogo para IA de código aberto. Abordagens anteriores frequentemente lutavam para igualar a precisão dos modelos fechados em tarefas técnicas. O RLVR mostra que, com a abordagem de treinamento certa, modelos de código aberto podem alcançar o mesmo nível de confiabilidade.
Uma Olhada nos Números
A versão de 405 bilhões de parâmetros do Tülu 3 compete diretamente com os melhores modelos do campo. Vamos examinar onde ele se destaca e o que isso significa para a IA de código aberto.
Matemática
O Tülu 3 se destaca em raciocínio matemático complexo. Em benchmarks como GSM8K e MATH, iguala o desempenho da DeepSeek. O modelo lida com problemas de múltiplas etapas e demonstra fortes capacidades de raciocínio matemático.
Código
Os resultados em programação são igualmente impressionantes. Graças ao treinamento RLVR, o Tülu 3 escreve código que resolve problemas de maneira eficaz. Sua força reside na compreensão de instruções de programação e na produção de soluções funcionais.
Seguimento Preciso de Instruções
A capacidade do modelo de seguir instruções se destaca como uma força central. Enquanto muitos modelos aproximam ou generalizam instruções, o Tülu 3 demonstra uma precisão notável ao executar exatamente o que lhe é solicitado.
Abertura da Caixa Preta do Desenvolvimento de IA
A Allen AI lançou um modelo poderoso e todo o seu processo de desenvolvimento.
Cada aspecto do processo de treinamento está documentado e acessível. Desde a abordagem em quatro etapas até os métodos de preparação de dados e a implementação do RLVR – todo o processo está aberto para estudo e replicação. Essa transparência estabelece um novo padrão no desenvolvimento de IA de alto desempenho.
Os desenvolvedores recebem recursos abrangentes:
- Pipelines de treinamento completos
- Ferramentas de processamento de dados
- Estruturas de avaliação
- Especificações de implementação
Isso permite que as equipes:
- Modifiquem processos de treinamento
- Adaptem métodos para necessidades específicas
- Construam sobre abordagens comprovadas
- Criem implementações especializadas
Essa abordagem aberta acelera a inovação em todo o campo. Pesquisadores podem construir sobre métodos verificados, enquanto os desenvolvedores podem se concentrar em melhorias, em vez de começar do zero.
A Ascensão da Excelência em Código Aberto
O sucesso do Tülu 3 é um grande momento para o desenvolvimento de IA aberta. Quando modelos de código aberto igualam ou superam alternativas privadas, isso muda fundamentalmente a indústria. Equipes de pesquisa em todo o mundo ganham acesso a métodos comprovados, acelerando seu trabalho e gerando novas inovações. Laboratórios privados de IA precisarão se adaptar – seja aumentando a transparência ou ultrapassando ainda mais os limites técnicos.
Olhando para o futuro, os avanços do Tülu 3 em recompensas verificáveis e treinamento em múltiplas etapas sugerem o que está por vir. As equipes podem construir sobre essas fundações, potencialmente elevando ainda mais o desempenho. O código existe, os métodos estão documentados e uma nova onda de desenvolvimento de IA começou. Para desenvolvedores e pesquisadores, a oportunidade de experimentar e aprimorar esses métodos marca o início de um capítulo emocionante no desenvolvimento de IA.
Perguntas Frequentes (FAQ) sobre o Tülu 3
O que é o Tülu 3 e quais são suas características principais?
O Tülu 3 é uma família de LLMs de código aberto desenvolvidos pela Allen AI, baseados na arquitetura Llama 3.1. Ele vem em vários tamanhos (8B, 70B e 405B parâmetros). O Tülu 3 é projetado para melhorar o desempenho em diversas tarefas, incluindo conhecimento, raciocínio, matemática, programação, seguimento de instruções e segurança.
Qual é o processo de treinamento do Tülu 3 e quais dados são utilizados?
O treinamento do Tülu 3 envolve várias etapas principais. Primeiro, a equipe seleciona um conjunto diversificado de prompts de conjuntos de dados públicos e dados sintéticos voltados para habilidades específicas, garantindo que os dados estejam limpos em relação a benchmarks. Em seguida, realiza a afinamento supervisionado (SFT) em uma mistura de dados de seguimento de instruções, matemática e programação. Depois, utiliza a otimização de preferência direta (DPO) com dados de preferência gerados através de feedback humano e de LLM. Por último, a Aprendizagem por Reforço com Recompensas Verificáveis (RLVR) é usada para tarefas com correção mensurável. O Tülu 3 usa conjuntos de dados curados para cada etapa, incluindo instruções orientadas por persona, dados de matemática e programação.
Como o Tülu 3 aborda a segurança e quais métricas são utilizadas para avaliá-la?
A segurança é um componente central do desenvolvimento do Tülu 3, abordada ao longo do processo de treinamento. Um conjunto de dados específico para segurança é utilizado durante o SFT, que se mostrou em grande parte ortogonal a outros dados voltados para tarefas.
O que é RLVR?
RLVR é uma técnica onde o modelo é treinado para otimizar contra uma recompensa verificável, como a correção de uma resposta. Isso difere do RLHF tradicional que usa um modelo de recompensa.

Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…