


O setor de pesquisa em síntese de vídeo/imagem tem produzido regularmente arquiteturas de edição de vídeo*, e nos últimos nove meses, as saídas desse tipo se tornaram ainda mais frequentes. No entanto, a maioria delas representa apenas avanços incrementais sobre o estado da arte, uma vez que os desafios centrais são substanciais.
No entanto, uma nova colaboração entre China e Japão nesta semana produziu alguns exemplos que merecem uma análise mais aprofundada, mesmo que não seja necessariamente uma obra marcante.
No clipe de vídeo abaixo (do site do projeto associado ao artigo, que – fique avisado – pode sobrecarregar seu navegador), vemos que, embora as capacidades de deepfake do sistema sejam inexistentes na configuração atual, o sistema realiza um bom trabalho ao alterar plausivelmente e significativamente a identidade da jovem na imagem, com base em uma máscara de vídeo (canto inferior esquerdo):
Clique para reproduzir. Com base na máscara de segmentação semântica visualizada no canto inferior esquerdo, a mulher original (canto superior esquerdo) é transformada em uma identidade notavelmente diferente, mesmo que esse processo não atinja a troca de identidade indicada no prompt. Fonte: https://yxbian23.github.io/project/video-painter/ (esteja ciente de que, no momento da escrita, este site que reproduz vídeos automaticamente estava propenso a travar meu navegador). Consulte os vídeos de origem, se conseguir acessá-los, para melhor resolução e detalhes, ou confira os exemplos no vídeo de visão geral do projeto em https://www.youtube.com/watch?v=HYzNfsD3A0s
A edição baseada em máscara desse tipo é bem estabelecida em modelos de difusão latente estática, utilizando ferramentas como ControlNet. No entanto, manter a consistência do fundo em vídeo é muito mais desafiador, mesmo quando as áreas mascaradas proporcionam flexibilidade criativa ao modelo, como mostrado abaixo:
Clique para reproduzir. Uma mudança de espécie, com o novo método VideoPainter. Consulte os vídeos de origem, se puder acessá-los, para melhor resolução e detalhes, ou confira os exemplos no vídeo de visão geral do projeto em https://www.youtube.com/watch?v=HYzNfsD3A0s
Os autores do novo trabalho consideram seu método em relação à arquitetura BrushNet da Tencent (que cobrimos no ano passado) e ao ControlNet, ambas tratando de uma arquitetura de dupla ramificação capaz de isolar a geração de primeiro plano e de fundo.
No entanto, aplicar este método diretamente à abordagem bastante produtiva dos Difusores Transformers (DiT) proposta pela Sora da OpenAI, traz desafios particulares, como observam os autores:
‘[Aplicar diretamente a arquitetura do BrushNet e do ControlNet] aos DiTs de vídeo apresenta vários desafios: [Primeiramente, dado que] a robusta fundação generativa e o tamanho pesado do Video DiT tornam desnecessário e computacionalmente dispendioso replicar todo o arcabouço de Video DiT como o codificador de contexto.
‘[Em segundo lugar, ao contrário] do puro ramo de controle convolucional do BrushNet, os tokens de DiT em regiões mascaradas contêm inherentemente informações de fundo devido à atenção global, complicando a distinção entre regiões mascaradas e não mascaradas nos backbones do DiT.
‘[Finalmente,] o ControlNet carece de injeção de características em todas as camadas, dificultando o controle denso de fundo para tarefas de inpainting.’
Portanto, os pesquisadores desenvolveram uma abordagem plug-and-play na forma de uma estrutura de dupla ramificação intitulada VideoPainter.
O VideoPainter oferece uma estrutura de inpainting de vídeo de dupla ramificação que melhora os DiTs pré-treinados com um codificador de contexto leve. Este codificador representa apenas 6% dos parâmetros do backbone, que os autores afirmam tornar a abordagem mais eficiente do que métodos convencionais.
O modelo propõe três inovações principais: um encoder de contexto de duas camadas simplificado para orientação de fundo eficiente; um sistema de integração de características seletivas por máscara que separa tokens mascarados e não mascarados; e uma técnica de remuestreamento de ID da região de inpainting que mantém a consistência da identidade em sequências de vídeo longas.
Ao congelar tanto o DiT pré-treinado quanto o codificador de contexto enquanto introduz um ID-Adapter, o VideoPainter garante que os tokens da região de inpainting de clipes anteriores persistam ao longo de um vídeo, reduzindo o tremor e as inconsistências.
A estrutura também é projetada para compatibilidade plug-and-play, permitindo que os usuários a integrem suavemente em fluxos de trabalho existentes de geração e edição de vídeo.
Para apoiar o trabalho, que utiliza CogVideo-5B-I2V como seu motor gerativo, os autores curtiram o que afirmam ser o maior conjunto de dados de inpainting de vídeo até hoje. Intitulado VPData, a coleção consiste em mais de 390.000 clipes, totalizando uma duração de vídeo de mais de 886 horas. Eles também desenvolveram uma estrutura de benchmark relacionada intitulada VPBench.
Clique para reproduzir. Nos exemplos do site do projeto, vemos as capacidades de segmentação impulsionadas pela coleção VPData e pelo conjunto de testes VPBench. Consulte os vídeos de origem, se puder acessá-los, para melhor resolução e detalhes, ou confira os exemplos no vídeo de visão geral do projeto em https://www.youtube.com/watch?v=HYzNfsD3A0s
O novo trabalho é intitulado VideoPainter: Inpainting e Edição de Vídeo de Qualquer Duração com Controle de Contexto Plug-and-Play, e vem de sete autores do Tencent ARC Lab, da Universidade Chinesa de Hong Kong, da Universidade de Tóquio e da Universidade de Macau.
Além do mencionado site do projeto, os autores também lançaram uma visão geral no YouTube, assim como uma página no Hugging Face.
Método
O pipeline de coleta de dados para o VPData consiste em coleta, anotação, divisão, seleção e legendagem:
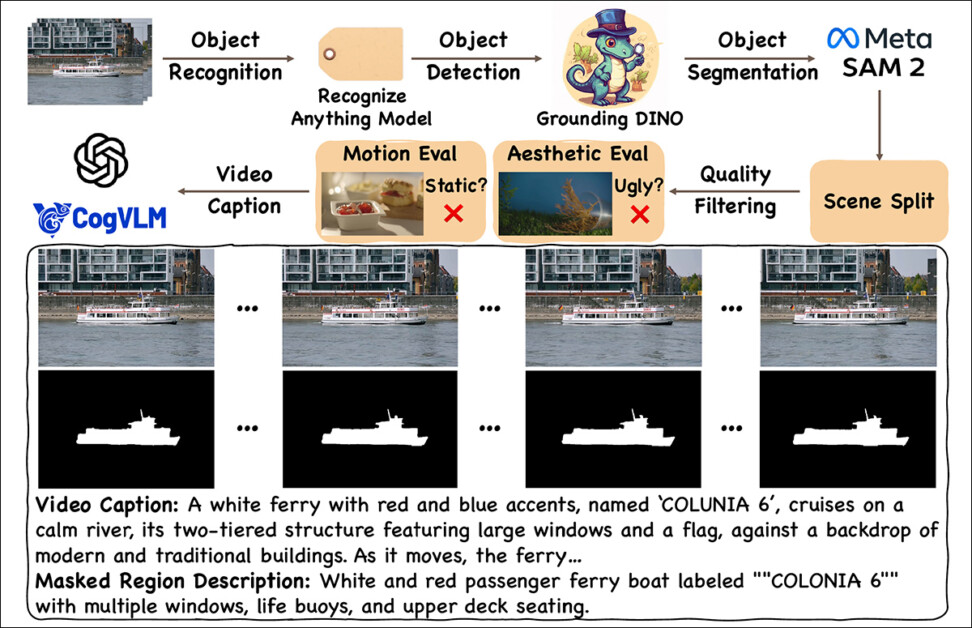
Esquema para o pipeline de construção de conjuntos de dados. Fonte: https://arxiv.org/pdf/2503.05639
As coleções de origem utilizadas para esta compilação vieram de Videvo e Pexels, com uma captura inicial de cerca de 450.000 vídeos obtidos.
Múltiplas bibliotecas e métodos contribuíram para a fase de pré-processamento: a estrutura Recognize Anything foi utilizada para fornecer marcação de vídeo em conjunto aberto, encarregada de identificar objetos principais; Grounding Dino foi usado para a detecção de caixas limitadoras em torno dos objetos identificados; e a estrutura Segment Anything Model 2 (SAM 2) foi utilizada para refinar essas seleções grosseiras em segmentações de máscara de alta qualidade.
Para gerenciar transições de cena e garantir consistência no inpainting de vídeo, o VideoPainter usa PySceneDetect para identificar e segmentar clipes em pontos de ruptura naturais, evitando as mudanças disruptivas frequentemente causadas pelo rastreamento do mesmo objeto de múltiplos ângulos. Os clipes foram divididos em intervalos de 10 segundos, com qualquer um menor que seis segundos descartado.
Para a seleção de dados, três critérios de filtragem foram aplicados: qualidade estética, avaliada com o Laion-Aesthetic Score Predictor; força de movimento, medida via fluxo óptico usando RAFT; e segurança de conteúdo, verificada através do Safety Checker do Stable Diffusion.
Uma grande limitação nos conjuntos de dados de segmentação de vídeo existentes é a ausência de anotações textuais detalhadas, que são cruciais para guiar modelos generativos:
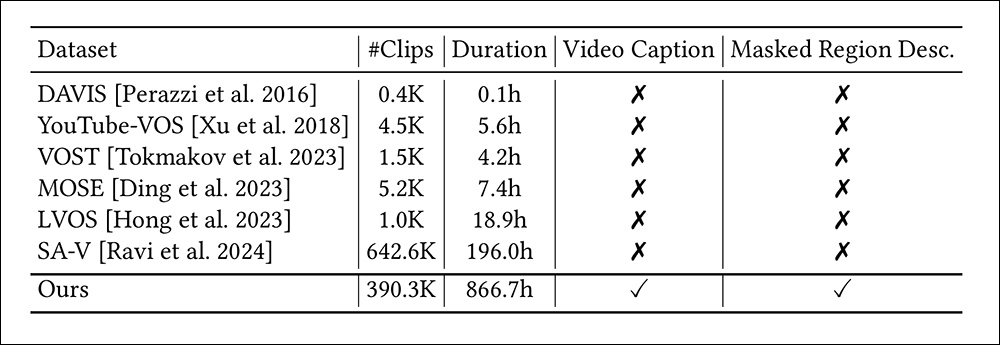
Os pesquisadores enfatizam a falta de legendas para vídeo em coleções comparáveis.
Portanto, o processo de curadoria de dados do VideoPainter incorpora diversos modelos de visão-linguagem de ponta, incluindo CogVLM2 e Chat GPT-4o para gerar legendas baseadas em quadros-chave e descrições detalhadas de regiões mascaradas.
O VideoPainter melhora os DiTs pré-treinados ao introduzir um codificador de contexto leve e personalizado que separa a extração de contexto de fundo da geração de primeiro plano, conforme visto no canto superior direito do esquema ilustrativo abaixo:
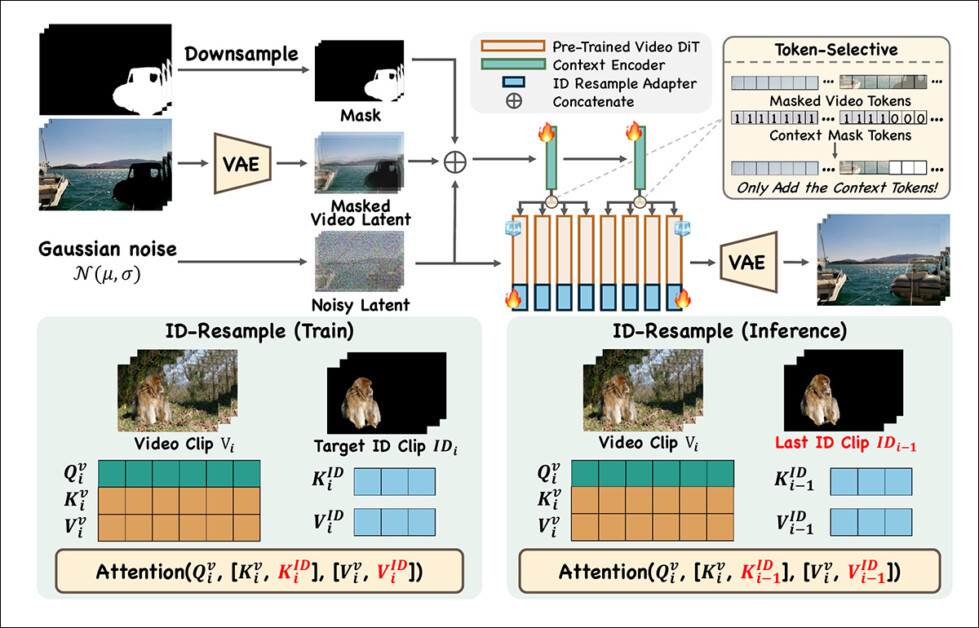
Esquema conceitual para o VideoPainter. O codificador de contexto do VideoPainter processa latentes ruidosos, máscaras redimensionadas e latentes de vídeo mascarados via VAE, integrando apenas tokens de fundo no DiT pré-treinado para evitar ambiguidade. O ID Resample Adapter garante a consistência da identidade ao concatenar tokens da região mascarada durante o treinamento e remuestreamento dos mesmos de clipes anteriores durante a inferência.
Em vez de sobrecarregar o backbone com processamento redundante, este codificador opera em uma entrada simplificada: uma combinação de latente ruidoso, latente de vídeo mascarado (extraído via autoencoder variacional, ou VAE) e máscaras redimensionadas.
O latente ruidoso fornece contexto de geração, e o latente de vídeo mascarado alinha-se com a distribuição existente do DiT, visando melhorar a compatibilidade.
Em vez de duplicar grandes seções do modelo, que os autores afirmam que ocorreu em trabalhos anteriores, o VideoPainter integra apenas as duas primeiras camadas do DiT. Essas características extraídas são reintegradas no DiT congelado de forma estruturada e em grupo – características de camadas iniciais informam a primeira metade do modelo, enquanto características posteriores refinam a segunda metade.
Além disso, um mecanismo seletivo de tokens garante que apenas características relevantes ao fundo sejam reintegradas, prevenindo confusão entre regiões mascaradas e não mascaradas. Esta abordagem, segundo os autores, permite que o VideoPainter mantenha alta fidelidade na preservação do fundo, enquanto melhora a eficiência do inpainting do primeiro plano.
Os autores observam que o método proposto suporta diversos métodos de estilização, incluindo o mais popular, Low Rank Adaptation (LoRA).
Dados e Testes
O VideoPainter foi treinado utilizando o modelo CogVideo-5B-I2V, juntamente com sua versão texto-para-vídeo. O corpus VPData curado foi usado a 480x720px, com uma taxa de aprendizado de 1×10-5.
O ID Resample Adapter foi treinado por 2.000 etapas, e o codificador de contexto por 80.000 etapas, ambos usando o otimizador AdamW. O treinamento ocorreu em duas etapas usando um total impressionante de 64 GPUs NVIDIA V100 (embora o artigo não especifique se tinham 16GB ou 32GB de VRAM).
Para benchmarking, Davis foi usado para máscaras aleatórias, e o VPBench dos autores para máscaras baseadas em segmentação.
O conjunto de dados VPBench apresenta objetos, animais, humanos, paisagens e tarefas diversas, e abrange quatro ações: adição, remoção, mudança e troca. A coleção conta com 45 vídeos de 6 segundos e nove vídeos com duração média de 30 segundos.
Oito métricas foram utilizadas para o processo. Para a Preservação da Região Mascarada, os autores utilizaram Relação Sinal-Ruído de Pico (PSNR); Métricas de Similaridade Perceptual Aprendida (LPIPS); Índice de Similaridade Estrutural (SSIM); e Erro Absoluto Médio (MAE).
Para alinhamento de texto, os pesquisadores utilizaram Similaridade CLIP tanto para avaliar a distância semântica entre a legenda do clipe e seu conteúdo percebido, quanto para avaliar a precisão das regiões mascaradas.
Para avaliar a qualidade geral dos vídeos de saída, foi utilizado Distância Fréchet de Vídeo (FVD).
Para uma comparação quantitativa de inpainting de vídeo, os autores colocaram seu sistema contra abordagens anteriores ProPainter, COCOCO e Cog-Inp (CogVideoX). O teste consistiu em inpaintar o primeiro quadro de um clipe usando modelos de inpainting de imagem, e então usar uma base de imagem-para-vídeo (I2V) para propagar os resultados em uma operação de mistura latente, de acordo com um método proposto em um artigo de 2023 de Israel.
Uma vez que o site do projeto não está totalmente funcional no momento da escrita, e o vídeo associado ao projeto pode não apresentar todos os exemplos envolvidos, é bastante difícil localizar exemplos de vídeo que sejam muito específicos para os resultados descritos no artigo. Portanto, mostraremos resultados estáticos parciais apresentados no artigo, e encerraremos o artigo com alguns exemplos adicionais que conseguimos extrair do site do projeto.
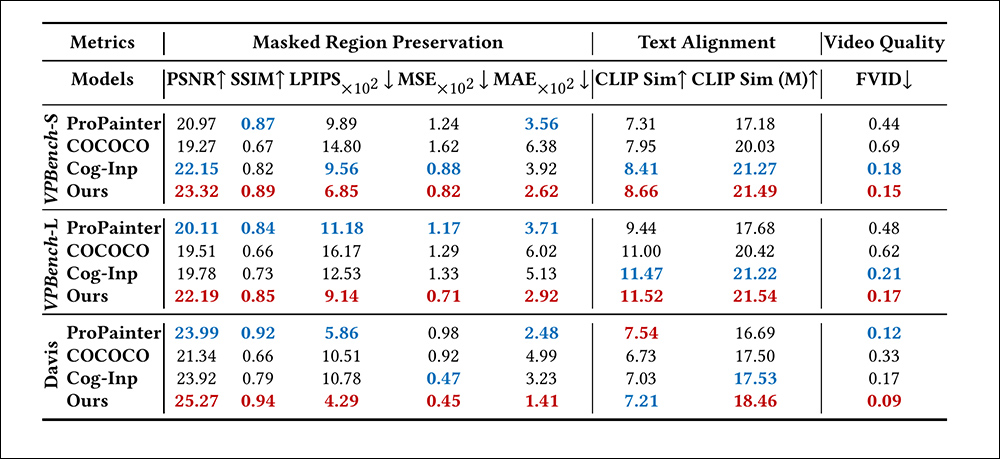
Comparação quantitativa do VideoPainter em relação ao ProPainter, COCOCO e Cog-Inp no VPBench (máscaras de segmentação) e Davis (máscaras aleatórias). As métricas abrangem preservação de região mascarada, alinhamento de texto e qualidade de vídeo. Vermelho = melhor, Azul = segundo melhor.
Desses resultados qualitativos, os autores comentam:
‘No VPBench baseado em segmentação, ProPainter e COCOCO apresentam o pior desempenho em praticamente todas as métricas, principalmente devido à incapacidade de inpaintar objetos totalmente mascarados e à dificuldade da arquitetura de estrutura única em equilibrar a preservação do fundo e a geração do primeiro plano, respectivamente.
‘No benchmark de máscara aleatória, Davis, ProPainter mostra melhoria ao alavancar informações parciais de fundo. No entanto, o VideoPainter atinge desempenho ideal em máscaras de segmentação (tanto padrão quanto longa) e máscaras aleatórias por meio de sua arquitetura de dupla ramificação que efetivamente desacopla a preservação do fundo da geração do primeiro plano.’
Os autores então apresentam exemplos estáticos de testes qualitativos, dos quais apresentamos uma seleção abaixo. Em todos os casos, referimos o leitor ao site do projeto e ao vídeo do YouTube para melhor resolução.

Uma comparação contra métodos de inpainting em estruturas anteriores.
Clique para reproduzir. Exemplos concatenados por nós a partir dos vídeos ‘resultados’ no site do projeto.
Quanto a esta rodada qualitativa para inpainting de vídeo, os autores comentam:
‘O VideoPainter consistentemente apresenta resultados excepcionais em coesão de vídeo, qualidade, e alinhamento com a legenda do prompt. Notavelmente, o ProPainter falha em gerar objetos totalmente mascarados porque depende apenas da propagação de pixels de fundo em vez de gerar.
‘Enquanto o COCOCO demonstra funcionalidade básica, ele falha em manter ID consistente em regiões inpaintadas (aparições inconsistentes de vasos e mudanças abruptas de terreno) devido à sua arquitetura de estrutura única tentando equilibrar a preservação do fundo e a geração do primeiro plano.
‘Cog-Inp atinge resultados básicos de inpainting; no entanto, a incapacidade de sua operação de mistura de detectar limites de máscara leva a artefatos significativos.
‘Além disso, o VideoPainter pode gerar vídeos coerentes com mais de um minuto enquanto mantém a consistência de ID através do nosso remuestreamento de ID.’
Os pesquisadores também testaram a capacidade do VideoPainter de aumentar legendas e obter melhores resultados por esse método, colocando o sistema contra UniEdit, DiTCtrl e ReVideo.
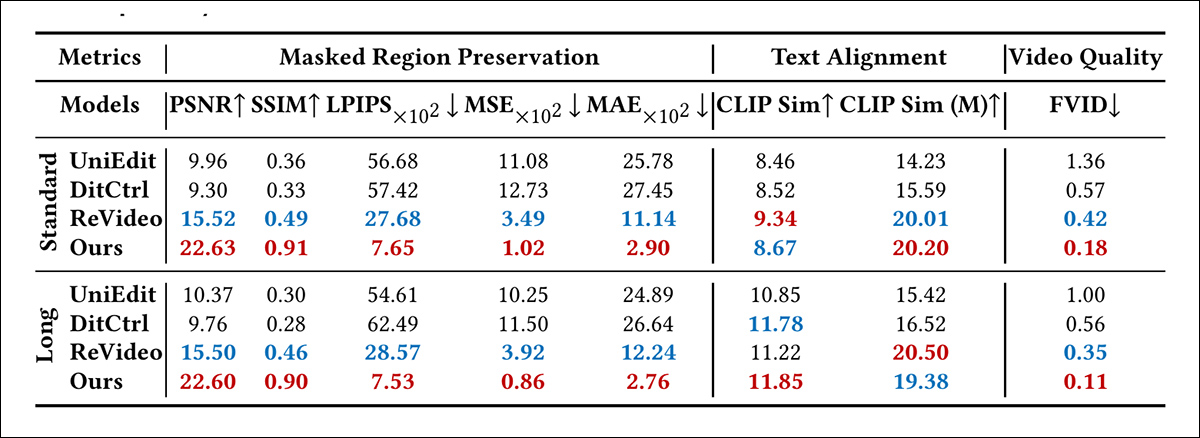
Resultados de edição de vídeo contra três abordagens anteriores.
Os autores comentam:
‘Para vídeos padrão e longos no VPBench, o VideoPainter alcança desempenho superior, mesmo superando o ReVideo de fim a fim. Esse sucesso pode ser atribuído à sua arquitetura de dupla ramificação, que garante excelente preservação do fundo e capacidades de geração do primeiro plano, mantendo alta fidelidade nas regiões não editadas enquanto garante que as regiões editadas se alinhem estreitamente com as instruções de edição, complementadas pelo remuestreamento de ID da região de inpainting que mantém a consistência de ID em vídeos longos.’
Embora o artigo apresente exemplos qualitativos estáticos para essa métrica, eles são pouco ilustrativos, e referimos o leitor em vez disso para os diversos exemplos espalhados pelos vários vídeos publicados para este projeto.
Finalmente, um estudo com humanos foi conduzido, onde trinta usuários foram solicitados a avaliar 50 gerações selecionadas aleatoriamente dos subconjuntos VPBench e de edição. Os exemplos destacaram a preservação do fundo, o alinhamento ao prompt, e a qualidade geral do vídeo.
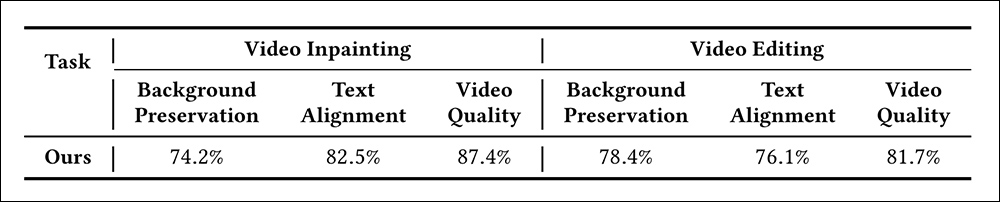
Resultados do estudo com usuários para o VideoPainter.
Os autores afirmam:
‘O VideoPainter superou significativamente as bases existentes, alcançando taxas de preferência mais altas em todos os critérios de avaliação em ambas as tarefas.’
No entanto, eles reconhecem que a qualidade das gerações do VideoPainter depende do modelo base, que pode ter dificuldades com movimentos complexos e física; e observam que também apresenta um desempenho ruim com máscaras de baixa qualidade ou legendas desalinhadas.
Conclusão
O VideoPainter parece uma adição valiosa à literatura. Típico das soluções recentes, no entanto, ele tem demandas computacionais consideráveis. Além disso, muitos dos exemplos escolhidos para apresentação no site do projeto ficam muito aquém dos melhores exemplos; portanto, seria interessante ver essa estrutura testada contra futuras entradas e uma gama mais ampla de abordagens anteriores.
* Vale mencionar que “edição de vídeo” neste sentido não significa “montar diversos clipes em uma sequência”, que é o significado tradicional deste termo; mas sim mudar diretamente ou de alguma forma modificar o conteúdo interno de clipes de vídeo existentes, utilizando técnicas de aprendizado de máquina
Publicado pela primeira vez na segunda-feira, 10 de março de 2025

Conteúdo relacionado

Além do A2A e MCP: Como a Camada de Identidade Universal do Agente LOKA transforma o jogo.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de AI líder no setor. Saiba mais…

Yelp lança agentes de voz com IA para restaurantes e prestadores de serviços.
[the_ad id="145565"] O Yelp anunciou na terça-feira que está trabalhando na implementação de “agentes de voz” impulsionados por IA para ajudar prestadores de serviços e…

Aqui está como assistir ao LlamaCon, o primeiro evento de desenvolvedores de IA da Meta.
[the_ad id="145565"] Na terça-feira, a Meta realizará a LlamaCon, seu primeiro evento de desenvolvedores de IA. O foco será na família de modelos de IA Llama da empresa, e…