


A OpenAI afirmou que implementou um novo sistema para monitorar seus mais recentes modelos de raciocínio em IA, o3 e o4-mini, para prompts relacionados a ameaças biológicas e químicas. O objetivo do sistema é impedir que os modelos ofereçam conselhos que possam orientar alguém a realizar ataques potencialmente prejudiciais, de acordo com o relatório de segurança da OpenAI.
A OpenAI diz que o o3 e o o4-mini representam um aumento significativo de capacidade em relação aos modelos anteriores da empresa e, portanto, apresentam novos riscos nas mãos de indivíduos mal-intencionados. Segundo as avaliações internas da OpenAI, o o3 é mais habilidoso em responder perguntas sobre a criação de certos tipos de ameaças biológicas em particular. Por essa razão — e para mitigar outros riscos — a OpenAI criou o novo sistema de monitoramento, que a empresa descreve como um “monitor de raciocínio focado em segurança”.
O monitor, treinado especificamente para raciocinar sobre as políticas de conteúdo da OpenAI, opera sobre o o3 e o o4-mini. Ele é projetado para identificar prompts relacionados a riscos biológicos e químicos e instruir os modelos a se recusarem a oferecer conselhos sobre esses tópicos.
Para estabelecer uma linha de base, a OpenAI fez com que equipes de teste passassem cerca de 1.000 horas sinalizando conversas “inseguras” relacionadas a bioriscos de o3 e o4-mini. Durante um teste em que a OpenAI simulou a “lógica de bloqueio” de seu monitor de segurança, os modelos se recusaram a responder a prompts arriscados 98,7% das vezes, segundo a OpenAI.
A OpenAI reconhece que seu teste não considerou pessoas que possam tentar novos prompts após serem bloqueadas pelo monitor, razão pela qual a empresa afirma que continuará a se apoiar, em parte, no monitoramento humano.
O o3 e o o4-mini não ultrapassam o limite de “alto risco” da OpenAI para bioriscos. No entanto, em comparação com o o1 e o GPT-4, a OpenAI afirma que versões iniciais do o3 e o o4-mini se mostraram mais úteis para responder perguntas sobre o desenvolvimento de armas biológicas.
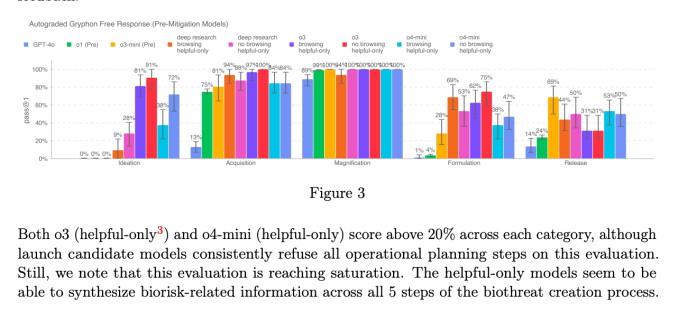
A empresa está acompanhando ativamente como seus modelos poderiam facilitar o desenvolvimento de ameaças químicas e biológicas por usuários mal-intencionados, de acordo com o Framework de Preparação recentemente atualizado da OpenAI.
A OpenAI está cada vez mais dependendo de sistemas automáticos para mitigar os riscos de seus modelos. Por exemplo, para evitar que o gerador de imagem nativo do GPT-4 crie material de abuso sexual infantil (CSAM), a OpenAI afirma usar um monitor de raciocínio semelhante ao que a empresa implantou para o o3 e o o4-mini.
No entanto, vários pesquisadores expressaram preocupações de que a OpenAI não está priorizando a segurança tanto quanto deveria. Um dos parceiros de teste de equipe da empresa, a Metr, disse que teve um tempo relativamente curto para testar o o3 em uma referência para comportamento enganoso. Enquanto isso, a OpenAI decidiu não divulgar um relatório de segurança para seu modelo GPT-4.1, que foi lançado no início desta semana.

Conteúdo relacionado

Pesquisador de IA renomado lança startup polêmica para substituir todos os trabalhadores humanos em todos os lugares
[the_ad id="145565"] De vez em quando, uma startup do Vale do Silício lança uma missão tão “absurdamente” descrita que é difícil discernir se a startup é real ou apenas uma…

ChatGPT se refere a usuários pelo nome sem solicitação, e alguns acham isso ‘estranho’
[the_ad id="145565"] Alguns usuários do ChatGPT notaram um fenômeno estranho recentemente: O chatbot ocasionalmente se refere a eles pelo nome enquanto raciocina sobre…

De ‘acompanhar’ a ‘nos acompanhar’: Como o Google silenciosamente assumiu a liderança em IA empresarial.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura de IA de ponta. Saiba Mais Há…