


Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba mais
O raciocínio através de cadeias de pensamento (CoT) — o processo pelo qual os modelos dividem problemas em “pensamentos” gerenciáveis antes de deduzir respostas — se tornou uma parte integral da última geração de grandes modelos de linguagem (LLMs) de fronteira.
No entanto, os custos de inferência dos modelos de raciocínio podem rapidamente se acumular à medida que os modelos geram um excesso de tokens CoT. Em um novo artigo, pesquisadores da Carnegie Mellon University propõem uma técnica de treinamento de LLM que oferece aos desenvolvedores mais controle sobre o comprimento do CoT.
Chamado de otimização de política controlada por comprimento (LCPO), a técnica condiciona o modelo a fornecer respostas corretas enquanto mantém seus “pensamentos” dentro de um orçamento de tokens predeterminado. Experimentos mostram que modelos treinados com LCPO oferecem um bom equilíbrio entre precisão e custos e podem surpreendentemente superar modelos maiores em comprimentos de raciocínio iguais. O LCPO pode ajudar a reduzir drasticamente os custos de inferência em aplicações empresariais, economizando milhares de tokens em cada rodada de conversa com um LLM.
Desempenho do LLM leva a CoTs mais longas
Modelos de raciocínio como OpenAI o1 e DeepSeek-R1 são treinados por meio de aprendizado por reforço (RL) para usar escalonamento de tempo de teste e gerar rastros de CoT antes de produzir uma resposta. Evidências empíricas mostram que quando os modelos “pensam” mais, tendem a ter um desempenho melhor em tarefas de raciocínio.
Por exemplo, R1 foi inicialmente treinado apenas com RL sem exemplos etiquetados por humanos. Uma das percepções foi que, à medida que o desempenho do modelo melhorava, ele também aprendia a gerar rastros de CoT mais longos.
Embora, em geral, cadeias de CoT longas resultem em respostas mais precisas, elas também criam um gargalo computacional na aplicação de modelos de raciocínio em escala. Atualmente, há muito pouco controle sobre o orçamento computacional de tempo de teste, e as sequências podem facilmente se estender a dezenas de milhares de tokens sem proporcionar ganhos significativos. Existem alguns esforços para controlar o comprimento das cadeias de raciocínio, mas geralmente degradam o desempenho do modelo.
Otimização de Política Controlada por Comprimento (LCPO) explicada
O método clássico de RL treina LLMs apenas para atingir a resposta correta. O LCPO muda esse paradigma ao introduzir dois objetivos de treinamento: 1) obter o resultado correto e 2) manter a cadeia de CoT limitada dentro de um comprimento específico de tokens. Portanto, se o modelo produzir a resposta correta, mas gerar muitos tokens de CoT, receberá uma penalidade e será forçado a elaborar uma cadeia de raciocínio que chegue à mesma resposta, mas com um orçamento de tokens menor.
“Modelos treinados com LCPO aprendem a satisfazer restrições de comprimento enquanto otimizam o desempenho de raciocínio, em vez de depender de heurísticas projetadas manualmente,” escrevem os pesquisadores.
Eles propõem duas variantes do LCPO: (1) LCPO-exato, que exige que o raciocínio gerado seja exatamente igual ao comprimento alvo, e (2) LCPO-máx, que requer que a saída não seja maior que o comprimento alvo.
Para testar a técnica, os pesquisadores ajustaram um modelo de raciocínio de 1,5 bilhões de parâmetros (Qwen-Distilled-R1-1.5B) nas duas propostas de LCPO para criar os modelos L1-máx e L1-exato. O treinamento foi baseado em problemas matemáticos com resultados distintos e verificáveis. No entanto, a avaliação incluiu problemas matemáticos, bem como tarefas fora da distribuição, como a técnica de medição de compreensão de linguagem multitarefa massiva (MMLU) e o benchmark de perguntas e respostas de nível de graduação do Google (GPQA).
Seus resultados mostram que os modelos L1 podem equilibrar com precisão o orçamento de tokens e o desempenho de raciocínio, interpolando suavemente entre raciocínios curtos e eficientes e raciocínios mais longos e precisos, ao solicitar ao modelo com diferentes restrições de comprimento. Importante, em algumas tarefas, os modelos L1 podem reproduzir o desempenho do modelo de raciocínio original com um orçamento de tokens menor.
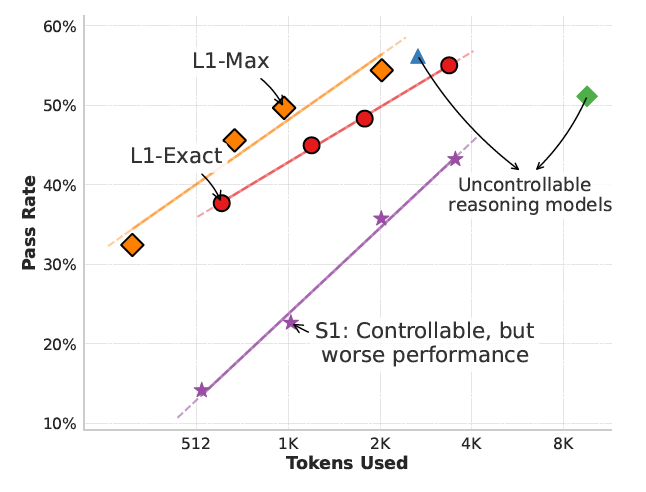
Comparado ao S1 — o único outro método que restringe o comprimento do CoT — os modelos L1 mostram até 150% de ganhos de desempenho em diferentes orçamentos de tokens.
“Essa diferença substancial pode ser atribuída a dois fatores principais,” escrevem os pesquisadores. “(1) L1 adapta inteligentemente seu CoT para caber dentro das restrições de comprimento especificadas sem interromper o processo de raciocínio, enquanto S1 frequentemente trunca no meio do raciocínio; e (2) L1 é explicitamente treinado para gerar cadeias de raciocínio de alta qualidade de comprimentos variados, destilando efetivamente padrões de raciocínio de cadeias mais longas para mais curtas.”
O L1 também supera seu homólogo não-raciocínio em 5% e o GPT-4o em 2% com o mesmo comprimento de geração. “Até onde sabemos, esta é a primeira demonstração de que um modelo de 1,5B pode superar modelos de fronteira como o GPT-4o, apesar de usar o mesmo comprimento de geração,” escrevem os pesquisadores.
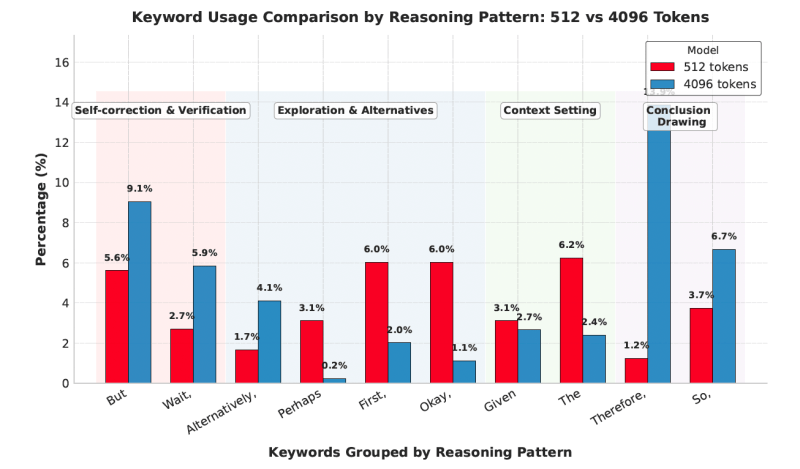
Curiosamente, a CoT do modelo mostra que ele aprende a ajustar seu processo de raciocínio com base em seu orçamento de tokens. Por exemplo, em orçamentos mais longos, o modelo é mais provável que gere tokens associados à autocorreção e verificação (ou seja, “mas” e “espere”) e conclusão (“portanto” e “então”).
Além da melhor controle de comprimento no cenário padrão de raciocínio matemático, os modelos L1 generalizam surpreendentemente bem para tarefas fora da distribuição, incluindo GPQA e MMLU.
Essa nova linha de pesquisa sobre modelos que podem ajustar seu orçamento de raciocínio pode ter usos importantes para aplicações do mundo real, dando às empresas a capacidade de escalar modelos de raciocínio sem despesas excessivas. É uma alternativa poderosa a simplesmente implantar modelos maiores e mais caros — e pode ser um fator crucial para tornar a IA mais economicamente viável para aplicações do mundo real em grande volume.
Os pesquisadores tornaram open source o código do LCPO e os pesos dos modelos L1.


Conteúdo relacionado

O Google está substituindo o Google Assistente pelo Gemini.
O Google substituirá o Google Assistant por Gemini em telefones Android ainda este ano, anunciou a empresa na sexta-feira. O Google disse em um post no…

Assistente de programação de IA Cursor teria dito a um ‘vibe coder’ para escrever seu próprio código.
À medida que as empresas correm para substituir humanos por “agentes” de IA, o assistente de codificação Cursor pode ter nos proporcionado um vislumbre da…

O Congressman republicano Jim Jordan pergunta à Big Tech se Biden tentou censurar a IA.
Na quinta-feira, o presidente da Comissão Judiciária da Câmara, Jim Jordan (R-OH), enviou cartas para 16 empresas de tecnologia americanas, incluindo…