


Uma visão comum na pesquisa atual em aprendizado de máquina é que o próprio aprendizado de máquina pode ser usado para melhorar a qualidade das anotações de conjuntos de dados de IA – particularmente as legendas de imagens destinadas ao uso em modelos de linguagem e visão (VLMs). Essa linha de pensamento é impulsionada pelo alto custo da anotação humana e pela carga adicional de supervisionar o desempenho dos anotadores.
Pode-se argumentar que isso é o equivalente em IA ao meme de “baixar mais RAM” no início dos anos 2000, que satirizava a noção de que uma limitação de hardware poderia ser resolvida com uma correção baseada em software.
É também uma questão pouco reconhecida; enquanto novos modelos de IA atraem ampla atenção tanto no público quanto na esfera comercial, a anotação muitas vezes parece ser um detalhe trivial nos pipelines de aprendizado de máquina, ofuscada pela empolgação em torno de estruturas mais amplas.
Na verdade, a capacidade dos sistemas de aprendizado de máquina para reconhecer e reproduzir padrões (o caso de uso central de quase todos os sistemas de IA) depende da qualidade e consistência das anotações do mundo real – rótulos e frases que são criados ou adjudicados por pessoas reais, frequentemente fazendo julgamentos subjetivos sobre pontos de dados individuais em circunstâncias não ideais.
Inevitavelmente, sistemas que buscam observar e reproduzir padrões no comportamento dos anotadores (e, por consequência, substituir anotadores humanos e facilitar a rotulagem precisa em escala) não podem esperar um bom desempenho em dados não contidos nos exemplos retirados de observadores humanos. Nada ‘semelhante’ é verdadeiramente igual, e a equivalência entre domínios continua a ser uma busca problemática na visão computacional.
O “block de dados upstream” tem que parar em algum lugar, e neste caso, é exatamente onde para – com um cerebelo humano fazendo algum tipo de distinção subjetiva para codificar dados para um sistema artificial.
O Comércio de RAG
Até recentemente, as imprecisões decorrentes de anotações de conjuntos de dados mal curadas eram vistas como danos colaterais aceitáveis no contexto dos resultados imperfeitos, mas ainda comercializáveis, obtidos a partir de sistemas de IA generativa.
De fato, apenas este ano, um estudo de Cingapura concluiu que as alucinações – ou seja, as ocasiões em que sistemas de IA inventam coisas que comprometem nossas intenções – são inevitáveis e estão entrelaçadas com a arquitetura conceitual de tais sistemas.
Para contornar isso, os agentes baseados em RAG – que podem ‘verificar’ fatos através de buscas na internet – estão se tornando populares em soluções comerciais aplicadas e na pesquisa. No entanto, eles aumentam o custo de recursos e a latência nas consultas; além disso, informações novas aplicadas a um modelo treinado não podem competir com as conexões mais intrincadas e profundamente entrelaçadas que caracterizam as camadas nativas em um modelo treinado.
Seria, portanto, melhor que os dados de anotação que informam esses modelos fossem significativamente menos defeituosos em primeiro lugar, mesmo que não possam ser perfeitos (não least because this activity encroaches into the realm of human subjectivity).
RePOPE
Um novo artigo da Alemanha destaca os problemas que surgem da dependência de conjuntos de dados mais antigos e amplamente utilizados, concentrando-se particularmente na precisão e confiabilidade de suas legendas de imagem. As descobertas dos pesquisadores sugerem que erros de rotulagem em benchmarks podem mascarar ou distorcer alucinações em modelos de linguagem e visão.

Do novo artigo, alguns exemplos onde as legendas originais falharam em identificar corretamente objetos no conjunto de dados de imagens MSCOCO. A revisão manual do conjunto de dados benchmark POPE pelos pesquisadores aborda essas deficiências, demonstrando o custo de economizar dinheiro na curadoria de anotações. Fonte: https://arxiv.org/pdf/2504.15707
Imagine que um modelo é mostrado uma imagem de uma cena de rua e perguntado se há uma bicicleta nela. O modelo responde sim. Se o conjunto de dados de benchmark diz que não há bicicleta, o modelo é considerado errado. Mas se uma bicicleta está claramente visível na imagem e foi simplesmente perdida durante a anotação, então a resposta do modelo estava correta, e o benchmark falhou. Erros como esse podem se acumular ao longo de um conjunto de dados, dando uma imagem distorcida de quais modelos são precisos e quais são propensos à alucinação.
Assim, quando anotações incorretas ou ambíguas são tratadas como verdadeiros de referência, os modelos podem parecer alucinar quando estão corretos, ou parecer precisos quando não estão, distorcendo tanto a medição da alucinação quanto a classificação do desempenho do modelo, dificultando o diagnóstico ou a resolução do problema com certeza.
O novo artigo revisita um benchmark amplamente utilizado chamado Avaliação de Probing de Objetos Baseada em Pesquisa (POPE), que testa se modelos de linguagem e visão podem dizer corretamente o que há ou não em uma imagem.
O POPE é baseado em rótulos do influente Microsoft COCO: Objetos Comuns em Contexto (MSCOCO), uma coleção de imagens anotadas que há muito tempo é considerada como oferecendo um bom nível de precisão nas anotações.
O POPE avalia a alucinação de objetos em grandes modelos de linguagem e visão, reformulando o problema como uma tarefa de classificação binária. Em vez de analisar as legendas geradas, o sistema faz perguntas simples sim/não ao modelo sobre se objetos específicos estão presentes em uma imagem, usando modelos como ‘Há um .
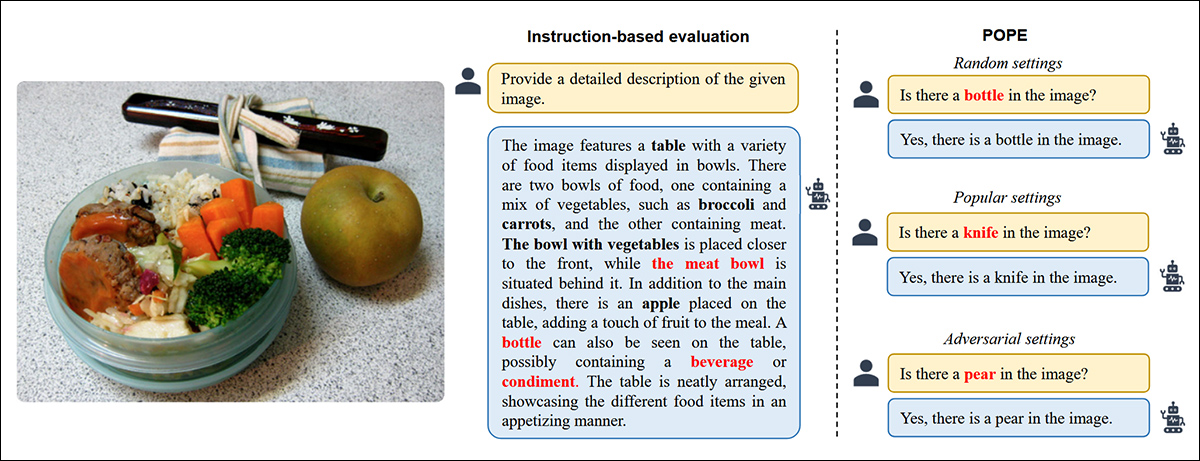
Exemplos de alucinação de objetos em modelos de linguagem e visão. Rótulos em negrito indicam objetos marcados como presentes nas anotações originais, enquanto rótulos vermelhos mostram objetos alucinado pelos modelos. O exemplo à esquerda reflete uma avaliação tradicional baseada em instruções, enquanto os três exemplos à direita são retirados de diferentes variantes do benchmark POPE. Fonte: https://aclanthology.org/2023.emnlp-main.20.pdf
Objetos verdadeiros (resposta: Sim) são emparelhados com objetos não existentes amostrados (resposta: Não), escolhidos através de estratégias de amostragem aleatória, frequente (popular), ou com base em coocorrência (adversarial). Essa configuração permite uma avaliação mais estável e insensível a prompts da alucinação sem depender de uma análise de legenda complexa baseada em regras.
Os autores do novo artigo – intitulado RePOPE: Impacto de Erros de Anotação no Benchmark POPE – desafiam a precisão assumida do POPE ao reavaliar os rótulos das imagens do benchmark (ou seja, MSCOCO) – e constatam que um número surpreendente está errado ou indefinido.

Exemplos do conjunto de dados MSCOCO de 2014. Fonte: https://arxiv.org/pdf/1405.0312
Esses erros mudam a maneira como os modelos são classificados, com alguns que inicialmente se saíram bem caindo por trás quando avaliados em relação aos rótulos corrigidos.
Em testes, os autores avaliaram uma gama de modelos de linguagem e visão de peso aberto tanto no benchmark original POPE quanto na sua versão reanotada RePOPE.
De acordo com o artigo, as anotações corrigidas levaram a mudanças notáveis nas classificações dos modelos, particularmente nas pontuações de F1, com vários modelos de alto desempenho sob o POPE caindo em posição sob o RePOPE.
Os autores sustentam que essa mudança ilustra a extensão em que os erros de anotação podem obscurecer o comportamento real de alucinação dos modelos e apresentam o RePOPE como uma ferramenta mais confiável para avaliar a vulnerabilidade à alucinação.

Em outro exemplo do novo artigo, vemos como as legendas do POPE original falham em discernir objetos sutis, como uma pessoa sentada ao lado da cabine de um bonde na foto mais à direita, ou a cadeira obscurecida pelo jogador de tênis na segunda foto da esquerda.
Método e Testes
Os pesquisadores reanotaram todas as anotações no conjunto de dados original do MSCOCO, com dois anotadores humanos designados para cada instância de dados. Onde surgiu ambiguidade quanto à qualidade dos rótulos originais (como nos exemplos abaixo), esses resultados foram deixados de fora da rodada de testes.

Casos ambíguos, onde as inconsistências de rotulagem no POPE refletem limites de categoria pouco claros. Por exemplo, um urso de pelúcia rotulado como um urso, uma motocicleta como uma bicicleta, ou veículos de aeroporto como carros. Esses casos foram excluídos do RePOPE devido à natureza subjetiva de tais classificações, bem como às inconsistências nos rótulos originais do MSCOCO.
O artigo afirma:
‘Os anotações originais perderam pessoas no fundo ou atrás do vidro, o jogador de tênis oculta as ‘cadeiras’ no fundo e a salada de repolho contém apenas uma pequena tira visível de cenoura.
‘Para alguns objetos, as anotações do COCO são altamente inconsistentes, provavelmente devido a definições diferentes desses objetos usadas pelos anotadores originais. A classificação de um ‘urso de pelúcia’ como um ‘urso’, uma motocicleta como uma ‘bicicleta’ motorizada ou um veículo de aeroporto como um ‘carro’ depende de definições específicas, levando a inconsistências nas anotações verdadeiras do POPE. Portanto, anotamos os pares de imagem-pergunta correspondentes como ‘ambíguos’.’
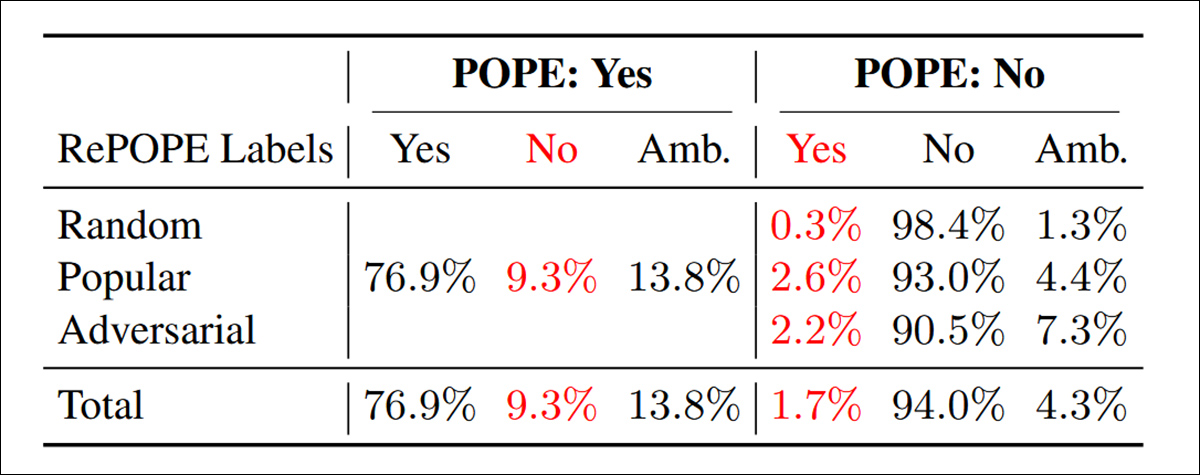
Resultados da reanotação: as perguntas positivas são compartilhadas entre todas as três variantes do POPE. Entre aqueles rotulados ‘Sim’ no POPE, 9,3 por cento foram considerados incorretos e 13,8 por cento foram classificados como ambíguos. Para as perguntas ‘Não’, 1,7 por cento estavam rotulados de forma errada e 4,3 por cento eram ambíguos.
Os autores avaliaram uma gama de modelos de linguagem e visão de peso aberto no POPE e no RePOPE, abrangendo diversas arquiteturas e tamanhos de modelos. Os modelos escolhidos incluíram algumas das principais arquiteturas no ranking OpenVLM: InternVL2.5 (8B/26B/38B/78B e 8B-MPO/26B-MPO); LLaVA-NeXT; Vicuna; Mistral 7b; Llama; LLaVA-OneVision; Ovis2 (1B/2B/4B/8B); PaliGemma-3B; e PaliGemma2 (3B/10B).
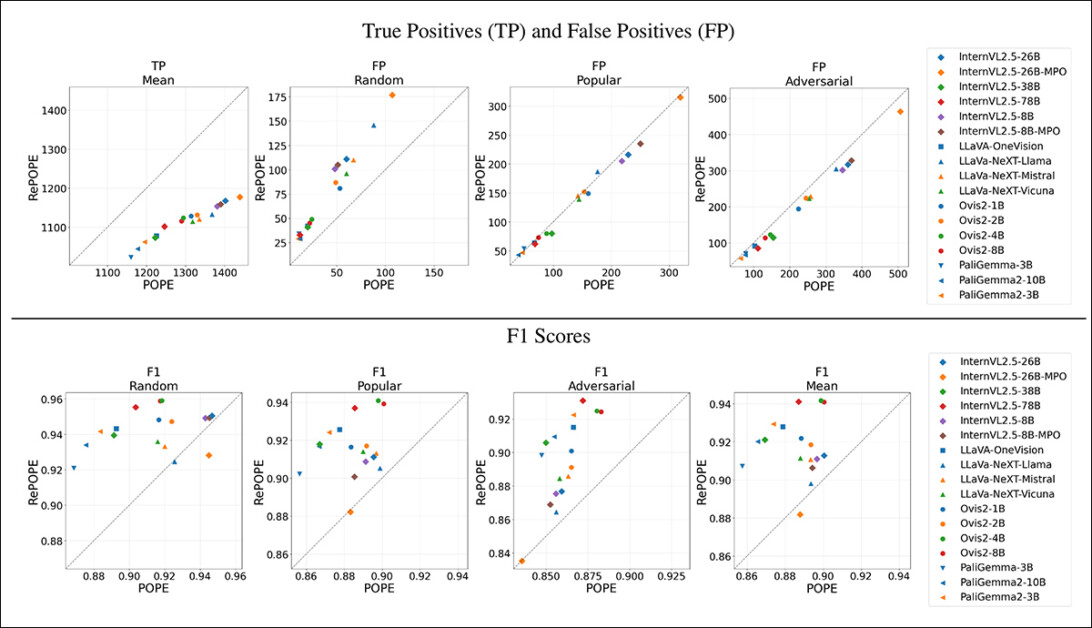
Resultados iniciais: a alta taxa de erro nos rótulos positivos originais leva a uma queda acentuada nos verdadeiros positivos em todos os modelos. Os falsos positivos variam entre os subconjuntos, quase dobrando no subconjunto aleatório, mas permanecendo em grande parte inalterados no subconjunto popular, e mostrando uma leve diminuição no subconjunto adversarial. A reanotação tem um grande efeito nas classificações baseadas em F1. Modelos como Ovis2-4B e Ovis2-8B, que se saíram bem nas divisões populares e adversariais no POPE, também sobem para o topo no subconjunto aleatório sob RePOPE. Consulte o PDF para melhor resolução.
Os gráficos de resultados acima ilustram como o número de verdadeiros positivos e falsos positivos muda após a correção dos rótulos no benchmark.
Os verdadeiros positivos caíram em todos os modelos, mostrando que muitas vezes eram creditados com respostas corretas quando essas respostas eram apenas corretas sob rótulos defeituosos, enquanto os falsos positivos seguiram um padrão mais variado.
No ‘subconjunto aleatório’ do POPE, os falsos positivos quase dobraram para muitos modelos, indicando que um número significativo de objetos marcados como alucinações estavam, na verdade, presentes nas imagens, mas tinham sido perdidos nas anotações originais. Nesse caso, muitos supostos erros do modelo eram, de fato, erros de rotulagem do conjunto de dados.
Para a versão ‘adversarial’ do POPE, onde as perguntas eram baseadas em objetos que frequentemente co-ocorrem, os falsos positivos diminuíram. Isso provavelmente reflete uma chance maior de que o objeto supostamente ausente estivesse realmente na imagem mas deixado não rotulado.
Embora essas mudanças tenham afetado a precisão e a recuperação, as classificações dos modelos permaneceram relativamente estáveis para ambas as métricas.
A pontuação F1 – a principal medida de avaliação do POPE – foi muito mais sensível às correções de rótulos. No subconjunto aleatório, modelos que estavam perto do topo sob os rótulos originais, como InternVL2.5-8B e -26B, caíram para o fundo quando avaliados com o RePOPE. Outros, como Ovis2-4B e -8B, subiram para o topo.
Um padrão semelhante emergiu nas pontuações de precisão, embora os autores observem que agora essas possam estar enviesadas, pois o conjunto de dados corrigido contém um número desigual de exemplos positivos e negativos.
Os autores argumentam que o forte impacto dos erros de anotação nos resultados dos benchmarks enfatiza a necessidade de dados de alta qualidade. Para apoiar a avaliação mais confiável da alucinação de objetos, eles lançaram os rótulos corrigidos no GitHub.
No entanto, eles observam que essa reanotação não resolve completamente a saturação do benchmark, uma vez que muitos modelos ainda alcançam taxas de verdadeiros positivos e verdadeiros negativos acima de 90%. Eles sugerem que benchmarks adicionais, como DASH-B, que utiliza um conjunto mais desafiador de exemplos negativos, devem ser usados juntamente com o RePOPE.
Conclusão
Este experimento particular foi possível devido à pequena escala do conjunto de dados envolvido. Provar a mesma hipótese em conjuntos de dados de hiperscale envolveria trabalhar com fragmentos muito limitados dos dados; em conjuntos de dados grandes e altamente diversos, pode se tornar quase impossível isolar agrupamentos estatisticamente representativos e semanticamente coerentes – o que pode distorcer os resultados.
Mesmo que fosse possível, que remédio haveria sob o estado atual da arte? O argumento inevitavelmente se volta para a necessidade de uma melhor e mais copiosa anotação humana.
Neste aspecto, ‘melhor’ e ‘mais copiosa’ existem como problemas separados por direito próprio, uma vez que é possível obter um maior volume de anotações por meio de economias de corrida para o fundo, como o Amazon Mechanical Turk (AMT). Obviamente, essa subeconomia potencialmente exploradora leva frequentemente a resultados inferiores.
Alternativamente, pode-se terceirizar tarefas de anotação para regiões econômicas onde o mesmo gasto proporcionaria uma maior quantidade de anotações. No entanto, quanto mais afastado o anotador estiver do caso de uso pretendido do modelo cujos rótulos moldarão, menos provável é que o modelo resultante alinhe-se com as necessidades ou expectativas do domínio alvo.
Portanto, essa continua a ser um dos desafios mais persistentes e não resolvidos na economia do desenvolvimento de aprendizado de máquina.
Publicado pela primeira vez na quarta-feira, 23 de abril de 2025

Conteúdo relacionado

Duolingo lança 148 cursos criados com IA após anunciar planos de substituir contratados por IA
[the_ad id="145565"] Duolingo está lançando 148 novos cursos de idiomas criados com inteligência artificial generativa, a empresa anunciou na quarta-feira. O lançamento…

Anthropic sugere ajustes nas propostas de controles de exportação de chips de IA nos EUA
[the_ad id="145565"] A Anthropic concorda com o governo dos EUA que a implementação de controles de exportação robustos para chips de IA fabricados domesticamente ajudará os…

JetBrains lança o Mellum, um modelo de IA de codificação ‘aberto’
[the_ad id="145565"] A JetBrains, a empresa por trás de uma variedade de ferramentas populares para desenvolvimento de aplicativos, lançou seu primeiro modelo de IA “aberto”…