


Um novo estudo realizado por pesquisadores da LMU Munique, do Centro de Aprendizado de Máquina de Munique e da Adobe Research revelou uma fraqueza nos modelos de linguagem de IA: eles têm dificuldades para entender documentos longos de maneiras que podem surpreender. Os achados da equipe de pesquisa mostram que mesmo os modelos de IA mais avançados têm problemas para conectar informações quando não podem contar com simples correspondências de palavras.
O Problema Oculto nas Habilidades de Leitura da IA
Imagine tentar encontrar um detalhe específico em um longo artigo de pesquisa. Você pode folheá-lo, fazendo conexões mentais entre diferentes seções para juntar as informações de que precisa. Muitos modelos de IA, ao que parece, não funcionam assim. Em vez disso, eles muitas vezes dependem fortemente de encontrar correspondências exatas de palavras, semelhante ao uso de Ctrl+F em seu computador.
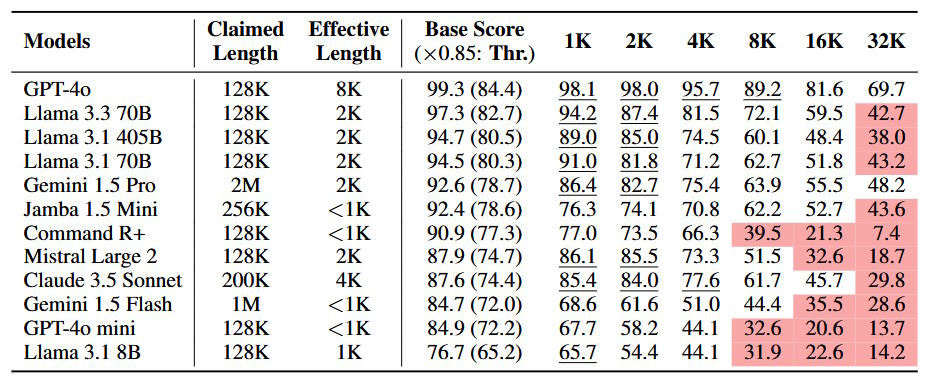
A equipe de pesquisa desenvolveu um novo referencial chamado NOLIMA (No Literal Matching) para testar vários modelos de IA. Os resultados mostraram que, ao lidar com textos mais longos que 2.000 palavras, o desempenho dos modelos de IA cai drasticamente. Quando alcançam 32.000 palavras – cerca do comprimento de um pequeno livro – a maioria dos modelos opera a metade de sua capacidade habitual. Isso incluiu testes de grandes modelos como GPT-4o, Gemini 1.5 Pro e Llama 3.3 70B.
Considere um pesquisador médico usando IA para analisar registros de pacientes, ou uma equipe jurídica utilizando IA para revisar documentos de casos. Se a IA perder conexões cruciais porque as informações relevantes usam palavras diferentes da consulta, as consequências podem ser significativas.
Por que a Correspondência de Palavras Não É Suficiente
Os modelos de IA atuais processam texto utilizando um mecanismo de atenção. Esse sistema ajuda a IA a se concentrar em diferentes partes do texto para entender relacionamentos entre palavras e ideias. Quando trabalha com textos mais curtos, isso funciona bem o suficiente. No entanto, a pesquisa mostra que esse mecanismo fica sobrecarregado à medida que os textos se tornam mais longos, especialmente quando não pode contar com correspondências de palavras exatas.
O teste NOLIMA revelou essa limitação ao fazer perguntas para os modelos de IA cujas respostas exigiam compreensão do contexto, em vez de encontrar palavras correspondentes. Os resultados foram reveladores. Enquanto os modelos se saíram bem com textos curtos, sua capacidade de fazer essas conexões caiu significativamente à medida que o comprimento do texto aumentou. Mesmo modelos especializados projetados para tarefas de raciocínio pontuaram abaixo de 50% de precisão ao lidar com documentos mais longos.
Sem a muleta da correspondência de palavras, os modelos de IA lutaram para:
- Conectar conceitos relacionados que usam terminologias diferentes
- Seguir caminhos de raciocínio multi-etapa
- Encontrar informações relevantes quando apareciam após o contexto-chave
- Ignorar correspondências de palavras enganosas em seções irrelevantes
Os Números Contam a História
As descobertas da pesquisa pintam um quadro claro de como os modelos de IA lidam com textos mais longos. O GPT-4o mostrou o melhor desempenho, mantendo eficácia até cerca de 8.000 tokens (aproximadamente 6.000 palavras). Contudo, mesmo este modelo de destaque mostrou um declínio significativo com textos mais longos. A maioria dos outros modelos, incluindo Gemini 1.5 Pro e Llama 3.3 70B, experimentou quedas acentuadas de desempenho entre 2.000 e 8.000 tokens.
O declínio no desempenho se tornou ainda mais pronunciado quando as tarefas exigiam múltiplos passos de raciocínio. Por exemplo, se um modelo precisasse fazer duas conexões lógicas – como entender que um personagem morava perto de um marco e que esse marco estava em uma cidade específica – a taxa de sucesso caiu consideravelmente. A pesquisa mostrou que esse tipo de raciocínio multi-etapa se tornou particularmente desafiador em textos além de 16.000 tokens, mesmo ao usar técnicas projetadas para melhorar o raciocínio, como Chain-of-Thought prompting.
O que torna essas descobertas particularmente significativas é que desafiam as alegações sobre a capacidade dos modelos de IA de lidar com longos contextos. Embora muitos modelos anunciem suporte para janelas de contexto extensas, o referencial NOLIMA mostra que a compreensão efetiva cai muito antes de se atingir esses limites teóricos.
Fonte: Modarressi et al.
Quando a IA Perde a Visão Geral por Detalhes
Essas limitações têm implicações sérias sobre como usamos a IA em aplicações do mundo real. Considere um sistema jurídico de IA procurando por jurisprudência. Ele pode perder precedentes relevantes simplesmente porque usam terminologias diferentes da consulta. O sistema pode, em vez disso, focar em casos menos relevantes que compartilham mais palavras com os termos de busca.
O impacto na busca e análise de documentos é particularmente preocupante. Os sistemas de busca atualmente impulsionados por IA muitas vezes dependem de uma técnica chamada Geração Aumentada por Recuperação (RAG). Mesmo quando esses sistemas recuperam com sucesso um documento que contém a informação correta, a IA pode falhar em reconhecer sua relevância se a redação diferir da consulta. Em vez disso, a IA pode se inclinar para documentos menos relevantes que compartilham semelhanças superficiais com os termos de busca.
Para os usuários de IA, essas descobertas sugerem várias considerações importantes:
Primeiro, consultas e documentos mais curtos provavelmente resultarão em respostas mais confiáveis. Ao trabalhar com textos mais longos, dividir em segmentos menores e focados pode ajudar a manter o desempenho da IA.
Segundo, os usuários devem ter especial cuidado ao pedir que a IA faça conexões entre diferentes partes de um longo documento. A pesquisa mostra que os modelos de IA enfrentam mais dificuldades quando precisam juntar informações de diferentes seções, especialmente quando a conexão não é óbvia por meio de um vocabulário compartilhado.
Por fim, essas limitações destacam a importância contínua da supervisão humana. Embora a IA possa ser uma ferramenta poderosa para processar e analisar textos, não deve ser usada como o único meio de identificar conexões importantes em documentos longos ou complexos.
As descobertas servem como um lembrete de que, apesar dos rápidos avanços na tecnologia de IA, esses sistemas ainda processam informações de maneira muito diferente dos humanos. Compreender essas limitações é crucial para usar ferramentas de IA de forma eficaz e saber quando o julgamento humano continua sendo essencial.
O Que Vem a Seguir
Entender as limitações da capacidade dos modelos atuais de IA para processar textos longos levanta questões importantes sobre o futuro do desenvolvimento da IA. A pesquisa por trás do referencial NOLIMA revelou que nossas abordagens atuais para o processamento de texto em IA podem precisar de refinamento significativo, particularmente em como os modelos lidam com informações em passagens mais longas.
As soluções atuais mostraram apenas sucesso parcial. O Chain-of-Thought prompting, que incentiva os modelos de IA a dividir seu raciocínio em etapas, ajuda a melhorar o desempenho um pouco. Por exemplo, ao usar essa técnica, o Llama 3.3 70B demonstrou uma melhor capacidade de lidar com contextos mais longos. No entanto, essa abordagem ainda não é suficiente ao lidar com textos além de 16.000 tokens, sugerindo que precisamos de soluções mais fundamentais.
O mecanismo de atenção, que forma a base de como os modelos de IA atuais processam o texto, precisa ser repensado. Pense nisso como tentar manter uma conversa em uma sala cheia – quanto mais longa a conversa, mais difícil se torna acompanhar todos os pontos importantes mencionados anteriormente. Nossos atuais modelos de IA enfrentam um desafio semelhante, mas em uma escala muito maior.
Olhando para o futuro, os pesquisadores estão explorando várias direções promissoras. Uma abordagem envolve desenvolver novas maneiras para a IA organizar e priorizar informações em textos longos, movendo-se além da simples correspondência de palavras para entender conexões conceituais mais profundas. Isso pode funcionar mais como os humanos criam mapas mentais de informações, conectando ideias com base no significado em vez de apenas no vocabulário compartilhado.
Outra área de desenvolvimento se concentra em melhorar como os modelos de IA lidam com o que os pesquisadores chamam de “saltos latentes” – os passos lógicos necessários para conectar diferentes peças de informação. Os modelos atuais lutam com essas conexões, especialmente em textos mais longos, mas novas arquiteturas podem ajudar a preencher essa lacuna.
Para aqueles que trabalham com ferramentas de IA hoje, essas descobertas sugerem várias abordagens práticas:
Considere dividir documentos mais longos em segmentos significativos ao trabalhar com IA. Isso ajuda a criar seções lógicas que preservam o contexto importante. Por exemplo, se estiver analisando um artigo de pesquisa, você pode manter as seções de metodologia e resultados juntas, uma vez que costumam conter informações relacionadas.
Ao pedir à IA para analisar textos mais longos, seja específico sobre as conexões que você deseja que ela faça. Em vez de fazer perguntas amplas, guie a IA para os relacionamentos específicos que você está interessado em explorar. Isso ajuda a compensar as limitações atuais do modelo em fazer essas conexões de forma independente.
Talvez o mais importante, mantenha expectativas realistas sobre as capacidades da IA com textos longos. Embora essas ferramentas possam ser extremamente úteis para muitas tarefas, não devem ser vistas como substitutos completos para a análise humana de documentos complexos. A habilidade humana de manter o contexto e fazer conexões conceituais em textos longos continua sendo superior às capacidades atuais da IA.
O caminho à frente para o desenvolvimento da IA nesta área é desafiador e empolgante. À medida que compreendemos melhor essas limitações, podemos trabalhar em direção a sistemas de IA que realmente compreendam textos longos em vez de apenas processá-los. Até lá, usar a IA de forma eficaz significa trabalhar com suas limitações atuais, ao mesmo tempo em que apreciamos suas forças.

Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…