


Uma vez que o setor de publicidade online está estimado em gastar 740,3 bilhões de dólares em 2023, é fácil entender por que as empresas de publicidade investem consideráveis recursos nesta área específica da pesquisa em visão computacional.
Embora seja insular e protetora, a indústria ocasionalmente publica estudos que sugerem avanços mais sofisticados em trabalhos proprietários relacionados ao reconhecimento facial e de olhar – incluindo reconhecimento de idade, essencial para estatísticas de análise demográfica:

A estimativa de idade em um contexto de publicidade na natureza é de interesse para anunciantes que podem estar visando um determinado grupo demográfico. Neste exemplo experimental de estimativa automática de idade facial, a idade do artista Bob Dylan é rastreada ao longo dos anos. Fonte: https://arxiv.org/pdf/1906.03625
Estudos como esses, que raramente aparecem em repositórios públicos como o Arxiv, utilizam participantes recrutados legitimamente como base para uma análise impulsionada por IA, que visa determinar até que ponto e de que forma o espectador está engajado com um anúncio.

O Histograma de Gradientes Orientados (HoG) do Dlib é frequentemente usado em sistemas de estimativa facial. Fonte: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Instinto Animal
Nesse aspecto, a indústria da publicidade está interessada em determinar falsos positivos (ocasiões em que um sistema analítico interpreta erroneamente as ações de um sujeito) e em estabelecer critérios claros para quando a pessoa assistindo aos anúncios não está totalmente engajada com o conteúdo.
No que diz respeito à publicidade em tela, os estudos tendem a se concentrar em dois problemas em dois ambientes. Os ambientes são ‘desktop’ ou ‘mobile’, cada um dos quais possui características particulares que exigem soluções de rastreamento personalizadas; e os problemas – do ponto de vista do anunciante – são representados pelo comportamento de coruja e comportamento de lagarto – a tendência dos espectadores de não prestar total atenção a um anúncio que está diante deles.

Exemplos de comportamento de ‘Coruja’ e ‘Lagarto’ em um projeto de pesquisa publicitária. Fonte: https://arxiv.org/pdf/1508.04028
Se você está olhando para longe do anúncio pretendido com a cabeça inteira, isso é ‘comportamento de coruja’; se sua pose de cabeça está estática, mas seus olhos estão perambulando para longe da tela, isso é ‘comportamento de lagarto’. Em termos de análises e testes de novos anúncios sob condições controladas, essas são ações essenciais que um sistema deve captar.
Um novo artigo da aquisição Affectiva da SmartEye aborda essas questões, oferecendo uma arquitetura que aproveita várias estruturas existentes para fornecer um conjunto de recursos combinados e concatenados em todas as condições necessárias e possíveis reações – e para ser capaz de dizer se um espectador está entediado, engajado ou de alguma forma afastado do conteúdo que o anunciante deseja que eles assistam.
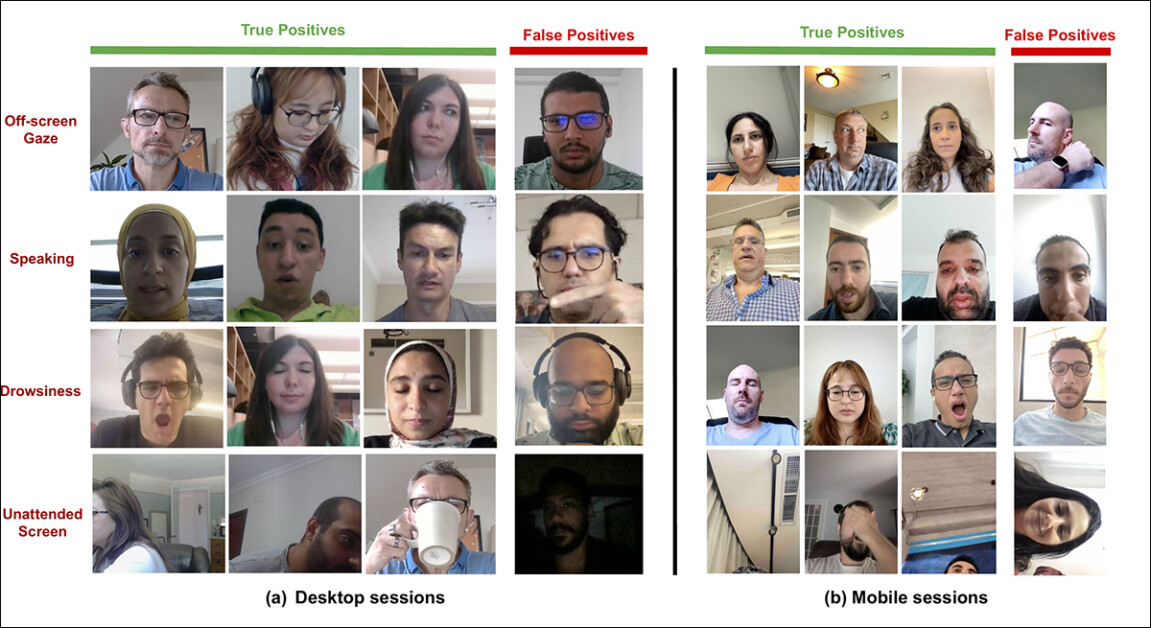
Exemplos de verdadeiros e falsos positivos detectados pelo novo sistema de atenção para vários sinais de distração, mostrados separadamente para dispositivos desktop e mobile. Fonte: https://arxiv.org/pdf/2504.06237
Os autores afirmam*:
‘Pesquisas limitadas têm analisado a atenção durante anúncios online. Enquanto esses estudos se concentraram em estimar a pose da cabeça ou a direção do olhar para identificar instâncias de desvio do olhar, eles ignoram parâmetros críticos, como o tipo de dispositivo (desktop ou móvel), a posição da câmera em relação à tela e o tamanho da tela. Esses fatores influenciam significativamente a detecção de atenção.
‘Neste artigo, propomos uma arquitetura para a detecção de atenção que abrange a detecção de vários distraidores, incluindo tanto o comportamento de coruja quanto de lagarto, olhar fora da tela, fala, sonolência (através de bocejos e fechamento prolongado dos olhos) e deixar a tela sem supervisão.
‘Ao contrário das abordagens anteriores, nosso método integra recursos específicos para dispositivos, como tipo de dispositivo, posição da câmera, tamanho da tela (para desktops) e orientação da câmera (para dispositivos móveis) com a estimativa bruta do olhar para melhorar a precisão da detecção de atenção.’
O novo trabalho é intitulado Monitoramento da Atenção do Espectador Durante Anúncios Online, e vem de quatro pesquisadores da Affectiva.
Método e Dados
Em grande parte devido ao sigilo e à natureza de código fechado de tais sistemas, o novo artigo não compara a abordagem dos autores diretamente com rivais, mas apresenta suas descobertas exclusivamente como estudos de ablação; o artigo também não adere, em geral, ao formato usual da literatura de Visão Computacional. Portanto, vamos analisar a pesquisa conforme ela é apresentada.
Os autores enfatizam que apenas um número limitado de estudos abordou especificamente a detecção de atenção no contexto de anúncios online. No AFFDEX SDK, que oferece reconhecimento de múltiplos rostos em tempo real, a atenção é inferida apenas a partir da pose da cabeça, com os participantes sendo rotulados como desatentos se o ângulo de sua cabeça ultrapassar um limite definido.

Um exemplo do SDK AFFDEX, um sistema da Affectiva que depende da pose da cabeça como um indicador de atenção. Fonte: https://www.youtube.com/watch?v=c2CWb5jHmbY
No colaboração de 2019 Medição Automática da Atenção Visual ao Conteúdo de Vídeo Usando Aprendizado Profundo, um conjunto de dados de cerca de 28.000 participantes foi anotado para vários comportamentos de desatenção, incluindo olhar para longe, fechar os olhos ou se envolver em atividades não relacionadas, e um modelo CNN-LSTM foi treinado para detectar atenção a partir da aparência facial ao longo do tempo.

Do artigo de 2019, um exemplo ilustrando os estados de atenção previstos para um espectador assistindo a conteúdo de vídeo. Fonte: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
Entretanto, os autores observam que esses esforços anteriores não consideraram fatores específicos do dispositivo, como se o participante estava usando um desktop ou dispositivo móvel; nem consideraram o tamanho da tela ou a posição da câmera. Além disso, o sistema AFFDEX se concentra apenas na identificação do desvio do olhar, e omite outras fontes de distração, enquanto o trabalho de 2019 tenta detectar um conjunto mais amplo de comportamentos – mas seu uso de uma única CNN rasa pode, segundo o artigo, ter sido inadequado para essa tarefa.
Os autores observam que algumas das pesquisas mais populares nesta linha não estão otimizadas para testes de anúncios, que têm necessidades diferentes em comparação com domínios como direção ou educação – onde a colocação e calibração da câmera geralmente são fixas de antemão, dependendo em vez disso de configurações não calibradas, e operando dentro do alcance limitado de visão de dispositivos desktop e móveis.
Portanto, eles elaboraram uma arquitetura para detectar a atenção do espectador durante anúncios online, aproveitando duas ferramentas comerciais: AFFDEX 2.0 e SmartEye SDK.

Exemplos de análise facial do AFFDEX 2.0. Fonte: https://arxiv.org/pdf/2202.12059
Esses trabalhos anteriores extraem recursos de baixo nível como expressões faciais, pose da cabeça e direção do olhar. Esses recursos são então processados para produzir indicadores de nível superior, incluindo a posição do olhar na tela; bocejos; e fala.
O sistema identifica quatro tipos de distração: olhar fora da tela; sonolência; fala; e telas desatendidas. Ele também ajusta a análise do olhar de acordo com se o espectador está em um desktop ou dispositivo móvel.
Conjuntos de Dados: Olhar
Os autores usaram quatro conjuntos de dados para alimentar e avaliar o sistema de detecção de atenção: três focando individualmente no comportamento do olhar, fala e bocejo; e um quarto extraído de sessões de testes reais de anúncios contendo uma mistura de tipos de distração.
Devido aos requisitos específicos do trabalho, conjuntos de dados personalizados foram criados para cada uma dessas categorias. Todos os conjuntos de dados curados foram obtidos de um repositório proprietário contendo milhões de sessões gravadas de participantes assistindo a anúncios em ambientes domésticos ou de trabalho, utilizando uma configuração baseada na web, com consentimento informado – e devido às limitações dos acordos de consentimento, os autores afirmam que os conjuntos de dados para o novo trabalho não podem ser disponibilizados publicamente.
Para construir o conjunto de dados de olhar, os participantes foram solicitados a seguir um ponto em movimento por várias partes da tela, incluindo suas bordas, e depois olhar para longe da tela em quatro direções (cima, baixo, esquerda e direita), repetindo a sequência três vezes. Dessa forma, a relação entre captura e cobertura foi estabelecida:
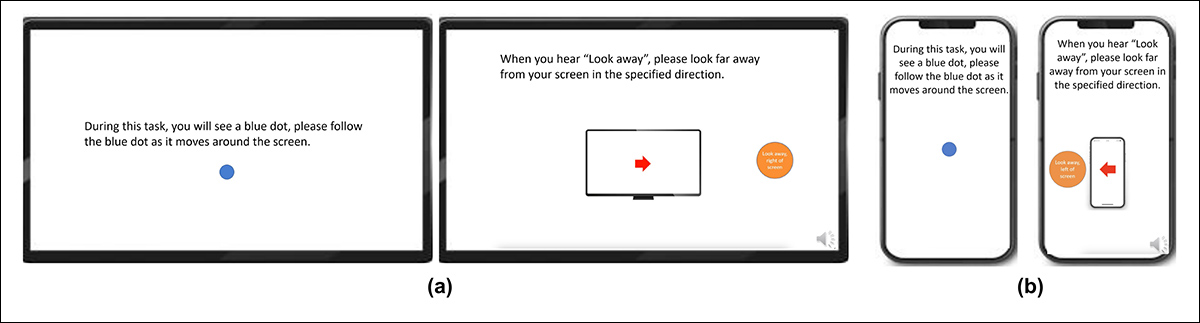
Capturas de tela mostrando o estímulo de vídeo do olhar em (a) dispositivos desktop e (b) móveis. As primeiras e terceiras imagens exibem instruções para seguir um ponto em movimento, enquanto a segunda e a quarta pedem aos participantes que olhem para longe da tela.
Os segmentos com o ponto em movimento foram rotulados como atento, e os segmentos fora da tela como desatento, produzindo um conjunto de dados rotulado com exemplos positivos e negativos.
Cada vídeo durou cerca de 160 segundos, com versões separadas criadas para plataformas desktop e móvel, cada uma com resoluções de 1920×1080 e 608×1080, respectivamente.
No total, 609 vídeos foram coletados, compreendendo 322 gravações em desktop e 287 em mobile. Rótulos foram aplicados automaticamente com base no conteúdo do vídeo, e o conjunto de dados dividido em 158 amostras de treinamento e 451 para testes.
Conjuntos de Dados: Fala
Nesse contexto, um dos critérios que define ‘desatenção’ é quando uma pessoa fala por mais de um segundo (o que pode ser um comentário momentâneo, ou até mesmo um dorso).
Uma vez que o ambiente controlado não grava ou analisa áudio, a fala é inferida observando-se o movimento interno dos marcos faciais estimados. Portanto, para detectar fala sem áudio, os autores criaram um conjunto de dados baseado inteiramente na entrada visual, extraído de seu repositório interno, e dividido em duas partes: a primeira continha aproximadamente 5.500 vídeos, cada um rotulado manualmente por três anotadores como falando ou não falando (desses, 4.400 foram usados para treinamento e validação, e 1.100 para testes).
A segunda parte compreendia 16.000 sessões rotuladas automaticamente com base no tipo de sessão: 10.500 apresentavam participantes assistindo silenciosamente a anúncios e 5.500 mostravam participantes expressando opiniões sobre marcas.
Conjuntos de Dados: Bocejos
Embora alguns conjuntos de dados ‘de bocejo’ existam, incluindo YawDD e Detecção de Bocejos para Monitoramento de Fadiga do Motorista, os autores afirmam que nenhum é adequado para cenários de teste de anúncios, uma vez que apresentam bocejos simulados ou contorções faciais que poderiam ser confundidas com medo, ou outras ações não relacionadas a bocejos.
Portanto, os autores utilizaram 735 vídeos de sua coleção interna, escolhendo sessões que provavelmente contivessem uma deslocação da mandíbula que durasse mais de um segundo. Cada vídeo foi rotulado manualmente por três anotadores como mostrando bocejos ativos ou bocejos inativos. Apenas 2,6 por cento dos quadros continham bocejos ativos, ressaltando o desbalanceamento da classe, e o conjunto de dados foi dividido em 670 vídeos de treinamento e 65 para testes.
Conjuntos de Dados: Distração
O conjunto de dados de distração também foi extraído do repositório de testes publicitários dos autores, onde participantes assistiram a anúncios reais sem tarefas atribuídas. Um total de 520 sessões (193 em mobile e 327 em desktop) foram selecionadas aleatoriamente e rotuladas manualmente por três anotadores como atentos ou desatentos.
O comportamento desatento incluiu olhar fora da tela, fala, sonolência e telas desatendidas. As sessões abrangem diversas regiões do mundo, com gravações em desktop sendo mais comuns, devido à flexibilidade na colocação da webcam.
Modelos de Atenção
O modelo de atenção proposto processa recursos visuais de baixo nível, a saber, expressões faciais; pose da cabeça; e direção do olhar – extraídos através do mencionado AFFDEX 2.0 e SmartEye SDK.
Esses são então convertidos em indicadores de nível superior, com cada distraidor tratado por um classificador binário separado treinado em seu próprio conjunto de dados para otimização e avaliação independentes.
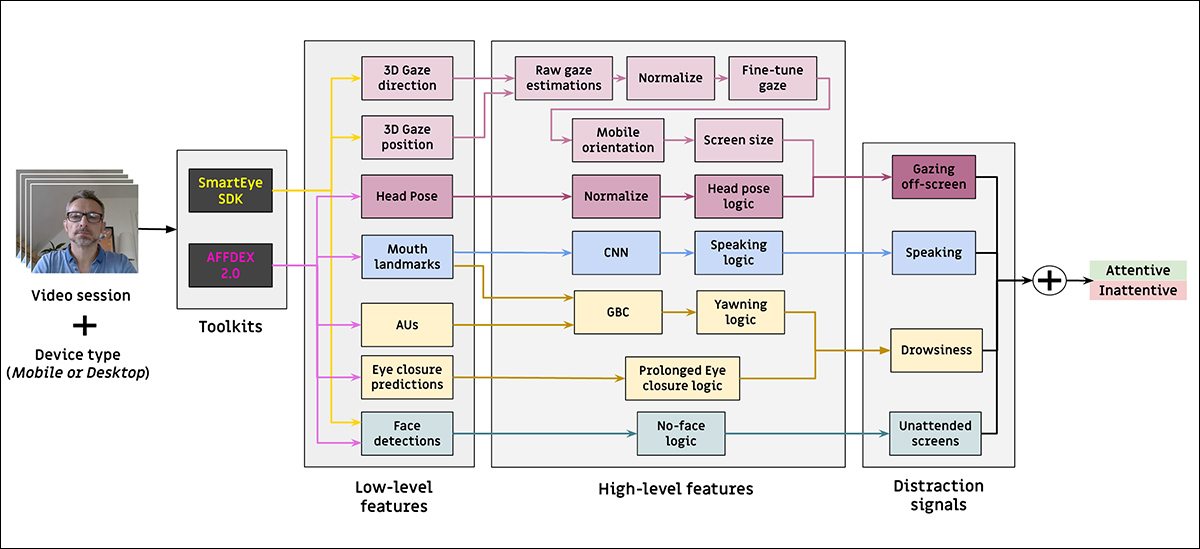
Esquema para o sistema de monitoramento proposto.
O modelo de olhar determina se o espectador está olhando para ou longe da tela usando coordenadas normalizadas do olhar, com calibração separada para dispositivos desktop e móveis. Ajudando nesse processo está uma Máquina de Vetores de Suporte (SVM) linear, treinada em características espaciais e temporais, que incorpora uma janela de memória para suavizar mudanças rápidas no olhar.
Para detectar fala sem áudio, o sistema utilizou regiões da boca recortadas e uma 3D-CNN treinada em segmentos de vídeo conversacionais e não conversacionais. Os rótulos foram atribuídos com base no tipo de sessão, com o suavização temporal reduzindo os falsos positivos que podem resultar de breves movimentos labiais.
Bocejos foram detectados utilizando recortes de imagem do rosto inteiro, para capturar movimentos faciais mais amplos, com uma 3D-CNN treinada em quadros rotulados manualmente (embora a tarefa tenha sido complicada pela baixa frequência de bocejos em visualização natural, e pela semelhança com outras expressões).
Abandono de tela foi identificado pela ausência de um rosto ou uma pose de cabeça extrema, com previsões feitas por uma árvore de decisão.
Status final de atenção foi determinado usando uma regra fixa: se qualquer módulo detectasse desatenção, o espectador seria marcado como desatento – uma abordagem priorizando sensibilidade, ajustada separadamente para contextos desktop e móveis.
Testes
Como mencionado anteriormente, os testes seguem um método ablativo, onde componentes são removidos e o efeito sobre o resultado é anotado.

Diferentes categorias de desatenção percebida identificadas no estudo.
O modelo de olhar identificou o comportamento fora da tela através de três etapas principais: normalizando as estimativas brutas do olhar, ajustando a saída e estimando o tamanho da tela para dispositivos desktop.
Para entender a importância de cada componente, os autores os removeram individualmente e avaliaram o desempenho em 226 vídeos desktop e 225 mobile extraídos de dois conjuntos de dados. Os resultados, medidos por G-mean e F1 scores, são mostrados abaixo:

Resultados indicando o desempenho do modelo de olhar completo, juntamente com versões com etapas de processamento individuais removidas.
Em todos os casos, o desempenho declinou quando um passo foi omitido. A normalização revelou-se especialmente valiosa em desktops, onde a colocação da câmera varia mais do que em dispositivos móveis.
O estudo também avaliou como recursos visuais previram a orientação da câmera móvel: a localização do rosto, a pose da cabeça e o olhar pontuaram 0,75, 0,74 e 0,60, enquanto sua combinação alcançou 0,91, destacando – os autores afirmam – a vantagem de integrar múltiplas pistas.
O modelo de fala, treinado na distância vertical dos lábios, obteve uma ROC-AUC de 0,97 no conjunto de testes rotulado manualmente, e 0,96 no conjunto de dados rotulado automaticamente maior, indicando desempenho consistente em ambos.
O modelo de bocejos alcançou um ROC-AUC de 96,6% usando apenas a razão da boca, que melhorou para 97,5% quando combinado com previsões de unidades de ação do AFFDEX 2.0.
O modelo de tela desatendida classificou momentos como desatentos quando tanto o AFFDEX 2.0 quanto o SmartEye não conseguiram detectar um rosto por mais de um segundo. Para avaliar a validade disso, os autores anotaram manualmente todos os eventos sem rosto no conjunto de dados de distração real, identificando a causa subjacente de cada ativação. Casos ambíguos (como obstrução da câmera ou distorção de vídeo) foram excluídos da análise.
Como mostrado na tabela de resultados abaixo, apenas 27% das ativações de ‘sem rosto’ ocorreram devido os usuários deixarem fisicamente a tela.
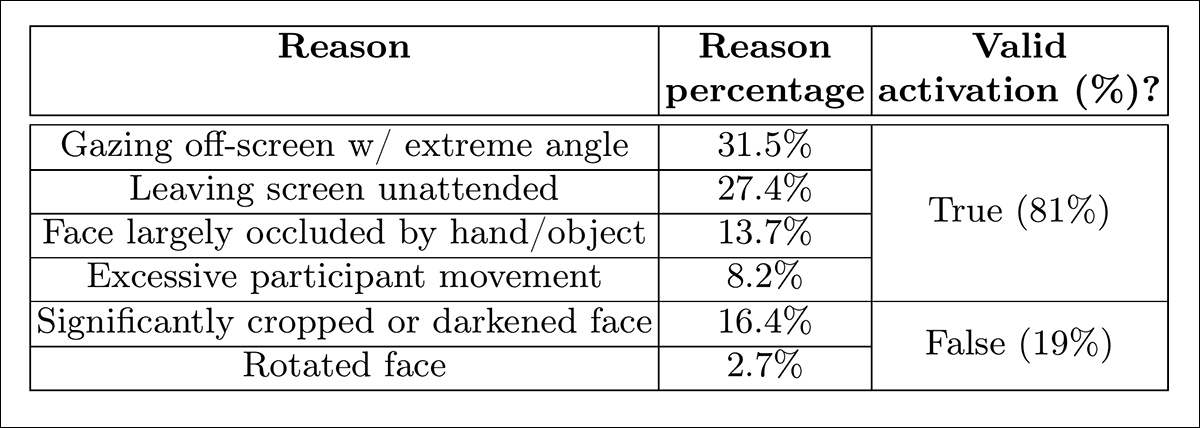
Diversas razões obtidas para a falta de um rosto encontrado, em certas instâncias.
O artigo afirma:
‘Apesar de as telas desatendidas constituírem apenas 27% das instâncias ativando o sinal sem rosto, foi ativado por outras razões indicativas de desatenção, como os participantes olhando para longe com um ângulo extremo, fazendo movimentos excessivos ou ocultando significativamente o rosto com um objeto/mão.’
Na última das testes quantitativos, os autores avaliaram como a adição progressiva de diferentes sinais de distração – olhar fora da tela (via olhar e pose da cabeça), sonolência, fala e telas desatendidas – afetou o desempenho geral de seu modelo de atenção.
Os testes foram realizados em dois conjuntos de dados: o conjunto de dados de distração real e um subconjunto de teste do conjunto de dados de olhar. Foram usados os scores G-mean e F1 para medir o desempenho (embora sonolência e fala tenham sido excluídos da análise no conjunto de dados de olhar, devido à sua relevância limitada neste contexto).
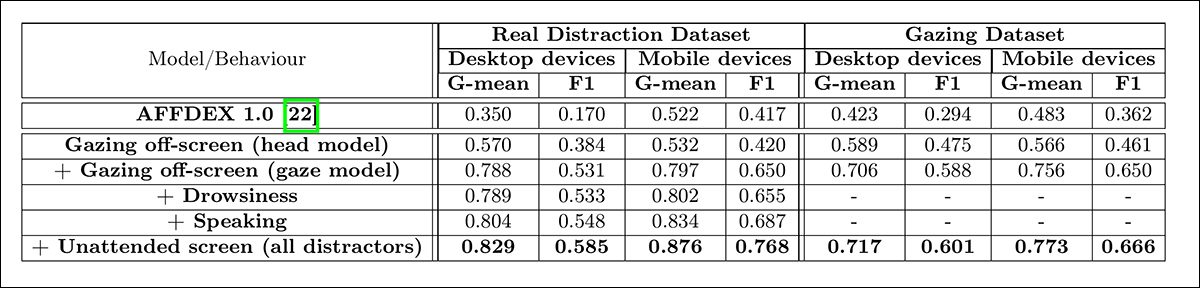
O efeito de adicionar diversos sinais de distração à arquitetura.
Dos resultados, o artigo afirma:
‘A partir dos resultados, podemos primeiro concluir que a integração de todos os sinais de distração contribui para uma melhor detecção de atenção.
‘Em segundo lugar, a melhoria na detecção de atenção é consistente em ambos os dispositivos desktop e mobile. Em terceiro lugar, as sessões móveis no conjunto de dados real mostram movimentos de cabeça significativos ao olhar para longe, que são facilmente detectados, levando a um desempenho melhor para dispositivos móveis em comparação com desktops. Quarto, a inclusão do sinal de sonolência traz melhora relativamente pequena se comparada a outros sinais, uma vez que geralmente é raro acontecer.
‘Por fim, o sinal de tela desatendida tem uma melhoria relativamente maior em dispositivos móveis em comparação com desktops, uma vez que dispositivos móveis podem ser facilmente deixados sem supervisão.’
Os autores também compararam seu modelo ao AFFDEX 1.0, um sistema anterior usado em testes de anúncios – e até mesmo a detecção baseada na cabeça do modelo atual superou o AFFDEX 1.0 em ambos os tipos de dispositivos:
‘Essa melhoria é um resultado da incorporação de movimentos da cabeça nas direções de yaw e pitch, bem como da normalização da pose da cabeça para levar em conta pequenas mudanças. Os pronunciados movimentos da cabeça no conjunto de dados móvel real fizeram com que nosso modelo de cabeça apresentasse desempenho semelhante ao AFFDEX 1.0.’
Os autores encerram o artigo com uma (talvez algo perfunctória) rodada de teste qualitativa, mostrada abaixo.

Saídas de exemplo do modelo de atenção em dispositivos desktop e móveis, com cada linha apresentando exemplos de verdadeiros e falsos positivos para diferentes tipos de distrações.
Os autores afirmam:
‘Os resultados indicam que nosso modelo detecta efetivamente vários distraidores em configurações descontroladas. No entanto, pode ocasionalmente produzir falsos positivos em certos casos extremos, como inclinando severamente a cabeça enquanto mantém o olhar na tela, algumas oclusões labiais, olhos excessivamente borrados ou imagens faciais muito obscurecidas. ‘
Conclusão
Embora os resultados representem um avanço medido, mas significativo, em relação ao trabalho anterior, o valor mais profundo do estudo reside na visão que ele oferece sobre a busca constante de acessar o estado interno do espectador. Embora os dados tenham sido coletados com consentimento, a metodologia aponta para estruturas futuras que poderiam se estender além de configurações estruturadas de pesquisa de mercado.
Esta conclusão algo paranóica é apenas reforçada pela natureza claustrofóbica, contida e zelosa dessa linha específica de pesquisa.
* Minha conversão das citações em linha dos autores em hyperlinks.
Publicado pela primeira vez na quarta-feira, 9 de abril de 2025

Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…