


Um artigo recente da LG AI Research sugere que datasets supostamente ‘abertos’ utilizados para treinar modelos de IA podem estar oferecendo uma falsa sensação de segurança – constatando que quase quatro em cada cinco datasets de IA rotulados como ‘comercialmente utilizáveis’ na verdade contêm riscos legais ocultos.
Esses riscos variam desde a inclusão de materiais protegidos por direitos autorais não divulgados até termos de licenciamento restritivos enterrados nas dependências de um dataset. Se as descobertas do artigo forem precisas, as empresas que dependem de datasets públicos podem precisar reconsiderar seus atuais pipelines de IA, ou arriscar exposição legal no futuro.
Os pesquisadores propõem uma solução radical e potencialmente controversa: agentes de conformidade baseados em IA capazes de escanear e auditar históricos de datasets mais rápido e mais precisamente do que advogados humanos.
O artigo afirma:
‘Este artigo defende que o risco legal de datasets de treinamento de IA não pode ser determinado apenas pela revisão de termos de licença superficiais; uma análise completa, de ponta a ponta, da redistribuição de datasets é essencial para garantir a conformidade.
‘Como tal análise está além das capacidades humanas devido à sua complexidade e escala, agentes de IA podem preencher essa lacuna realizando-a com maior rapidez e precisão. Sem automação, riscos legais críticos permanecem em grande parte não examinados, colocando em risco o desenvolvimento ético de IA e a conformidade regulatória.
‘Instamos a comunidade de pesquisa em IA a reconhecer a análise legal de ponta a ponta como um requisito fundamental e a adotar abordagens impulsionadas por IA como o caminho viável para a conformidade escalável de datasets.’
Examinando 2.852 datasets populares que pareciam comercialmente utilizáveis com base em suas licenças individuais, o sistema automatizado dos pesquisadores descobriu que apenas 605 (cerca de 21%) eram realmente seguros legalmente para comercialização uma vez que todos os seus componentes e dependências fossem rastreados.
O novo artigo é intitulado Não Confie nas Licenças que Você Vê — A Conformidade de Datasets Exige Rastreamento de Ciclo de Vida em Escala Massiva Potencializado por IA, e vem de oito pesquisadores da LG AI Research.
Direitos e Injustiças
Os autores destacam os desafios enfrentados por empresas que avançam com o desenvolvimento de IA em um cenário legal cada vez mais incerto – à medida que a antiga mentalidade acadêmica de ‘uso justo’ em torno do treinamento de datasets cede lugar a um ambiente fragmentado onde as proteções legais são obscuras e a segurança não é mais garantida.
Como uma publicação apontou recentemente, as empresas estão se tornando cada vez mais defensivas sobre as fontes de seus dados de treinamento. O autor Adam Buick comenta*:
‘[Enquanto] a OpenAI divulgou as principais fontes de dados para o GPT-3, o artigo que apresenta o GPT-4 revelou apenas que os dados em que o modelo foi treinado eram uma mistura de ‘dados disponíveis publicamente (como dados da internet) e dados licenciados de provedores de terceiros’.
‘As motivações por trás dessa mudança para falta de transparência não foram articuladas em nenhum detalhe específico pelos desenvolvedores de IA, que em muitos casos não deram nenhuma explicação.
‘Por sua parte, a OpenAI justificou sua decisão de não divulgar mais detalhes sobre o GPT-4 com base em preocupações sobre ‘o cenário competitivo e as implicações de segurança de modelos em larga escala’, sem mais explicações dentro do relatório.’
A transparência pode ser um termo enganoso – ou simplesmente um mal-entendido; por exemplo, o modelo generativo Firefly da Adobe, treinado com dados de stock que a Adobe tinha os direitos de explorar, supostamente oferecia garantia aos clientes sobre a legalidade de seu uso do sistema. Mais tarde, algumas evidências surgiram de que o conjunto de dados do Firefly havia se tornado ‘enriquecido’ com dados potencialmente protegidos por direitos autorais de outras plataformas.
Como discutimos anteriormente esta semana, há iniciativas crescentes projetadas para assegurar a conformidade de licenças em datasets, incluindo uma que só irá coletar vídeos do YouTube com licenças Creative Commons flexíveis.
O problema é que as licenças em si podem ser errôneas ou concedidas por engano, como parece indicar a nova pesquisa.
Examinando Datasets de Código Aberto
É difícil desenvolver um sistema de avaliação como o Nexus quando o contexto está constantemente mudando. Portanto, o artigo declara que o sistema de conformidade de dados NEXUS é baseado em ‘vários precedentes e fundamentos legais neste momento’.
O NEXUS utiliza um agente impulsionado por IA chamado AutoCompliance para conformidade de dados automatizada. O AutoCompliance é composto por três módulos principais: um módulo de navegação para exploração na web; um módulo de perguntas e respostas (QA) para extração de informações; e um módulo de pontuação para avaliação de risco legal.
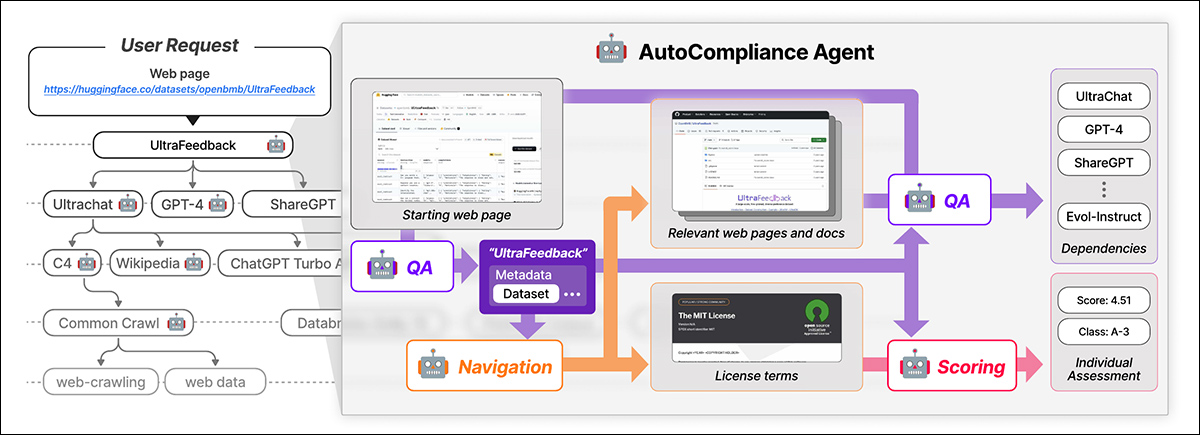
O AutoCompliance começa com uma página da web fornecida pelo usuário. A IA extrai detalhes-chave, procura por recursos relacionados, identifica termos de licença e dependências e atribui uma pontuação de risco legal. Fonte: https://arxiv.org/pdf/2503.02784
Esses módulos são alimentados por modelos de IA afinados, incluindo o modelo EXAONE-3.5-32B-Instruct, treinado em dados sintéticos e rotulados por humanos. O AutoCompliance também utiliza um banco de dados para armazenamento em cache de resultados para aumentar a eficiência.
O AutoCompliance começa com uma URL de dataset fornecida pelo usuário e a trata como a entidade raiz, procurando seus termos de licença e dependências, e rastreando recursivamente datasets vinculados para construir um gráfico de dependência de licença. Uma vez que todas as conexões são mapeadas, ele calcula pontuações de conformidade e classifica os riscos.
O framework de conformidade de dados delineado no novo trabalho identifica vários† tipos de entidades envolvidas no ciclo de vida dos dados, incluindo datasets, que formam a entrada principal para o treinamento de IA; softwares de processamento de dados e modelos de IA, que são usados para transformar e utilizar os dados; e Provedores de Serviços de Plataforma, que facilitam o manuseio dos dados.
O sistema avalia holisticamente os riscos legais considerando essas várias entidades e suas interdependências, indo além da avaliação mecânica das licenças dos datasets para incluir um ecossistema mais amplo dos componentes envolvidos no desenvolvimento de IA.
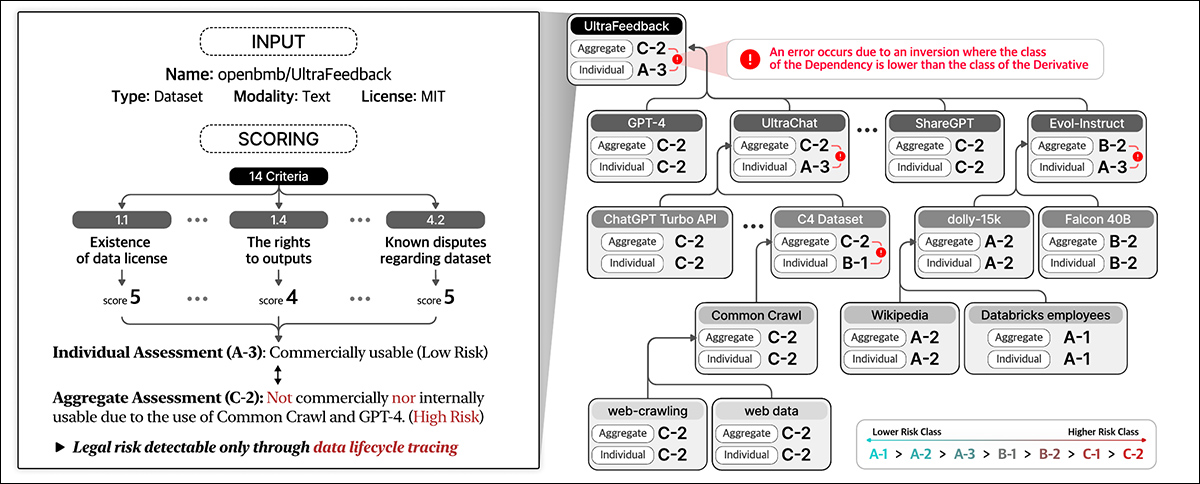
A Conformidade de Dados avalia o risco legal ao longo de todo o ciclo de vida dos dados. Atribui pontuações com base em detalhes do dataset e em 14 critérios, classificando entidades individuais e agregando risco através de dependências.
Treinamento e Métricas
Os autores extraíram os URLs dos 1.000 datasets mais baixados no Hugging Face, subamostrando aleatoriamente 216 itens para constituir um conjunto de teste.
O modelo EXAONE foi afinado no conjunto de dados personalizado dos autores, com o módulo de navegação e o módulo de perguntas e respostas usando dados sintéticos, e o módulo de pontuação usando dados rotulados por humanos.
Rótulos de verdade foram criados por cinco especialistas jurídicos treinados por pelo menos 31 horas em tarefas semelhantes. Esses especialistas humanos identificaram manualmente dependências e termos de licença para 216 casos de teste, depois agregaram e refinaram suas descobertas em discussão.
Com o sistema AutoCompliance, calibrado por humanos, testado contra o ChatGPT-4o e o Perplexity Pro, notavelmente mais dependências foram descobertas dentro dos termos de licença:
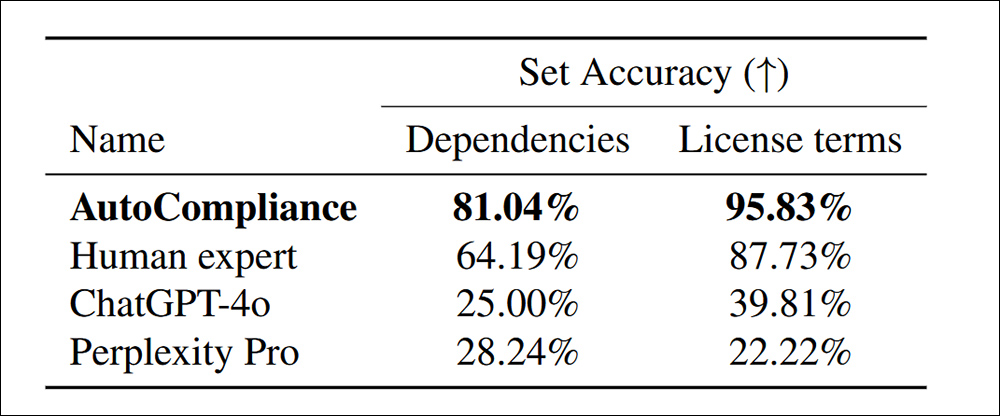
Precisão na identificação de dependências e termos de licença para 216 datasets de avaliação.
O artigo afirma:
‘O AutoCompliance supera significativamente todos os outros agentes e especialistas humanos, alcançando uma precisão de 81,04% e 95,83% em cada tarefa. Em contraste, tanto o ChatGPT-4o quanto o Perplexity Pro apresentam precisão relativamente baixa para tarefas de Fonte e Licença, respectivamente.
‘Esses resultados destacam o desempenho superior do AutoCompliance, demonstrando sua eficácia em lidar com ambas as tarefas com notável precisão, ao mesmo tempo em que indicam um substancial gap de desempenho entre modelos baseados em IA e especialistas humanos nessas áreas.’
Em termos de eficiência, a abordagem AutoCompliance levou apenas 53,1 segundos para execução, em contraste com 2.418 segundos para a avaliação humana equivalente nas mesmas tarefas.
Além disso, a execução da avaliação custou $0,29 USD, comparado a $207 USD para os especialistas humanos. Deve-se notar, no entanto, que isso se baseia na locação de um nó GCP a2-megagpu-16gpu mensalmente a uma taxa de $14.225 por mês – significando que esse tipo de eficiência de custo está relacionado principalmente a uma operação em larga escala.
Investigação de Datasets
Para a análise, os pesquisadores selecionaram 3.612 datasets combinando os 3.000 datasets mais baixados do Hugging Face com 612 datasets da Iniciativa de Proveniência de Dados de 2023.
O artigo afirma:
‘Começando a partir das 3.612 entidades alvo, identificamos um total de 17.429 entidades únicas, onde 13.817 entidades apareceram como dependências diretas ou indiretas das entidades alvo.
‘Para nossa análise empírica, consideramos que uma entidade e seu gráfico de dependência de licença possuem uma estrutura de camada única se a entidade não tiver nenhuma dependência e uma estrutura de múltiplas camadas se tiver uma ou mais dependências.
‘Dos 3.612 datasets alvo, 2.086 (57,8%) tinham estruturas de múltiplas camadas, enquanto os outros 1.526 (42,2%) tinham estruturas de camada única sem dependências.’
Datasets protegidos por direitos autorais só podem ser redistribuídos com autoridade legal, que pode vir de uma licença, exceções à lei sobre direitos autorais ou termos contratuais. Redistribuição não autorizada pode levar a consequências legais, incluindo infração de direitos autorais ou violações contratuais. Portanto, a identificação clara de não-conformidade é essencial.
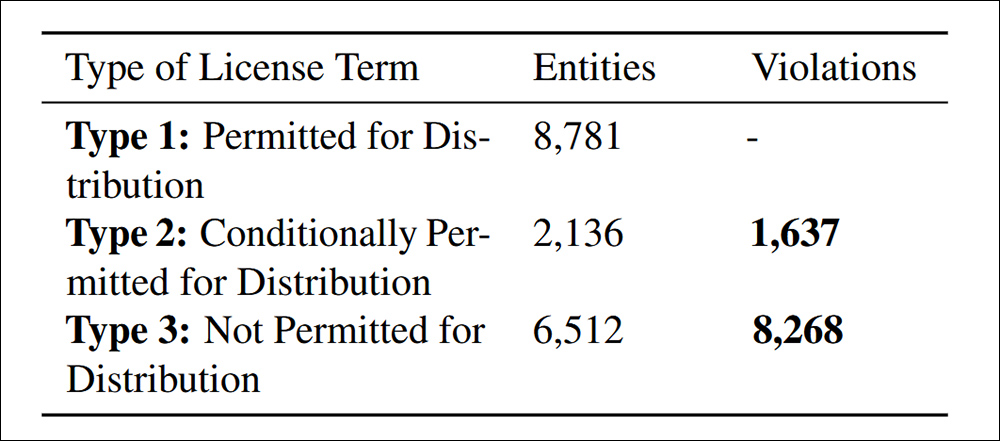
Violações de distribuição encontradas sob o Criterion 4.4. de Conformidade de Dados citado no artigo.
O estudo encontrou 9.905 casos de redistribuição de dataset não conformes, divididos em duas categorias: 83,5% foram explicitamente proibidos sob termos de licença, tornando a redistribuição uma violação legal clara; e 16,5% envolveram datasets com condições de licença conflitantes, onde a redistribuição era permitida em teoria, mas que não atendiam aos termos exigidos, criando risco legal a jusante.
Os autores admitem que os critérios de risco propostos no NEXUS não são universais e podem variar de acordo com a jurisdição e a aplicação de IA, e que futuras melhorias devem se concentrar em se adaptar às regulamentações globais em mudança enquanto refinam a revisão legal impulsionada por IA.
Conclusão
Este é um artigo prolixo e em grande parte hostil, mas aborda talvez o maior fator que retarda a adoção da IA pela indústria atualmente – a possibilidade de que dados aparentemente ‘abertos’ sejam posteriormente reivindicados por diversas entidades, indivíduos e organizações.
Sob o DMCA, violações podem legalmente implicar multas massivas em uma base de por caso. Onde as violações podem alcançar milhões, como nos casos descobertos pelos pesquisadores, a responsabilidade legal potencial é verdadeiramente significativa.
Além disso, empresas que podem ser comprovadamente beneficiadas por dados upstream não podem (como de costume) alegar ignorância como desculpa, pelo menos no influente mercado dos EUA. Nem elas têm atualmente ferramentas realistas com as quais penetrar nas complexas implicações enterradas nos acordos de licenciamento de datasets supostamente de código aberto.
O problema na formulação de um sistema como o NEXUS é que seria desafiador o suficiente calibrá-lo por estado nos EUA, ou por nação na UE; a perspectiva de criar uma estrutura realmente global (uma espécie de ‘Interpol para a proveniência de datasets’) é minada não apenas pelos motivos conflitantes dos diferentes governos envolvidos, mas também pelo fato de que tanto esses governos quanto o estado de suas atuais leis neste aspecto estão mudando constantemente.
* Minha substituição de hyperlinks pelas citações dos autores.
† Seis tipos são prescritos no artigo, mas os dois últimos não são definidos.
Publicado pela primeira vez na sexta-feira, 7 de março de 2025

Conteúdo relacionado

Google testa substituir ‘Estou Sentindo Sorte’ por ‘Modo AI’
[the_ad id="145565"] O Google está testando um redesign em sua página inicial de Pesquisa, no qual o “Modo AI”, o recurso experimental de busca alimentado por IA que a empresa…

Agentes Guardian: Nova abordagem pode reduzir alucinações em IA para abaixo de 1%
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba mais…

Participe das Sessões TechCrunch: IA com este novo desconto por tempo limitado!
[the_ad id="145565"] Estamos animados em anunciar uma grande surpresa para a comunidade de IA — o TechCrunch Sessions: AI está oferecendo um desconto por tempo limitado para…