


Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA líder do setor. Saiba Mais
Pesquisadores da Together AI e da Agentica lançaram o DeepCoder-14B, um novo modelo de codificação que entrega um desempenho impressionante comparável a modelos proprietários líderes como o o3-mini da OpenAI.
Construído sobre o DeepSeek-R1, este modelo oferece mais flexibilidade para integrar capacidades de geração de código e raciocínio de alta performance em aplicações do mundo real. É importante ressaltar que as equipes tornaram o modelo, seus dados de treinamento, código, logs e otimizações do sistema totalmente de código aberto, o que pode ajudar os pesquisadores a melhorar seu trabalho e acelerar o progresso.
Capacidades de codificação competitiva em um pacote menor
Os experimentos da equipe de pesquisa mostram que o DeepCoder-14B se destaca em vários benchmarks de codificação desafiadores, incluindo LiveCodeBench (LCB), Codeforces e HumanEval+.
“Nosso modelo demonstra um desempenho forte em todos os benchmarks de codificação… comparável ao desempenho do o3-mini (baixo) e o1,” escrevem os pesquisadores em um post no blog que descreve o modelo.
Curiosamente, apesar de ter sido treinado principalmente em tarefas de codificação, o modelo apresenta uma melhora no raciocínio matemático, marcando 73,8% no benchmark AIME 2024, uma melhoria de 4,1% em relação ao seu modelo base (DeepSeek-R1-Distill-Qwen-14B). Isso sugere que as habilidades de raciocínio desenvolvidas através do RL em código podem ser generalizadas efetivamente para outros domínios.
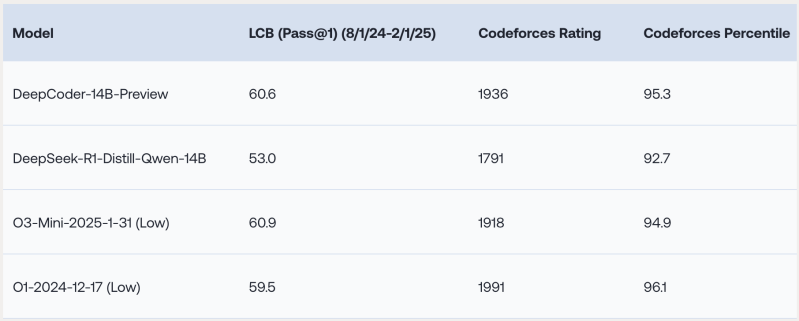
O aspecto mais impressionante é alcançar esse nível de desempenho com apenas 14 bilhões de parâmetros. Isso torna o DeepCoder significativamente menor e potencialmente mais eficiente de executar do que muitos modelos de fronteira.
Inovações que impulsionam o desempenho do DeepCoder
Durante o desenvolvimento do modelo, os pesquisadores resolveram alguns dos principais desafios no treinamento de modelos de codificação usando aprendizado por reforço (RL).
O primeiro desafio foi a curadoria dos dados de treinamento. O aprendizado por reforço exige sinais de recompensa confiáveis que indiquem que a saída do modelo está correta. Como os pesquisadores apontam, “Ao contrário da matemática—onde dados de alta qualidade e verificáveis estão amplamente disponíveis na Internet—o domínio da codificação sofre de uma relativa escassez desses dados.”
Para abordar esse problema, a equipe do DeepCoder implementou um pipeline rigoroso que coleta exemplos de diferentes conjuntos de dados e filtra-os quanto à validade, complexidade e duplicação. Esse processo resultou em 24.000 problemas de alta qualidade, fornecendo uma base sólida para um treinamento eficaz de RL.
A equipe também projetou uma função de recompensa simples que só fornece um sinal positivo se o código gerado passar todos os testes unitários amostrados para o problema dentro de um limite de tempo específico. Combinado com os exemplos de treinamento de alta qualidade, esse sistema de recompensa focado nos resultados impede que o modelo aprenda truques, como imprimir respostas memorizadas para testes públicos ou otimizar para casos simples sem resolver o problema central.
O algoritmo de treinamento central do modelo é baseado na Otimização de Política Relativa em Grupo (GRPO), um algoritmo de aprendizado por reforço que se mostrou muito bem-sucedido no DeepSeek-R1. No entanto, a equipe fez várias modificações no algoritmo para torná-lo mais estável e permitir que o modelo continue a melhorar à medida que o treinamento se estende por mais tempo.
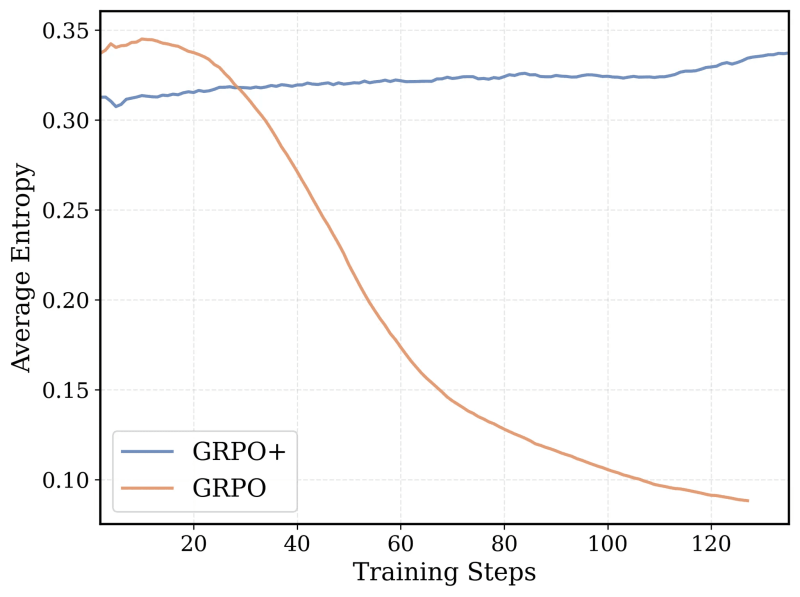
Por fim, a equipe estendeu iterativamente a janela de contexto do modelo, treinando-o primeiro em sequências de raciocínio mais curtas e aumentando gradualmente o comprimento. Eles também desenvolveram um método de filtragem para evitar penalizar o modelo quando ele criava cadeias de raciocínio que excediam os limites de contexto ao resolver um prompt difícil.
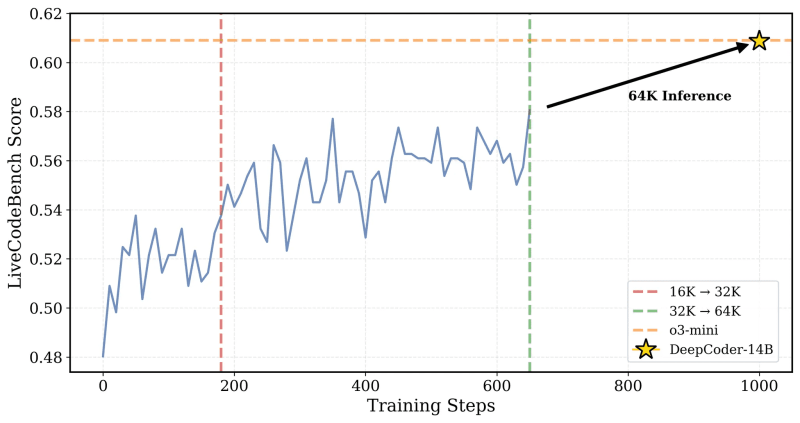
Os pesquisadores explicam a ideia central: “Para preservar o raciocínio de longo contexto enquanto permite um treinamento eficiente, incorporamos a filtragem de longos… Essa técnica mascara sequências truncadas durante o treinamento para que os modelos não sejam penalizados por gerar saídas reflexivas, mas longas, que excedam o limite atual de contexto.”
O treinamento foi gradualmente escalonado de uma janela de contexto de 16K para 32K, e o modelo resultante conseguiu resolver problemas que exigiam até 64K tokens.
Otimizando o treinamento RL de longo contexto
Treinar grandes modelos com RL, especialmente em tarefas que requerem sequências geradas longas, como codificação ou raciocínio complexo, é computacionalmente intensivo e lento. Um grande gargalo é a etapa de “amostragem”, onde o modelo gera potencialmente milhares de tokens por exemplo no lote. Variações no comprimento da resposta significam que algumas respostas terminam muito mais tarde que outras, deixando GPUs ociosas e desacelerando todo o ciclo de treinamento.
Para acelerar isso, a equipe desenvolveu o verl-pipeline, uma extensão otimizada da biblioteca de código aberto verl para aprendizado por reforço a partir de feedback humano (RLHF). A inovação chave, que eles chamam de “Pipelining de Uma Só Vez”, reorganiza a amostragem de resposta e as atualizações de modelo para reduzir os gargalos e o tempo ocioso do acelerador.
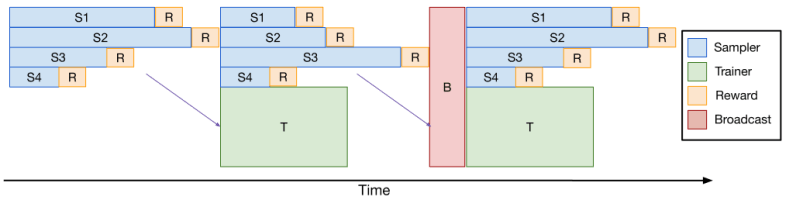
Os experimentos mostraram que o pipelining de uma só vez proporcionou um aumento de até 2x na velocidade para tarefas de RL de codificação em comparação com implementações padrão. Essa otimização foi crucial para treinar o DeepCoder dentro de um prazo razoável (2,5 semanas em 32 H100s) e agora está open-sourced como parte do verl-pipeline para a comunidade usar e construir sobre.
Impacto no setor
Os pesquisadores disponibilizaram todos os artefatos para treinar e executar o DeepCoder-14B no GitHub e no Hugging Face sob uma licença permissiva.
“Ao compartilhar completamente nosso conjunto de dados, código e receita de treinamento, capacitamos a comunidade a reproduzir nosso trabalho e tornar o treinamento de RL acessível a todos,” afirmam os pesquisadores.
O DeepCoder-14B ilustra poderosamente uma tendência mais ampla e acelerada no cenário da IA: a ascensão de modelos altamente capazes, mas eficientes e abertamente acessíveis.
No mundo empresarial, essa mudança significa mais opções e maior acessibilidade de modelos avançados. O desempenho de ponta não é mais apenas domínio de hiperscaladores ou daqueles dispostos a pagar taxas altas de API. Modelos como o DeepCoder podem capacitar organizações de todos os tamanhos a aproveitar a geração de código e raciocínio sofisticados, personalizar soluções para suas necessidades específicas e implantá-las com segurança em seus ambientes.
Essa tendência pode diminuir a barreira de entrada para a adoção de IA e fomentar um ecossistema mais competitivo e inovador, onde o progresso é impulsionado pela colaboração de código aberto.


Conteúdo relacionado

FLUX.1 Kontext permite a geração de imagens em contexto para pipelines de IA empresarial.
[the_ad id="145565"] Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba Mais…

Elon se afasta do DOGE e o Vale do Silício entra na fase de ‘descoberta’
[the_ad id="145565"] Elon Musk anunciou oficialmente que está se afastando como um funcionário especial do governo dos EUA e o chefe de fato do Departamento de Eficiência…

Startup de IA com voz emotiva Hume lança novo modelo EVI 3 com criação rápida de vozes personalizadas.
[the_ad id="145565"] Inscreva-se em nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre coberturas líderes da indústria em IA. Saiba…