


Inscreva-se em nossos boletins diários e semanais para atualizações mais recentes e conteúdos exclusivos sobre a cobertura de IA líder da indústria. Saiba mais
Estamos nos aproximando do primeiro aniversário desde que a OpenAI lançou seu primeiro modelo “omni” ou multimodal, o GPT-4o, em maio de 2024, mas esse clássico ainda tem algumas cartas na manga.
Por exemplo, hoje a OpenAI finalmente habilitou as capacidades nativas de geração de imagens multimodais do GPT-4o para os usuários de seu popular chatbot ChatGPT nos níveis Plus, Pro, Team e Free, embora a empresa tenha dito que isso também estará disponível em breve para Enterprise, Edu e através de sua interface de programação de aplicativos (API).
Diferente do modelo anterior de IA generativa de imagens disponível no ChatGPT — o DALL-E 3 da OpenAI, um modelo de difusão clássica que foi treinado para reconstruir imagens a partir de prompts de texto removendo ruídos dos pixels — este novo gerador de imagens faz parte do mesmo modelo que gera texto e código, já que a OpenAI treinou todo o modelo para entender todas essas formas de mídia simultaneamente.
O presidente da OpenAI, Greg Brockman, havia previsto há muito tempo essa capacidade nativa do GPT-4o, em maio de 2024, mas por razões que ainda permanecem desconhecidas publicamente, a empresa reteve essa funcionalidade até agora — após o lançamento público de um recurso semelhante visto por muitos usuários avançados de IA no Google AI Studio com seu modelo experimental Gemini 2 Flash.
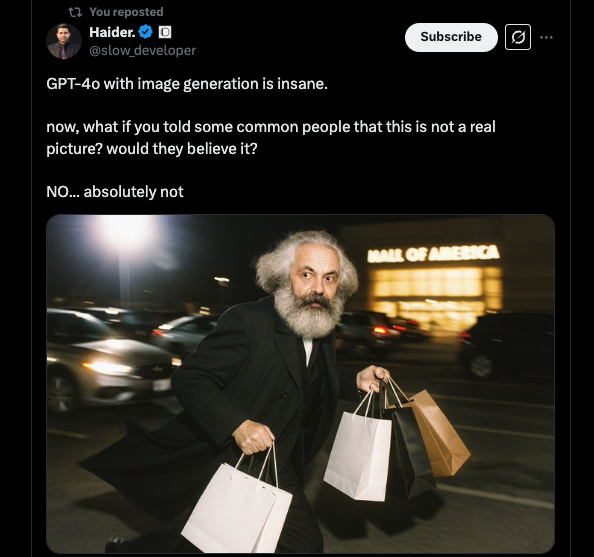
Isso resultou em um gerador de imagens de qualidade muito superior, que produz imagens muito mais realistas e texto incorporado com precisão, já impressionando os usuários — um deles descreveu a qualidade como “insana.”
Por outro lado (trocadilho intencional), a OpenAI ainda não informou precisamente com quais dados as capacidades de geração de imagens do GPT-4o foram treinadas — e dado o histórico da empresa e de outros provedores de modelos, é provável que inclua muitas obras de arte extraídas da web, algumas das quais presumivelmente são protegidas por direitos autorais, o que pode irritar os artistas responsáveis por elas.
Trazendo Geração de Imagens para ChatGPT e Sora
A OpenAI sempre buscou tornar a geração de imagens uma capacidade central de seus modelos de IA. Com o GPT-4o, os usuários agora podem gerar imagens diretamente no ChatGPT, refinando-as através da conversa e ajustando detalhes em tempo real.
O modelo também se integra ao Sora, a plataforma de geração de vídeo da OpenAI, expandindo ainda mais as capacidades multimodais.
Em um anúncio no X, a OpenAI confirmou que a geração de imagens do GPT-4o foi projetada para:
- Renderizar texto com precisão dentro das imagens, permitindo a criação de placas, menus, convites e infográficos.
- Seguir prompts complexos com precisão, mantendo alta fidelidade mesmo em composições detalhadas.
- Construir sobre imagens e textos anteriores, garantindo consistência visual em múltiplas interações.
- Suportar diversos estilos artísticos, desde fotorrealismo até ilustrações estilizadas.
Os usuários podem descrever uma imagem no ChatGPT, especificando detalhes como proporção, esquemas de cores (códigos hexadecimais) ou transparência, e o GPT-4o a gerará em menos de um minuto.
Como escreveu a consultora independente de IA, Allie K. Miller, no X, é um “grande avanço na geração de texto” e é “o melhor” modelo de geração de imagem em IA que ela já viu.

Principais capacidades e casos de uso
O GPT-4o foi projetado para tornar a geração de imagens não apenas visualmente impressionante, mas também prática. Algumas das principais aplicações incluem:
- Design & Branding – Gerar logotipos, pôsteres e anúncios com posicionamento preciso do texto.
- Educação & Visualização – Criar diagramas científicos, infográficos e imagens históricas para aprendizado.
- Desenvolvimento de Jogos – Manter a consistência de personagens em diferentes iterações de design.
- Marketing & Criação de Conteúdo – Produzir ativos para mídias sociais, convites para eventos e ilustrações digitais adaptadas às necessidades da marca.
Como o GPT-4o melhora as imagens geradas em relação ao DALL-E
De acordo com o comunicado oficial da OpenAI no X, o GPT-4o introduz várias melhorias em relação aos modelos anteriores:
- Melhor integração de texto: Diferente de modelos de IA anteriores que enfrentavam dificuldades com texto legível e bem posicionado, o GPT-4o agora pode incorporar palavras com precisão nas imagens.
- Compreensão contextual aprimorada: O GPT-4o utiliza o histórico de chat, permitindo que os usuários refinem as imagens interativamente e mantenham coerência em várias gerações.
- Melhor associação de múltiplos objetos: Enquanto modelos anteriores tinham dificuldade em posicionar corretamente muitos objetos distintos em uma cena, o GPT-4o agora pode lidar com até 10-20 objetos ao mesmo tempo.
- Adaptação de estilo versátil: O modelo pode gerar ou transformar imagens em uma variedade de estilos, desde esboços à mão até fotorrealismo de alta resolução.
Limitações
Apesar de seus avanços, o GPT-4o ainda apresenta alguns desafios conhecidos:
- Problemas de recorte: Imagens grandes, como pôsteres, podem ser recortadas de forma excessivamente apertada.
- Precisão do texto em scripts não latinos: Alguns caracteres que não são em inglês podem não ser renderizados corretamente.
- Retenção de detalhes em texto pequeno: Texto altamente detalhado ou com fontes pequenas pode perder clareza.
- Precisão na edição: Modificar partes específicas de uma imagem pode afetar inadvertidamente outros elementos.
A OpenAI está trabalhando ativamente para resolver esses problemas por meio de refinamentos contínuos do modelo.
Medidas de segurança e rotulagem
Como parte do compromisso da OpenAI com o desenvolvimento responsável de IA, todas as imagens geradas pelo GPT-4o incluem metadados C2PA, permitindo que os usuários verifiquem sua origem em IA.
Além disso, a OpenAI construiu uma ferramenta interna de busca para ajudar a detectar imagens geradas por IA.
Proteções rigorosas estão em vigor para bloquear conteúdo nocivo e prevenir abusos, como proibir imagens explícitas, enganosas ou prejudiciais.
A OpenAI também garante que imagens com pessoas reais estejam sujeitas a restrições mais rigorosas.
O CEO da OpenAI, Sam Altman, descreveu o lançamento como um “novo marco para a liberdade criativa”, enfatizando que os usuários poderão criar uma ampla gama de visuais, com a OpenAI observando e refinando sua abordagem com base no uso no mundo real.
À medida que as imagens geradas por IA se tornam mais precisas e acessíveis, o GPT-4o representa um passo significativo na popularização da geração de imagem a partir de texto como uma ferramenta para comunicação, criatividade e produtividade.


Conteúdo relacionado

CEO da Perplexity nega ter problemas financeiros e afirma que não haverá IPO antes de 2028.
[the_ad id="145565"] Perplexity O CEO da Perplexity, Aravind Srinivas, recentemente recorreu ao Reddit para abordar as reclamações dos usuários sobre o produto e…

Apple estaria reformulando o app Saúde para incluir um treinador de IA.
[the_ad id="145565"] A Apple está desenvolvendo uma nova versão de seu aplicativo de Saúde que inclui um coach de IA que pode aconselhar os usuários sobre como melhorar sua…

Os modelos de IA mais inovadores: o que fazem e como utilizá-los
[the_ad id="145565"] Modelos de IA estão sendo produzidos a um ritmo alucinante, por todos, desde grandes empresas de tecnologia como Google até startups como OpenAI e…