


Participe de nossos boletins informativos diários e semanais para obter as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba mais
Embora modelos grandes de linguagem e raciocínio continuem populares, as organizações estão cada vez mais optando por modelos menores para executar processos de IA com menos preocupações em relação ao consumo de energia e aos custos.
Enquanto algumas organizações estão destilando modelos maiores em versões menores, provedores de modelos como Google continuam a lançar pequenos modelos de linguagem (SLMs) como uma alternativa aos grandes modelos de linguagem (LLMs), que podem custar mais para operar sem sacrificar desempenho ou precisão.
Com isso em mente, o Google lançou a versão mais recente de seu modelo pequeno, Gemma, que possui janelas de contexto expandidas, parâmetros maiores e mais capacidades de raciocínio multimodal.
O Gemma 3, que tem a mesma potência de processamento que os modelos maiores Gemini 2.0, é melhor usado em dispositivos menores, como telefones e laptops. O novo modelo possui quatro tamanhos: 1B, 4B, 12B e 27B de parâmetros.
Com uma janela de contexto maior de 128K tokens — em contraste, o Gemma 2 tinha uma janela de contexto de 80K — o Gemma 3 pode entender mais informações e solicitações complexas. O Google atualizou o Gemma 3 para trabalhar em 140 idiomas, analisar imagens, textos e vídeos curtos, além de suportar chamadas de função para automatizar tarefas e fluxos de trabalho agentes.
Gemma oferece um desempenho forte
Para reduzir ainda mais os custos de computação, o Google introduziu versões quantizadas do Gemma. Pense em modelos quantizados como modelos comprimidos. Isso acontece através do processo de “redução da precisão dos valores numéricos nos pesos de um modelo” sem sacrificar a precisão.
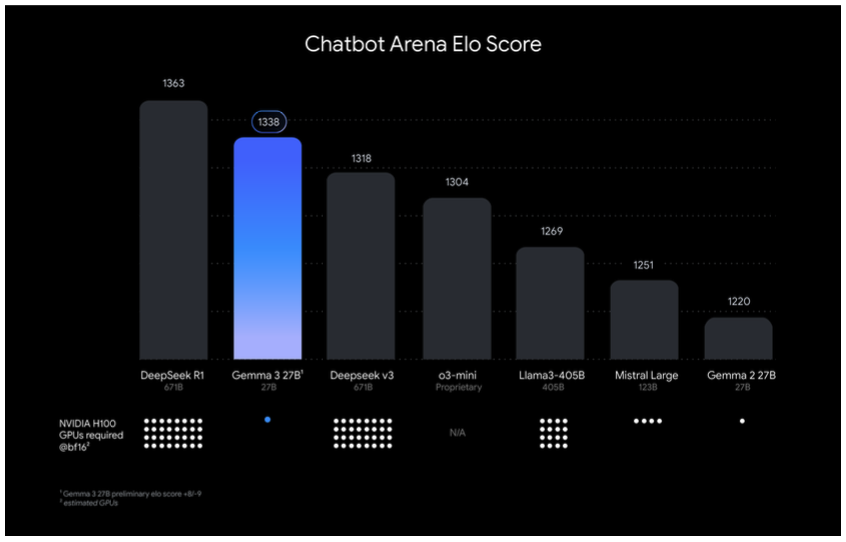
O Google afirmou que o Gemma 3 “oferece desempenho de ponta para seu tamanho” e supera LLMs líderes como Llama-405B, DeepSeek-V3 e o3-mini. O Gemma 3 27B, especificamente, ficou em segundo lugar nos testes de pontuação Elo do Chatbot Arena em comparação ao DeepSeek-R1. Ele superou o DeepSeek’s modelo menor, DeepSeek v3, o OpenAI’s o3-mini, o Meta’s Llama-405B e o Mistral Large.
Ao quantizar o Gemma 3, os usuários podem melhorar o desempenho, executar o modelo e construir aplicações “que podem caber em uma única GPU e unidade de processamento tensorial (TPU)”.
O Gemma 3 integra-se a ferramentas de desenvolvedor como Hugging Face Transformers, Ollama, JAX, Keras, PyTorch e outras. Os usuários também podem acessar o Gemma 3 através do Google AI Studio, Hugging Face ou Kaggle. Empresas e desenvolvedores podem solicitar acesso à API do Gemma 3 através do AI Studio.
Proteja o Gemma para segurança
O Google afirmou que implementou protocolos de segurança no Gemma 3, incluindo um verificador de segurança para imagens chamado ShieldGemma 2.
“O desenvolvimento do Gemma 3 incluiu extensa governança de dados, alinhamento com nossas políticas de segurança através de fine-tuning e avaliações robustas de benchmark,” escreveu o Google em um post no blog. “Enquanto testes completos de modelos mais capazes frequentemente informam nossa avaliação de modelos menos capazes, o desempenho aprimorado em STEM do Gemma 3 levou a avaliações específicas focadas em seu potencial para uso indevido na criação de substâncias prejudiciais; seus resultados indicam um nível de risco baixo.”
O ShieldGemma 2 é um verificador de segurança de imagem de 4B de parâmetros construído sobre a base do Gemma 3. Ele encontra e impede que o modelo responda com imagens contendo conteúdo sexual explícito, violência e outros materiais perigosos. Os usuários podem personalizar o ShieldGemma 2 para atender às suas necessidades específicas.
Modelos pequenos e destilação em ascensão
Desde que o Google lançou o Gemma pela primeira vez em fevereiro de 2024, os SLMs têm visto um aumento no interesse. Outros modelos pequenos, como Phi-4 da Microsoft e Mistral Small 3, indicam que as empresas desejam construir aplicações com modelos tão poderosos quanto os LLMs, mas não necessariamente utilizar toda a amplitude do que um LLM é capaz.
As empresas também começaram a recorrer a versões menores dos LLMs que preferem através da destilação. Para deixar claro, o Gemma não é uma destilação do Gemini 2.0; em vez disso, é treinado com o mesmo conjunto de dados e arquitetura. Um modelo destilado aprende com um modelo maior, o que não é o caso do Gemma.
As organizações geralmente preferem adaptar certos casos de uso a um modelo. Em vez de implantar um LLM como o o3-mini ou Claude 3.7 Sonnet em um editor de código simples, um modelo menor, seja um SLM ou uma versão destilada, pode facilmente realizar essas tarefas sem sobrecarregar um grande modelo.


Conteúdo relacionado

Além do A2A e MCP: Como a Camada de Identidade Universal do Agente LOKA transforma o jogo.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de AI líder no setor. Saiba mais…

Yelp lança agentes de voz com IA para restaurantes e prestadores de serviços.
[the_ad id="145565"] O Yelp anunciou na terça-feira que está trabalhando na implementação de “agentes de voz” impulsionados por IA para ajudar prestadores de serviços e…

Aqui está como assistir ao LlamaCon, o primeiro evento de desenvolvedores de IA da Meta.
[the_ad id="145565"] Na terça-feira, a Meta realizará a LlamaCon, seu primeiro evento de desenvolvedores de IA. O foco será na família de modelos de IA Llama da empresa, e…