


Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre a cobertura líder da indústria em IA. Saiba Mais
A startup Hume AI de Nova York emergiu da ocultação há dois anos e desde então arrecadou milhões com base em sua tecnologia que criam vozes de IA emotivas para uso em aplicações empresariais.
Hoje, a empresa está levando suas ofertas um passo além com um novo modelo de linguagem e fala chamado “motor de texto e voz onipresente”, ou Octave, projetado para produzir fala realista e emocionalmente sutil para uso em diferentes formas de conteúdo, desde audiolivros até diálogos pré-gravados de personagens de videogame e filmes/TV/vídeos.
A Hume afirma que o Octave é o primeiro sistema de texto-para-fala (TTS) impulsionado por um modelo de linguagem grande (LLM) treinado não apenas em texto, mas também em tokens de fala e emoção, permitindo-lhe entender palavras em contexto e ajustar o tom, o ritmo e a cadência de acordo — e que o usuário pode ajustar a nível de frase com comandos textuais.
“Estamos lançando o primeiro LLM para texto-para-fala—um modelo que entende palavras em contexto, prevendo as emoções certas, ritmo, cadência e ênfase, fazendo com que a fala soe mais humana do que nunca,” disse Alan Cowen, cofundador e CEO da Hume AI, em uma entrevista por vídeo com o VentureBeat.
As capacidades do Octave vão além da simples geração de voz. Ele pode interpretar características de personagens e estilos apenas a partir de um roteiro, ajustando inflexões vocais para combinar com emoções implícitas. Uma observação sarcástica será falada de maneira sarcástica, uma frase apressada soará urgente, e um segredo sussurrado será baixo—tudo isso sem precisar de direções explícitas.
Além disso, se o usuário não gostar da voz gerada ou quiser ajustá-la, ele pode fazê-lo de forma granular através de linguagem natural, simplesmente digitando uma instrução de texto para o Octave, como “mais alegre, mais triste, mais frustrado, mais irritado, mais sarcástico, mais sincero”, etc.
“Você pode descrever um personagem—como um camponês sarcástico da Idade Média—e o modelo criará instantaneamente aquela voz, ajustando emoções como raiva, tristeza ou felicidade com base em suas instruções,” acrescentou Cowen. “A modulação da voz funciona a nível de frase, mas você também pode ajustar partes de uma frase, instruindo o modelo a transmitir emoções sutis como uma leve frustração misturada com humor ou exasperação.”
O modelo também considera o contexto além de frases individuais. “Diferente dos modelos tradicionais que processam texto palavra por palavra, nosso modelo considera parágrafos inteiros, capturando o contexto para fornecer uma fala mais natural e emocionalmente precisa,” explicou.
Embora o lançamento atual se concentre em fala em inglês, o Octave também suporta espanhol e espera-se que expanda suas capacidades linguísticas em breve.
Personalizado para criação de conteúdo
O Octave é personalizado para criadores de conteúdo e produção de mídia, oferecendo aplicações em audiolivros, podcasts, personagens de videogame e dublagens de vídeos.
“Esse novo modelo é desenhado para texto-para-fala offline—perfeito para audiolivros, podcasts, dublagens de vídeos e personagens de videogame—onde os criadores precisam de vozes realistas e específicas para personagens,” explicou Cowen.
No entanto, o usuário deve acessá-lo através do site da Hume, seja em sua página de Projetos ou através de uma interface de programação de aplicativos (API). O componente “offline” refere-se ao fato de que este modelo é projetado para produzir arquivos de áudio discretos que podem ser adicionados a projetos como vídeos ou audiolivros. Não foi feito para manter conversas em tempo real, embora isso pudesse teoricamente ser permitido ao enviar consultas de texto para o site.
A API da Hume permite que desenvolvedores façam até 50 solicitações do novo modelo Octave por minuto, com um comprimento máximo de texto de 5.000 caracteres e descrições limitadas a 1.000 caracteres. Cada requisição pode gerar até cinco saídas e os formatos de áudio suportados incluem MP3, WAV e PCM.
A série de modelos EVI anterior da Hume permite interações em tempo real, e continuará a estar disponível e a ser desenvolvida.
A Hume AI oferece um modelo de preços baseado em assinatura com níveis variando de uma opção gratuita a planos Creator, Creator Pro e Enterprise.
Aqui está um resumo conciso das ofertas:
- Gratuito ($0/mês) – 10.000 caracteres de texto-para-fala por mês (~10 minutos) com vozes personalizadas ilimitadas.
- Starter ($3/mês) – 30.000 caracteres (~30 minutos) além de suporte para até 20 projetos.
- Creator ($10/mês) – 100.000 caracteres (~100 minutos), preços baseados no uso para caracteres extras ($0,20/1.000), e suporte para até 1.000 projetos.
- Pro ($50/mês) – 500.000 caracteres (~500 minutos), preços de uso menores ($0,15/1.000), e suporte para até 3.000 projetos.
- Scale ($150/mês) – 2.000.000 caracteres (~2.000 minutos), preços de uso ainda mais reduzidos ($0,13/1.000), e suporte para até 10.000 projetos.
- Business ($900/mês) – 10.000.000 caracteres (~10.000 minutos), preços de uso ainda mais baixos ($0,10/1.000), e suporte para até 20.000 projetos.
- Enterprise (Preço personalizado) – Uso ilimitado, termos legais personalizados, garantias de segurança, preços em fornecedores significativamente descontados e suporte prioritário.
No total, a Hume enfatizou que seus preços do TTS Octave estão cerca de metade do custo de rivalizar com a startup de criação de voz AI ElevenLabs, mostrando a intensificação da competição no espaço de texto-para-fala.
Além disso, a Hume AI conduziu um estudo comparativo cego com 180 avaliadores humanos para comparar o Octave com o ElevenLabs. Os resultados mostraram que o Octave foi preferido em termos de qualidade de áudio (71,6% dos testes), naturalidade (51,7% dos testes) e quão bem a fala correspondia às descrições da voz desejada (57,7% dos testes), em 120 prompts diversos.
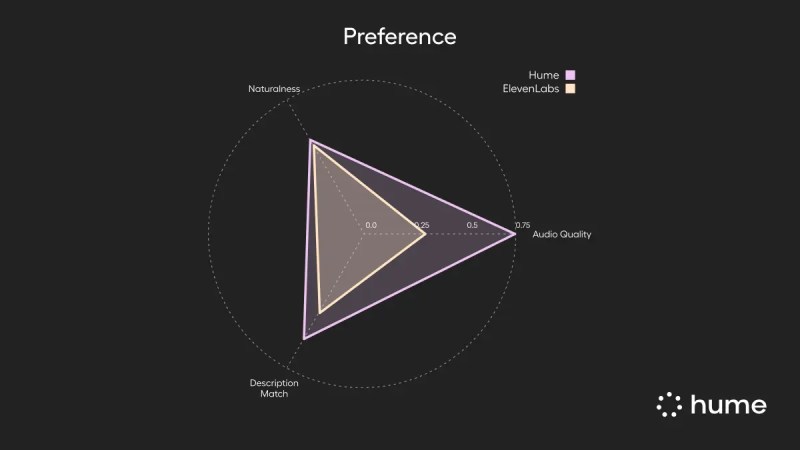
Para avaliar ainda mais seu desempenho, a Hume AI também lançou a Arena TTS Expressiva, um benchmark público projetado para testar como os modelos de IA lidam com fala mais longa e expressiva—uma área que benchmarks anteriores de TTS negligenciaram em grande parte.
Trilhões de tokens de linguagem
Diferente dos sistemas tradicionais de texto-para-fala que dependem de conjuntos de dados de fala limitados, o TTS Octave é baseado em um LLM treinado com trilhões de tokens de linguagem.
“Modelos tradicionais de texto-para-fala são treinados com dados de fala limitados, mas o nosso é baseado em um LLM treinado com dezenas de trilhões de tokens, permitindo que ele raciocine, pense e infira emoções do texto,” disse Cowen.
O modelo foi treinado usando milhões de horas de dados de fala longos e públicos e conjuntos de dados proprietários da Hume AI de novas vozes gravadas por participantes de pesquisa.
“Coletamos dados de pessoas gravando a si mesmas através de webcams, reagindo naturalmente a vídeos, contando histórias e conversando com outros, incluindo amigos e familiares, para capturar uma ampla gama de expressões emocionais,” disse Cowen.
Esse extenso treinamento permite que o modelo infira o contexto emocional e siga instruções detalhadas, criando vozes que correspondem a descrições específicas de personagens e atributos.
Vozes de personagens consistentes e limitações
O TTS Octave mantém vozes de personagens consistentes em conteúdo longo.
“Com nossa plataforma, você pode gerar vozes únicas para cada personagem em um audiolivro—como um orc de meia-idade—e manter a voz desse personagem ao longo da história,” disse Cowen.
Essa capacidade é suportada pela página de “Projetos” da Hume, que lida com conteúdo longo, como audiolivros, fragmentando automaticamente o texto enquanto preserva a consistência e o contexto do personagem atravessando os capítulos.
A Hume tem restrições técnicas embutidas em seu site e API que proíbem a criação de vozes realistas de crianças e imitações de indivíduos específicos, mas além disso, está aberta ao uso em uma ampla gama de conteúdos e temas, incluindo cenas potencialmente inapropriadas para o trabalho, como aquelas em romances populares.
“Damos liberdade aos desenvolvedores, permitindo conteúdo em uma ampla gama de experiências humanas, embora restrinjamos a criação de vozes realistas de crianças e imitações de pessoas específicas,” explicou Cowen.
Além disso, Cowen disse que a empresa poderia ajustar essas restrições para clientes específicos, como um editor de livros infantis que busca criar vozes para audiolivros infantis.
A Hume AI está trabalhando em um recurso futuro de Clonagem de Voz, que permitirá aos usuários replicar uma voz com apenas cinco segundos de áudio. A empresa está desenvolvendo salvaguardas para garantir o uso ético antes de lançar o recurso publicamente.
Com sua combinação de consciência contextual, expressão emocional e personalização de personagens, o TTS Octave busca fornecer aos criadores de conteúdo mais controle e flexibilidade, entregando vozes que soam realistas e emocionalmente envolventes.


Conteúdo relacionado

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…

Tudo o que você precisa saber sobre o chatbot de IA
[the_ad id="145565"] O ChatGPT, o chatbot de IA geradora de texto da OpenAI, conquistou o mundo desde seu lançamento em novembro de 2022. O que começou como uma ferramenta para…