


Se você deseja se inserir em uma ferramenta popular de geração de imagens ou vídeos – mas não é famoso o suficiente para que o modelo de fundação o reconheça – precisará treinar um modelo de adaptação de baixa classificação (LoRA) usando uma coleção de suas próprias fotos. Uma vez criado, esse modelo LoRA personalizado permite que o modelo gerador inclua sua identidade em saídas futuras.
Isso é comumente chamado de personalização no setor de pesquisa em síntese de imagem e vídeo. Ele surgiu alguns meses após o advento do Stable Diffusion no verão de 2022, com o projeto DreamBooth do Google Research oferecendo modelos de personalização de alta capacidade, em um esquema de código fechado que logo foi adaptado por entusiastas e liberado para a comunidade.
Os modelos LoRA rapidamente surgiram, oferecendo um treinamento mais fácil e tamanhos de arquivo muito menores, com custo mínimo ou nenhum em qualidade, dominando rapidamente a cena de personalização para Stable Diffusion e seus sucessores, como Flux, e agora novos modelos de vídeo generativo como Hunyuan Video e Wan 2.1.
Repita o Processo
O problema é que, como já notamos, cada vez que um novo modelo é lançado, é necessária uma nova geração de LoRAs para serem treinadas, o que representa uma fricção considerável para os produtores de LoRA, que podem treinar uma variedade de modelos personalizados apenas para descobrir que uma atualização do modelo ou um modelo novo popular significa que eles precisam começar tudo de novo.
Portanto, abordagens de personalização zero-shot se tornaram uma forte corrente na literatura recentemente. Nesse cenário, em vez de precisar curar um conjunto de dados e treinar seu próprio sub-modelo, você simplesmente fornece uma ou mais fotos do sujeito a ser injetado na geração, e o sistema transforma essas fontes de entrada em uma saída mesclada.
Abaixo vemos que, além da troca de rostos, um sistema desse tipo (aqui usando PuLID) também pode incorporar valores de identificação na transferência de estilo:

Exemplos de transferência de ID facial usando o sistema PuLID. Fonte: https://github.com/ToTheBeginning/PuLID?tab=readme-ov-file
Embora substituir um sistema frágil e trabalhoso como o LoRA por um adaptador genérico seja uma ótima (e popular) ideia, isso também é desafiador; a extrema atenção aos detalhes e cobertura obtidas no processo de treinamento do LoRA é muito difícil de imitar em um modelo de estilo IP-Adapter, que precisa igualar o nível de detalhes e flexibilidade do LoRA sem a vantagem prévia de analisar um conjunto abrangente de imagens de identidade.
HyperLoRA
Com isso em mente, há um novo artigo interessante da ByteDance propondo um sistema que gera atualizações de LoRA on-the-fly, o que atualmente é único entre as soluções zero-shot:

À esquerda, imagens de entrada. À direita, uma variedade flexível de saída baseada nas imagens de origem, efetivamente produzindo deepfakes dos atores Anthony Hopkins e Anne Hathaway. Fonte: https://arxiv.org/pdf/2503.16944
O artigo afirma:
‘Técnicas baseadas em adaptadores como o IP-Adapter congelam os parâmetros do modelo fundamental e empregam uma arquitetura plug-in para permitir a inferência zero-shot, mas muitas vezes apresentam falta de naturalidade e autenticidade, que não devem ser negligenciadas em tarefas de síntese de retratos.’
‘[Nós] introduzimos um método de geração adaptativa eficiente em parâmetros, chamado HyperLoRA, que usa uma rede adaptativa plug-in para gerar pesos LoRA, unindo o desempenho superior do LoRA com a capacidade zero-shot do esquema de adaptadores.’
‘Através de nossa estrutura de rede e estratégia de treinamento cuidadosamente projetadas, conseguimos a geração de retratos personalizados zero-shot (suportando entradas de uma ou várias imagens) com alto fotorrealismo, fidelidade e editabilidade.’
Mais útil, o sistema treinado pode ser usado com o ControlNet, permitindo um alto nível de especificidade na geração:

Timothy Chalomet faz uma aparição inesperadamente alegre em ‘O Iluminado’ (1980), com base em três fotos de entrada no HyperLoRA, com uma máscara ControlNet definindo a saída (em conjunto com um prompt de texto).
Quanto à possibilidade de que o novo sistema seja algum dia disponibilizado para usuários finais, a ByteDance tem um histórico razoável a esse respeito, tendo lançado o poderoso LatentSync, framework de sincronização labial, e tendo lançado recentemente o InfiniteYou.
Negativamente, o artigo não indica uma intenção de liberação, e os recursos de treinamento necessários para recriar o trabalho são tão exorbitantes que seria desafiador para a comunidade de entusiastas recriarem (como foi feito com o DreamBooth).
O novo artigo é intitulado HyperLoRA: Geração Adaptativa Eficiente em Parâmetros para Síntese de Retratos, e é resultado do trabalho de sete pesquisadores da ByteDance e do departamento dedicado à Criação Inteligente da ByteDance.
Método
O novo método utiliza o modelo de difusão latente do Stable Diffusion (LDM) SDXL como modelo fundamental, embora os princípios pareçam aplicáveis a modelos de difusão em geral (no entanto, as demandas de treinamento – veja abaixo – podem dificultar a aplicação em modelos de vídeo generativos).
O processo de treinamento do HyperLoRA é dividido em três etapas, cada uma projetada para isolar e preservar informações específicas nos pesos aprendidos. O objetivo deste procedimento restringido é evitar que características relevantes da identidade sejam poluídas por elementos irrelevantes como roupas ou fundo, ao mesmo tempo em que se consegue uma convergência rápida e estável.
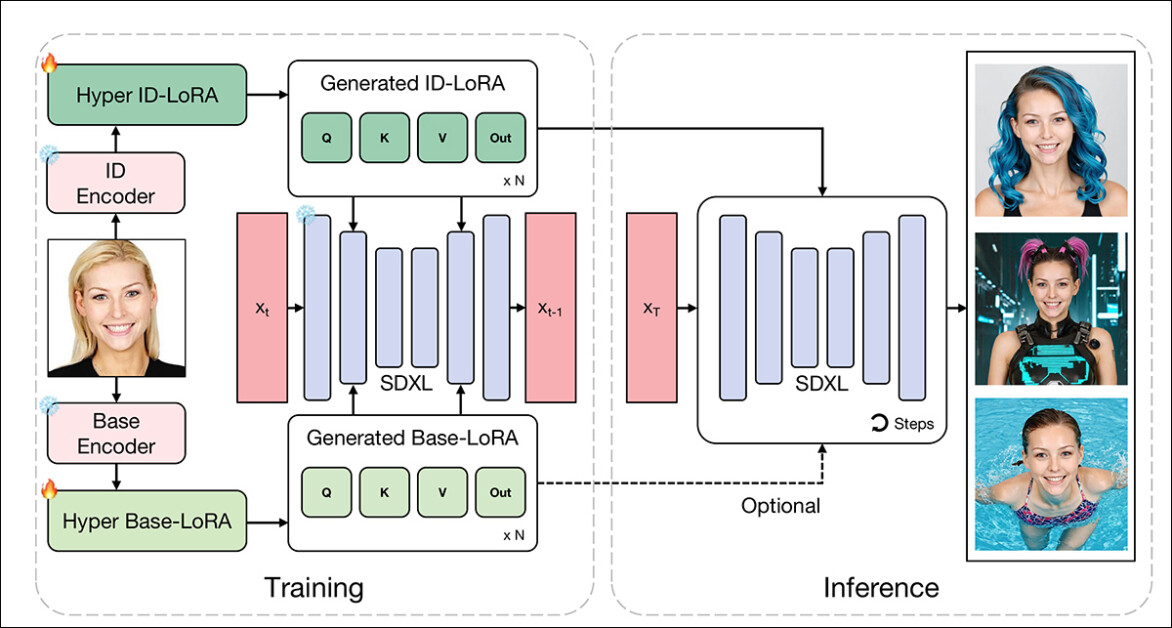
Esquema conceitual para HyperLoRA. O modelo é dividido em ‘Hyper ID-LoRA’ para características de identidade e ‘Hyper Base-LoRA’ para fundo e roupas. Esta separação reduz a contaminação de características. Durante o treinamento, a base SDXL e os codificadores são congelados, e apenas os módulos HyperLoRA são atualizados. Na inferência, apenas o ID-LoRA é necessário para gerar imagens personalizadas.
A primeira etapa foca inteiramente no aprendizado de um ‘Base-LoRA’ (inferior esquerda na imagem do esquema acima), que captura detalhes irrelevantes para a identidade.
Para reforçar essa separação, os pesquisadores deliberadamente borraram o rosto nas imagens de treinamento, permitindo que o modelo identificasse coisas como fundo, iluminação e pose – mas não a identidade. Esta etapa de ‘aquecimento’ atua como um filtro, removendo distrações de baixo nível antes que o aprendizado específico da identidade comece.
Na segunda etapa, um ‘ID-LoRA’ (superior esquerda na imagem do esquema acima) é introduzido. Aqui, a identidade facial é codificada usando dois caminhos paralelos: um Transformador de Visão CLIP para características estruturais e o codificador InsightFace AntelopeV2 para representações de identidade mais abstratas.
Aproximação Transicional
As características do CLIP ajudam o modelo a convergir rapidamente, mas correm o risco de overfitting, enquanto os embeddings do Antelope são mais estáveis, mas mais lentos para treinar. Portanto, o sistema começa confiando mais no CLIP e gradualmente incorpora o Antelope, para evitar instabilidades.
Na etapa final, as camadas de atenção guiadas pelo CLIP são congeladas completamente. Apenas os módulos de atenção vinculados ao AntelopeV2 continuam treinando, permitindo que o modelo refine a preservação da identidade sem degradar a fidelidade ou a generalidade dos componentes já aprendidos.
Essa estrutura em fases é essencialmente uma tentativa de desentrelacemento. Características de identidade e não-identidade são primeiro separadas e, em seguida, refinadas independentemente. É uma resposta metódica aos modos de falha usuais de personalização: desvio de identidade, baixa editabilidade e overfitting em características incidentais.
Enquanto Você Espera
Depois que o CLIP ViT e o AntelopeV2 extraem características tanto estruturais quanto específicas da identidade de um retrato dado, as características obtidas são passadas por um reamostrador percebedor (derivado do projeto mencionado IP-Adapter) – um módulo baseado em transformador que mapeia as características para um conjunto compacto de coeficientes.
Dois reamostradores separados são usados: um para gerar pesos Base-LoRA (que codificam fundo e elementos não-identidade) e outro para pesos ID-LoRA (que se concentram na identidade facial).
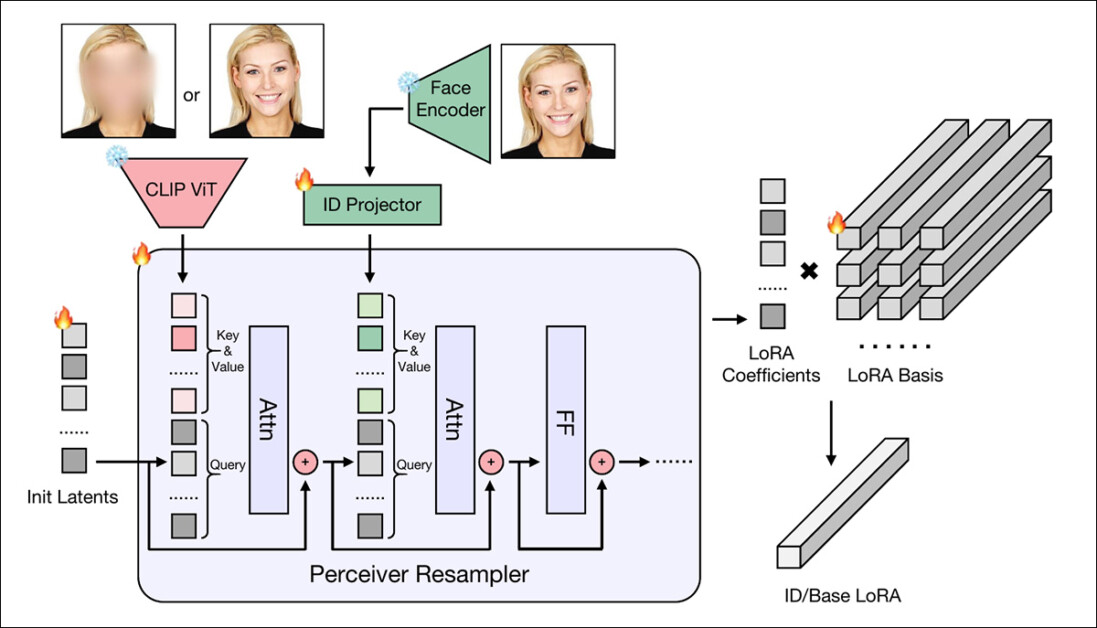
Esquema para a rede HyperLoRA.
Os coeficientes de saída são então combinados linearmente com um conjunto de matrizes de base LoRA aprendidas, produzindo pesos LoRA completos sem a necessidade de ajustar o modelo base.
Essa abordagem permite que o sistema gere pesos personalizados totalmente on-the-fly, usando apenas codificadores de imagem e projeção leve, enquanto ainda aproveita a capacidade do LoRA de modificar o comportamento do modelo base diretamente.
Dados e Testes
Para treinar o HyperLoRA, os pesquisadores usaram um subconjunto de 4,4 milhões de imagens faciais do conjunto de dados LAION-2B (agora mais conhecido como a fonte de dados para os modelos originais Stable Diffusion de 2022).
O InsightFace foi utilizado para filtrar faces não retratadas e imagens múltiplas. As imagens foram então anotadas com o sistema de legendagem BLIP-2.
No que diz respeito à augmentação de dados, as imagens foram recortadas aleatoriamente ao redor do rosto, mas sempre focando na região facial.
Os respectivos ranks de LoRA tiveram que se acomodar à memória disponível na configuração de treinamento. Portanto, o rank de LoRA para ID-LoRA foi definido como 8, e o rank para Base-LoRA como 4, enquanto uma acumulação de gradiente de oito passos foi usada para simular um tamanho de lote maior do que o realmente possível no hardware.
Os pesquisadores treinaram os módulos Base-LoRA, ID-LoRA (CLIP) e ID-LoRA (embedding de identidade) sequencialmente por 20K, 15K e 55K iterações, respectivamente. Durante o treinamento do ID-LoRA, eles amostraram a partir de três cenários de condicionamento com probabilidades de 0.9, 0.05 e 0.05.
O sistema foi implementado usando PyTorch e Diffusers, e todo o processo de treinamento durou aproximadamente dez dias em 16 GPUs NVIDIA A100*.
Testes ComfyUI
Os autores construíram fluxos de trabalho na plataforma de síntese ComfyUI para comparar o HyperLoRA a três métodos rivais: InstantID; o mencionado IP-Adapter, na forma do framework IP-Adapter-FaceID-Portrait; e o citado PuLID. Sementes, prompts e métodos de amostragem consistentes foram usados em todos os frameworks.
Os autores observam que métodos baseados em Adaptadores (em vez de LoRA) geralmente requerem escalas de Classificação Livre de Guia (CFG) mais baixas, enquanto LoRA (incluindo HyperLoRA) é mais permissiva nesse sentido.
Assim, para uma comparação justa, os pesquisadores usaram a variante de checkpoint de fine-tuning de código aberto Hello World do LEOSAM nos testes. Para os testes quantitativos, foi usado o conjunto de dados de imagens Unsplash-50.
Métricas
Para um benchmark de fidelidade, os autores mediram a similaridade facial usando distâncias coseno entre embeddings de imagem CLIP (CLIP-I) e embeddings de identidade separadas (ID Sim) extraídas via CurricularFace, um modelo que não foi utilizado durante o treinamento.
Cada método gerou quatro headshots de alta resolução por identidade no conjunto de teste, com os resultados sendo então averiguados.
A editabilidade foi avaliada tanto comparando as pontuações CLIP-I entre saídas com e sem os módulos de identidade (para ver quanto as restrições de identidade alteravam a imagem); quanto medindo o alinhamento imagem-texto CLIP (CLIP-T) em dez variações de prompt cobrindo penteados, acessórios, roupas e fundos.
Os autores incluíram o modelo de fundação Arc2Face nas comparações – uma linha de base treinada em legendas fixas e regiões faciais recortadas.
Para o HyperLoRA, duas variantes foram testadas: uma usando apenas o módulo ID-LoRA e outra usando tanto ID- quanto Base-LoRA, com este último ponderado em 0.4. Embora o Base-LoRA tenha melhorado a fidelidade, restringiu levemente a editabilidade.
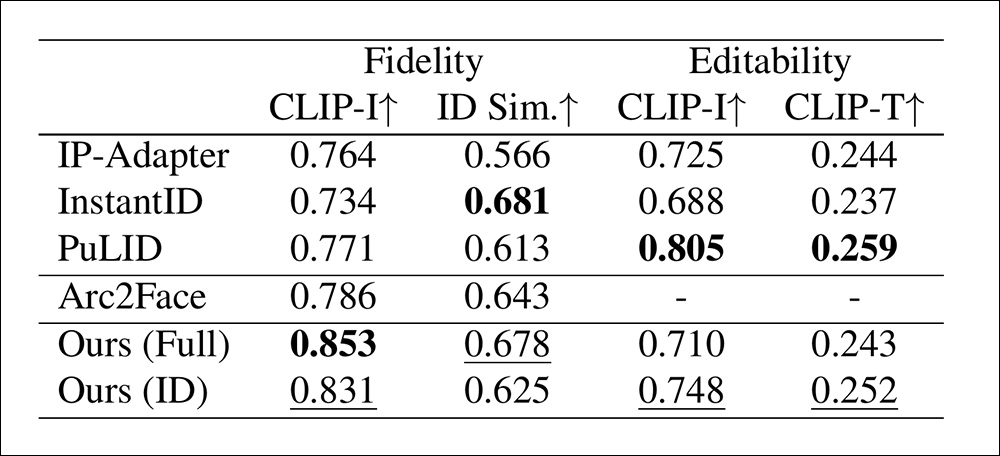
Resultados para a comparação quantitativa inicial.
Nos testes quantitativos, os autores comentam:
‘O Base-LoRA ajuda a melhorar a fidelidade, mas limita a editabilidade. Embora nosso design desacople as características da imagem em diferentes LoRAs, é difícil evitar a contaminação mútua. Assim, podemos ajustar o peso do Base-LoRA para se adaptar a diferentes cenários de aplicação.’
‘Nosso HyperLoRA (Completo e ID) alcança a melhor e a segunda melhor fidelidade facial, enquanto o InstantID demonstra superioridade em similaridade de ID facial, mas menor fidelidade facial.’
‘Essas métricas devem ser consideradas juntas para avaliar a fidelidade, já que a similaridade de ID facial é mais abstrata e a fidelidade facial reflete mais detalhes.’
Nos testes qualitativos, as várias trade-offs envolvidas na proposta essencial se tornam evidentes (observe que não temos espaço para reproduzir todas as imagens dos resultados qualitativos e referimos o leitor ao artigo fonte para mais imagens em melhor resolução):

Comparação qualitativa. De cima para baixo, os prompts usados foram: ‘camisa branca’ e ‘orelhas de lobo’ (ver artigo para exemplos adicionais).
Aqui os autores comentam:
‘A pele dos retratos gerados pelo IP-Adapter e InstantID apresenta uma textura gerada por IA aparente, que é um pouco [excessivamente saturada] e muito longe do fotorrealismo.
‘É uma falha comum dos métodos baseados em Adaptadores. O PuLID melhora esse problema enfraquecendo a intrusão ao modelo base, superando o IP-Adapter e InstantID, mas ainda sofrendo de desfoque e falta de detalhes.’
‘Em contraste, o LoRA modifica diretamente os pesos do modelo base em vez de introduzir módulos de atenção extras, geralmente gerando imagens altamente detalhadas e fotorrealistas.’
Os autores sustentam que, como o HyperLoRA modifica os pesos do modelo base diretamente em vez de depender de módulos de atenção externos, ele retém a capacidade não linear dos métodos tradicionais baseados em LoRA, oferecendo potencialmente uma vantagem em fidelidade e permitindo uma melhor captura de detalhes sutis como a cor da pupila.
Nas comparações qualitativas, o artigo afirma que os layouts do HyperLoRA eram mais coerentes e melhor alinhados com os prompts, e semelhantes aos produzidos pelo PuLID, enquanto notavelmente mais fortes do que InstantID ou IP-Adapter (que ocasionalmente falharam em seguir os prompts ou produzir composições não naturais).

Mais exemplos de gerações do ControlNet com HyperLoRA.
Conclusão
A corrente consistente de vários sistemas de personalização one-shot nos últimos 18 meses adquiriu, a essa altura, uma qualidade de desespero. Muito poucas das ofertas fizeram um avanço notável no estado da arte; e aquelas que avançaram um pouco tendem a ter demandas de treinamento exorbitantes e/ou demandas de inferência extremamente complexas ou intensivas em recursos.
Embora o regime de treinamento do HyperLoRA seja tão assustador quanto muitas entradas recentes semelhantes, ao menos se termina com um modelo que pode lidar com personalização ad hoc imediatamente.
A partir do material suplementar do artigo, notamos que a velocidade de inferência do HyperLoRA é melhor que a do IP-Adapter, mas pior do que as duas outras formas anteriores – e que esses números são baseados em uma GPU NVIDIA V100, que não é um hardware de consumo típico (embora as novas GPUs NVIDIA ‘domésticas’ possam igualar ou exceder o máximo de 32 GB de VRAM da V100).

As velocidades de inferência de métodos concorrentes, em milissegundos.
É justo dizer que a personalização zero-shot continua sendo um problema não resolvido do ponto de vista prático, uma vez que as significativas exigências de hardware do HyperLoRA estão em desacordo com sua capacidade de produzir um modelo de fundação de verdadeiramente longo prazo.
* Representando 640GB ou 1280GB de VRAM, dependendo de qual modelo foi usado (isso não foi especificado)
Publicado pela primeira vez na segunda-feira, 24 de março de 2025

Conteúdo relacionado

$40 bilhões para o fogo: À medida que a OpenAI ganha um milhão de usuários por hora, a corrida pela dominância em IA corporativa acelera em um novo nível.
[the_ad id="145565"] Junte-se aos nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre cobertura de IA líder de indústria.…

Lip-Bu Tan afirma que a Intel irá desmembrar unidades não essenciais.
[the_ad id="145565"] O novo CEO da Intel, Lip-Bu Tan, não perdeu tempo em apresentar seus planos para a gigante dos semicondutores. Falando na conferência Intel Vision esta…

O ChatGPT não é o único chatbot que está ganhando usuários.
[the_ad id="145565"] O ChatGPT da OpenAI pode ser o aplicativo de chatbot mais popular do mundo. No entanto, serviços rivais estão ganhando espaço, de acordo com dados das…