


Participe das nossas newsletters diárias e semanais para as últimas atualizações e conteúdos exclusivos sobre a cobertura de IA líder da indústria. Saiba mais
Os modelos de linguagem de grande escala (LLMs) têm visto avanços notáveis na utilização de capacidades de raciocínio. No entanto, sua habilidade de referenciar e utilizar corretamente dados externos — informações sobre as quais não foram treinados — em conjunto com o raciocínio ainda está aquém do esperado.
Esse é um problema especialmente relevante em cenários dinâmicos e intensivos em informação, que exigem dados atualizados de mecanismos de busca.
Mas uma melhoria chegou: o SEARCH-R1, uma técnica introduzida em um artigo de pesquisadores da Universidade de Illinois em Urbana-Champaign e da Universidade de Massachusetts Amherst, treina LLMs para gerar consultas de busca e integrar facilmente a recuperação de mecanismos de busca em seu raciocínio.
Com as empresas buscando formas de integrar esses novos modelos em suas aplicações, técnicas como o SEARCH-R1 prometem desbloquear novas capacidades de raciocínio que dependem de fontes de dados externas.
O desafio de integrar a busca com LLMs
Os mecanismos de busca são cruciais para fornecer aos aplicativos LLM conhecimento externo e atualizado. Os dois principais métodos para integrar mecanismos de busca com LLMs são Geração Aumentada por Recuperação (RAG) e uso de ferramentas, implementado por meio de engenharia de prompt ou ajuste fino do modelo.
No entanto, ambos os métodos possuem limitações que os tornam inadequados para modelos de raciocínio. O RAG frequentemente luta com imprecisões na recuperação e carece da capacidade de realizar recuperações multi-turno e multi-consulta, que são essenciais para tarefas de raciocínio.
O uso de ferramentas baseado em prompts muitas vezes enfrenta dificuldades de generalização, enquanto as abordagens baseadas em treinamento requerem extensos conjuntos de dados anotados de interações de busca e raciocínio, que são difíceis de produzir em escala.
(Em nossos próprios experimentos com modelos de raciocínio, descobrimos que a recuperação de informações continua sendo um dos principais desafios.)
SEARCH-R1
O SEARCH-R1 permite que os LLMs interajam com mecanismos de busca dentro do seu processo de raciocínio, ao invés de ter uma fase de recuperação separada.
O SEARCH-R1 define o mecanismo de busca como parte do ambiente do LLM, permitindo que o modelo integre sua geração de tokens com os resultados do mecanismo de busca de forma fluida.
Os pesquisadores projetaram o SEARCH-R1 para suportar raciocínio e busca iterativos. O modelo é treinado para gerar conjuntos separados de tokens para segmentos de pensamento, busca, informação e resposta. Isso significa que, durante seu processo de raciocínio (marcado por tags
Essa estrutura permite que o modelo invoque o mecanismo de busca várias vezes enquanto raciocina sobre o problema e obtém novas informações (veja o exemplo abaixo).

Aprendizado por Reforço
Treinar LLMs para intercalar consultas de busca com sua cadeia de raciocínio é desafiador. Para simplificar o processo, os pesquisadores projetaram o SEARCH-R1 para treinar o modelo por meio de aprendizado por reforço puro (RL), onde o modelo pode explorar o uso de raciocínio e ferramentas de busca sem orientação de dados gerados por humanos.
O SEARCH-R1 utiliza um “modelo de recompensa baseado em resultado”, no qual o modelo é avaliado apenas com base na correção da resposta final. Isso elimina a necessidade de criar modelos de recompensa complexos que verifiquem o processo de raciocínio do modelo.
Essa abordagem é a mesma utilizada no DeepSeek-R1-Zero, onde o modelo foi encarregado de uma tarefa e somente julgado com base no resultado. O uso de RL puro elimina a necessidade de criar grandes conjuntos de dados de exemplos anotados manualmente (ajuste fino supervisionado).
“O SEARCH-R1 pode ser visto como uma extensão do DeepSeek-R1, que se concentra principalmente no raciocínio paramétrico ao introduzir treinamento de RL aumentado por busca para uma tomada de decisão orientada à recuperação aprimorada”, escrevem os pesquisadores em seu artigo.
SEARCH-R1 em ação
Os pesquisadores testaram o SEARCH-R1 ajustando as versões base e de instrução do Qwen-2.5 e Llama-3.2 e avaliando-os em sete benchmarks que abrangem uma gama diversificada de tarefas de raciocínio que exigem busca de turno único e múltiplos saltos. Eles compararam o SEARCH-R1 com diferentes referências: inferência direta com raciocínio de Cadeia de Pensamento (CoT), inferência com RAG e ajuste fino supervisionado para uso de ferramentas.
O SEARCH-R1 consistentemente supera os métodos de linha de base por uma margem significativa. Ele também supera modelos de raciocínio treinados em RL, mas sem recuperação de busca. “Isso está alinhado com as expectativas, pois incorporar a busca ao raciocínio do LLM proporciona acesso a conhecimento externo relevante, melhorando o desempenho geral”, escrevem os pesquisadores.
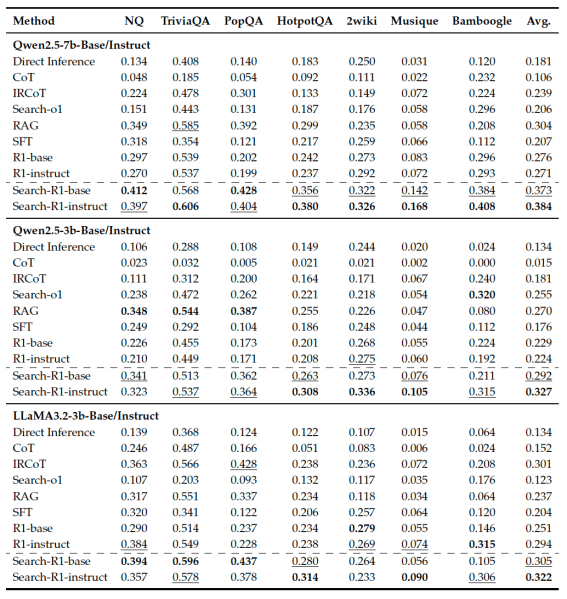
O SEARCH-R1 também é eficaz para diferentes famílias de modelos e variantes ajustadas e de instrução, sugerindo que o RL com recompensas baseadas em resultado pode ser útil além de cenários de raciocínio puro. Os pesquisadores liberaram o código do SEARCH-R1 no GitHub.
A capacidade do SEARCH-R1 de gerar consultas de busca de forma autônoma e integrar informações em tempo real no raciocínio pode ter implicações significativas para aplicações empresariais. Ele pode aprimorar a precisão e confiabilidade de sistemas orientados por LLM em áreas como suporte ao cliente, gerenciamento de conhecimento e análise de dados. Ao permitir que os LLMs se adaptem dinamicamente a informações em mudança, o SEARCH-R1 pode ajudar as empresas a construir soluções de IA mais inteligentes e responsivas. Essa capacidade pode ser extremamente útil para aplicações que exigem acesso a dados em constante mudança e que requerem múltiplos passos para encontrar uma resposta.
Isso também sugere que ainda temos um potencial não explorado da nova paradigma de aprendizado por reforço que surgiu desde o lançamento do DeepSeek-R1.


Conteúdo relacionado

Agentes Guardian: Nova abordagem pode reduzir alucinações em IA para abaixo de 1%
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba mais…

Participe das Sessões TechCrunch: IA com este novo desconto por tempo limitado!
[the_ad id="145565"] Estamos animados em anunciar uma grande surpresa para a comunidade de IA — o TechCrunch Sessions: AI está oferecendo um desconto por tempo limitado para…

Relatório de uso de IA da SimilarWeb revela 5 descobertas surpreendentes, incluindo crescimento explosivo em ferramentas de programação.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre coberturas líder de mercado em IA. Saiba Mais…