


Participe das nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA líder na indústria. Saiba Mais
DeepSeek AI, um laboratório de pesquisa chinês que vem ganhando reconhecimento por seus poderosos modelos de linguagem de código aberto, como o DeepSeek-R1, introduziu um avanço significativo na modelagem de recompensas para grandes modelos de linguagem (LLMs).
A nova técnica deles, Self-Principled Critique Tuning (SPCT), visa criar modelos de recompensas (RMs) generalistas e escaláveis. Isso pode potencialmente levar a aplicações de IA mais capazes para tarefas e domínios abertos, onde os modelos atuais não conseguem capturar as nuances e complexidades de seu ambiente e usuários.
O papel crucial e as atuais limitações dos modelos de recompensa
O aprendizado por reforço (RL) se tornou uma pedra angular no desenvolvimento de LLMs de última geração. No RL, os modelos são ajustados com base em sinais de feedback que indicam a qualidade de suas respostas.
Os modelos de recompensa são o componente crítico que fornece esses sinais. Essencialmente, um RM atua como um juiz, avaliando as saídas do LLM e atribuindo uma pontuação ou “recompensa” que orienta o processo de RL e ensina o LLM a produzir respostas mais úteis.
No entanto, os RMs atuais frequentemente enfrentam limitações. Eles geralmente se destacam em domínios estreitos com regras claras ou respostas facilmente verificáveis. Por exemplo, os modelos de raciocínio de última geração, como o DeepSeek-R1, passaram por uma fase de RL, na qual foram treinados em problemas de matemática e programação, onde a verdade fundamental é claramente definida.
No entanto, criar um modelo de recompensa para consultas complexas, abertas ou subjetivas em domínios gerais continua sendo um grande desafio. No artigo que explica sua nova técnica, os pesquisadores da DeepSeek AI escrevem: “Um RM generalista precisa gerar recompensas de alta qualidade além de domínios específicos, onde os critérios para recompensas são mais diversos e complexos, e muitas vezes não há referências explícitas ou verdades fundamentais.”
Eles destacam quatro desafios principais na criação de RMs generalistas capazes de lidar com tarefas mais amplas:
- Flexibilidade de entrada: O RM deve lidar com vários tipos de entrada e ser capaz de avaliar uma ou mais respostas simultaneamente.
- Precisão: Deve gerar sinais de recompensa precisos em diversos domínios onde os critérios são complexos e a verdade fundamental está frequentemente indisponível.
- Escalabilidade em tempo de inferência: O RM deve produzir recompensas de maior qualidade quando mais recursos computacionais são alocados durante a inferência.
- Aprendendo comportamentos escaláveis: Para que os RMs escalem efetivamente em tempo de inferência, precisam aprender comportamentos que permitam uma performance melhorada à medida que mais computação é utilizada.
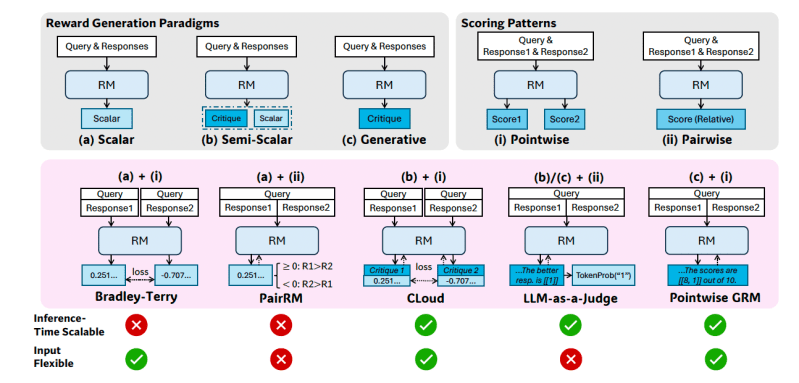
Os modelos de recompensa podem ser amplamente classificados por seu “paradigma de geração de recompensas” (por exemplo, RMs escalares que produzem uma única pontuação, RMs generativos que produzem críticas textuais) e seu “padrão de pontuação” (por exemplo, a pontuação pontual atribui pontuações individuais a cada resposta, enquanto a pareada seleciona a melhor de duas respostas). Essas escolhas de design afetam a adequação do modelo para tarefas generalistas, particularmente sua flexibilidade de entrada e potencial para escalabilidade em tempo de inferência.
Por exemplo, RMs escalares simples têm dificuldade com escalabilidade em tempo de inferência porque geram a mesma pontuação repetidamente, enquanto RMs pareados não conseguem avaliar facilmente respostas individuais.
Os pesquisadores propõem que a “modelagem de recompensa generativa pontual” (GRM), onde o modelo gera críticas textuais e deriva suas pontuações a partir delas, pode oferecer a flexibilidade e escalabilidade necessárias para requisitos generalistas.
A equipe da DeepSeek realizou experimentos preliminares em modelos como GPT-4o e Gemma-2-27B e descobriu que “certos princípios poderiam guiar a geração de recompensas dentro de critérios adequados para GRMs, melhorando a qualidade das recompensas, o que nos inspirou a crer que a escalabilidade em tempo de inferência do RM poderia ser alcançada por meio da ampliação da geração de princípios de alta qualidade e críticas precisas.”
Treinando RMs para gerar seus próprios princípios
Com base nesses achados, os pesquisadores desenvolveram o Self-Principled Critique Tuning (SPCT), que treina o GRM para gerar princípios e críticas com base em consultas e respostas de forma dinâmica.
Os pesquisadores propõem que os princípios devem ser “parte da geração de recompensa em vez de uma etapa de pré-processamento.” Dessa forma, os GRMs podem gerar princípios em tempo real com base na tarefa que estão avaliando e, em seguida, gerar críticas com base nos princípios.
“Essa mudança permite que os princípios sejam gerados com base na consulta de entrada e nas respostas, alinhando adaptativamente o processo de geração de recompensas, e a qualidade e granularidade dos princípios e críticas correspondentes podem ser ainda mais aprimoradas com pós-treinamento no GRM,” escrevem os pesquisadores.
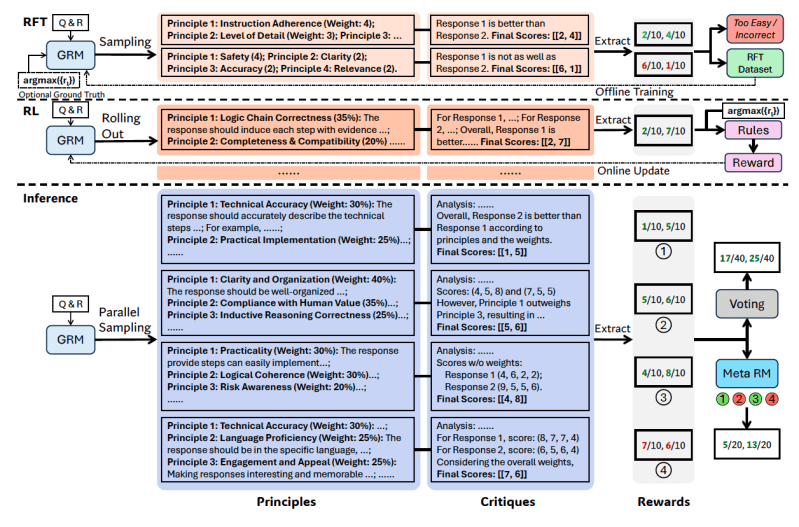
O SPCT envolve duas fases principais:
- Ajuste rejeitivo: Esta fase treina o GRM para gerar princípios e críticas para vários tipos de entrada usando o formato correto. O modelo gera princípios, críticas e recompensas para consultas/respostas dadas. As trajetórias (tentativas de geração) são aceitas apenas se a recompensa prevista estiver alinhada com a verdade fundamental (identificando corretamente a melhor resposta, por exemplo) e rejeitadas caso contrário. Esse processo é repetido e o modelo é ajustado com os exemplos filtrados para melhorar suas capacidades de geração de princípios/críticas.
- RL baseado em regras: Nessa fase, o modelo é ajustado ainda mais por meio do aprendizado por reforço baseado em resultados. O GRM gera princípios e críticas para cada consulta, e os sinais de recompensa são calculados com base em regras de precisão simples (por exemplo, se ele escolheu a resposta conhecida como a melhor). O modelo é então atualizado. Isso incentiva o GRM a aprender como gerar princípios eficazes e críticas precisas de maneira dinâmica e escalável.
“Ao aproveitar o RL online baseado em regras, o SPCT permite que os GRMs aprendam a positivamente e adaptivamente positarem princípios e críticas com base na consulta de entrada e nas respostas, levando a melhores recompensas de resultados em domínios gerais”, escrevem os pesquisadores.
Para enfrentar o desafio da escalabilidade em tempo de inferência (obter melhores resultados com mais computação), os pesquisadores rodam o GRM várias vezes para a mesma entrada, gerando diferentes conjuntos de princípios e críticas. A recompensa final é determinada por votação (agregando os índices de amostra). Isso permite que o modelo considere uma gama mais ampla de perspectivas, levando a julgamentos finais potencialmente mais precisos e nuançados à medida que é fornecido com mais recursos.
No entanto, alguns princípios/críticas gerados podem ser de baixa qualidade ou tendenciosos devido a limitações do modelo ou aleatoriedade. Para abordar isso, os pesquisadores introduziram um “meta RM”—um RM escalar separado e leve treinado especificamente para prever se um princípio/crítica gerado pelo GRM primário irá provavelmente levar a uma recompensa final correta.
Durante a inferência, o meta RM avalia as amostras geradas e filtra os julgamentos de baixa qualidade antes da votação final, aprimorando ainda mais o desempenho na escalabilidade.
Colocando o SPCT em prática com DeepSeek-GRM
Os pesquisadores aplicaram o SPCT ao Gemma-2-27B, o modelo de pesos abertos do Google, criando o DeepSeek-GRM-27B. Eles o avaliaram em relação a vários RMs de linha de base fortes (incluindo LLM-as-a-Judge, RMs escalares e RMs semi-esfericos) e modelos públicos (como GPT-4o e Nemotron-4-340B-Reward) em múltiplos benchmarks.
Descobriram que o DeepSeek-GRM-27B superou os métodos de linha de base treinados com os mesmos dados. O SPCT melhorou significativamente a qualidade e, crucialmente, a escalabilidade em tempo de inferência em comparação ao ajuste fino padrão.
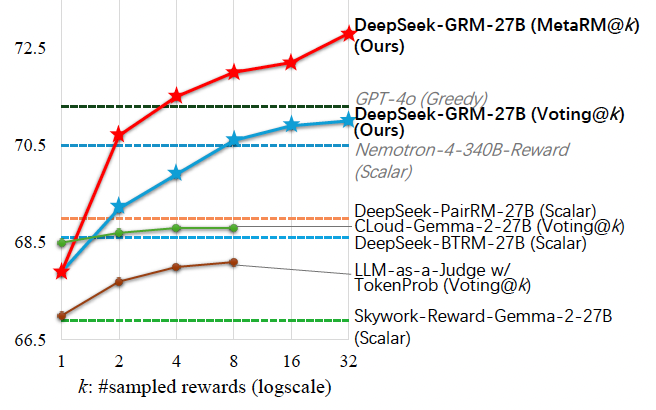
Quando escalado em tempo de inferência gerando mais amostras, o desempenho do DeepSeek-GRM-27B aumentou substancialmente, superando até modelos muito maiores, como Nemotron-4-340B-Reward e GPT-4o. O meta RM melhorou ainda mais a escalabilidade, alcançando os melhores resultados ao filtrar os julgamentos.
“Com amostras em maior escala, o DeepSeek-GRM poderia julgar mais precisamente sobre princípios com maior diversidade e gerar recompensas com maior granularidade”, escrevem os pesquisadores.
Curiosamente, o SPCT apresentou menos viés entre diferentes domínios comparado aos RMs escalares, que geralmente se saem bem em tarefas verificáveis, mas mal em outros lugares.
Implicações para a empresa
Desenvolver modelos de recompensa mais generalistas e escaláveis pode ser promissor para aplicações de IA em empresas. Áreas potenciais que podem se beneficiar de RMs generalistas incluem tarefas criativas e aplicações onde o modelo precisa se adaptar a ambientes dinâmicos, como preferências dos clientes em evolução.
Apesar dos resultados fortes, o DeepSeek-GRM ainda fica atrás dos RMs escalares especializados em tarefas puramente verificáveis, onde a geração de raciocínio explícito pode ser menos eficiente do que a pontuação direta. A eficiência também continua sendo um desafio em comparação aos RMs não generativos.
A equipe da DeepSeek sugere que trabalhos futuros se concentrem em melhorias de eficiência e integração mais profunda. Como concluem, “As direções futuras podem incluir a integração de GRMs em pipelines de RL online como interfaces versáteis de sistemas de recompensa, explorando a co-escalabilidade em tempo de inferência com modelos de política ou servindo como avaliadores robustos offline para modelos fundamentais.”


Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…