


Participe de nossos boletins diários e semanais para receber as atualizações mais recentes e conteúdo exclusivo sobre a cobertura de IA líder do setor. Saiba mais
As empresas estão cada vez mais dependentes de grandes modelos de linguagem (LLMs) para fornecer serviços avançados, mas enfrentam dificuldades para lidar com os custos computacionais de operação desses modelos. Um novo framework, chain-of-experts (CoE), tem como objetivo tornar os LLMs mais eficientes em termos de recursos, ao mesmo tempo em que aumenta sua precisão em tarefas de raciocínio.
O framework CoE aborda as limitações de abordagens anteriores ativando “especialistas” — elementos separados de um modelo, cada um especializado em certas tarefas — sequencialmente em vez de em paralelo. Essa estrutura permite que os especialistas se comuniquem sobre resultados intermediários e construam gradualmente sobre o trabalho uns dos outros.
Arquiteturas como o CoE podem se tornar muito úteis em aplicações intensivas em inferência, onde ganhos em eficiência podem resultar em enormes economias de custo e melhor experiência do usuário.
LLMs densos e mistura de especialistas
LLMs clássicos, às vezes referidos como modelos densos, ativam todos os parâmetros simultaneamente durante a inferência, levando a grandes demandas computacionais à medida que o modelo cresce. A mistura de especialistas (MoE), uma arquitetura usada em modelos como DeepSeek-V3 e (presumivelmente) GPT-4o, aborda esse desafio dividindo o modelo em um conjunto de especialistas.
Durante a inferência, os modelos MoE utilizam um roteador que seleciona um subconjunto de especialistas para cada entrada. Os MoEs reduzem significativamente a sobrecarga computacional de execução de LLMs em comparação com modelos densos. Por exemplo, o DeepSeek-V3 é um modelo de 671 bilhões de parâmetros com 257 especialistas, dos quais nove são usados para qualquer token de entrada, totalizando 37 bilhões de parâmetros ativos durante a inferência.
No entanto, os MoEs têm limitações. As duas principais desvantagens são, primeiro, que cada especialista opera de maneira independente dos outros, reduzindo o desempenho do modelo em tarefas que requerem consciência contextual e coordenação entre especialistas. E, em segundo lugar, a arquitetura MoE causa alta escassez, resultando em um modelo com altas exigências de memória, mesmo que um pequeno subconjunto seja utilizado a qualquer momento.
Chain-of-experts
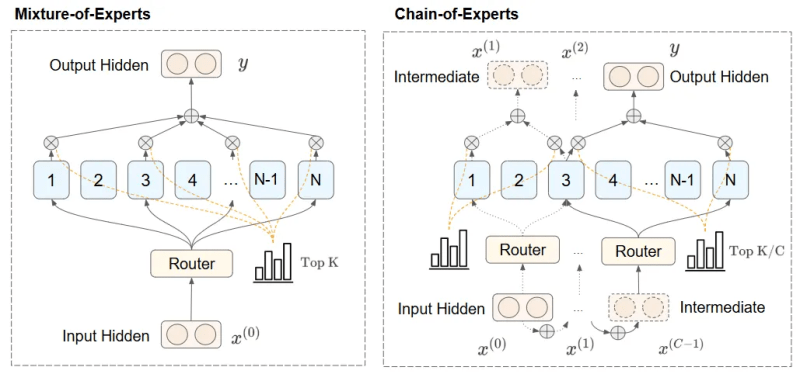
O framework chain-of-experts aborda as limitações dos MoEs ativando especialistas sequencialmente em vez de em paralelo. Essa estrutura permite que os especialistas comuniquem resultados intermediários e construam gradualmente sobre o trabalho uns dos outros.
O CoE utiliza um processo iterativo. A entrada é primeiro direcionada a um conjunto de especialistas, que a processam e transmitem suas respostas para outro conjunto de especialistas. O segundo grupo de especialistas processa os resultados intermediários e pode passar para o próximo conjunto de especialistas. Essa abordagem sequencial fornece entradas conscientes do contexto, melhorando significativamente a capacidade do modelo de lidar com tarefas de raciocínio complexas.
Por exemplo, em raciocínio matemático ou inferência lógica, o CoE permite que cada especialista construa a partir de insights anteriores, melhorando a precisão e o desempenho nas tarefas. Este método também otimiza o uso de recursos ao minimizar os cálculos redundantes comuns em implantações de especialistas apenas em paralelo, atendendo à demanda das empresas por soluções de IA de alto desempenho e com custo eficiente.
Principais vantagens do CoE
A abordagem chain-of-experts, utilizando a ativação sequencial e a colaboração entre especialistas, resulta em várias vantagens principais, conforme descrito em uma recente análise de um grupo de pesquisadores testando o framework CoE.
No CoE, a seleção de especialistas é realizada de forma iterativa. Em cada iteração, os especialistas são determinados pela saída da etapa anterior. Isso permite que diferentes especialistas se comuniquem e formem interdependências para criar um mecanismo de roteamento mais dinâmico.
“Dessa forma, o CoE pode melhorar significativamente o desempenho do modelo enquanto mantém a eficiência computacional, especialmente em cenários complexos (por exemplo, a tarefa de Matemática em experimentos),” escrevem os pesquisadores.
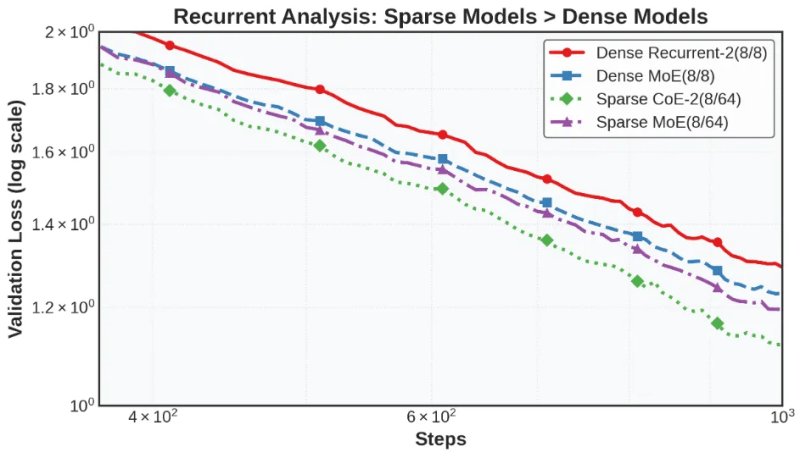
Os experimentos dos pesquisadores mostram que, com orçamentos computacionais e de memória iguais, o CoE supera os LLMs densos e os MoEs. Por exemplo, em benchmarks matemáticos, um CoE com 64 especialistas, quatro especialistas roteados e duas iterações de inferência (CoE-2(4/64)) supera um MoE com 64 especialistas e oito especialistas roteados (MoE(8/64)).
Os pesquisadores também descobriram que o CoE reduz as exigências de memória. Por exemplo, um CoE com dois dos 48 especialistas roteados e duas iterações (CoE-2(4/48)) alcança um desempenho semelhante ao MoE(8/64) enquanto usa menos especialistas totais, reduzindo as exigências de memória em 17,6%.
O CoE também permite arquiteturas de modelo mais eficientes. Por exemplo, um CoE-2(8/64) com quatro camadas de redes neurais tem desempenho equivalente ao de um MoE(8/64) com oito camadas, mas usando 42% menos memória.
“Talvez o mais significativo, o CoE parece fornecer o que chamamos de uma aceleração de ‘almoço grátis’,” escrevem os pesquisadores. “Ao reestruturar como a informação flui através do modelo, conseguimos melhores resultados com a mesma sobrecarga computacional em comparação com os métodos anteriores de MoE.”
Um exemplo: Um CoE-2(4/64) oferece 823 combinações de especialistas a mais em comparação com o MoE(8/64), permitindo que o modelo aprenda tarefas mais complexas sem aumentar o tamanho do modelo ou suas exigências de memória e computação.
Os menores custos operacionais e o desempenho aprimorado em tarefas complexas do CoE podem tornar a IA avançada mais acessível às empresas, ajudando-as a permanecer competitivas sem investimentos substanciais em infraestrutura.
“Esta pesquisa abre novos caminhos para escalar eficientemente modelos de linguagem, potencialmente tornando as capacidades avançadas de inteligência artificial mais acessíveis e sustentáveis,” escrevem os pesquisadores.


Conteúdo relacionado

Além do A2A e MCP: Como a Camada de Identidade Universal do Agente LOKA transforma o jogo.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de AI líder no setor. Saiba mais…

Yelp lança agentes de voz com IA para restaurantes e prestadores de serviços.
[the_ad id="145565"] O Yelp anunciou na terça-feira que está trabalhando na implementação de “agentes de voz” impulsionados por IA para ajudar prestadores de serviços e…

Aqui está como assistir ao LlamaCon, o primeiro evento de desenvolvedores de IA da Meta.
[the_ad id="145565"] Na terça-feira, a Meta realizará a LlamaCon, seu primeiro evento de desenvolvedores de IA. O foco será na família de modelos de IA Llama da empresa, e…