


Participe de nossos boletins diários e semanais para obter as últimas atualizações e conteúdo exclusivo sobre inteligência artificial de ponta. Saiba mais
A Liquid AI, uma startup de modelos de fundação com sede em Boston, originada no Instituto de Tecnologia de Massachusetts (MIT), busca levar a indústria da tecnologia além da dependência da arquitetura Transformer que fundamenta a maioria dos modelos de linguagem de larga escala (LLMs) populares, como a série GPT da OpenAI e a família Gemini do Google.
Ontem, a empresa anunciou “Hyena Edge”, um novo modelo multi-híbrido baseado em convoluções, projetado para smartphones e outros dispositivos de borda, antes da Conferência Internacional sobre Aprendizagem de Representações (ICLR) de 2025.
A conferência, um dos principais eventos de pesquisa em aprendizado de máquina, ocorrerá este ano em Singapura.
Novo modelo baseado em convoluções promete IA mais rápida e eficiente em termos de memória na borda
Hyena Edge é projetado para superar modelos de referência Transformer em eficiência computacional e qualidade do modelo de linguagem.
Em testes do mundo real em um smartphone Samsung Galaxy S24 Ultra, o modelo demonstrou menor latência, menor uso de memória e melhores resultados de benchmark em comparação com um modelo Transformer++ com parâmetros equivalentes.
Uma nova arquitetura para uma nova era da IA na borda
Diferentemente da maioria dos pequenos modelos projetados para implementação em dispositivos móveis — incluindo SmolLM2, os modelos Phi e Llama 3.2 1B — o Hyena Edge se distancia dos designs tradicionais centrados em atenção. Em vez disso, ele substitui estrategicamente dois terços dos operadores de atenção agrupada (GQA) por convoluções controladas da família Hyena-Y.
A nova arquitetura é resultado do framework Synthesis of Tailored Architectures (STAR) da Liquid AI, que utiliza algoritmos evolutivos para projetar automaticamente estruturas de modelos e foi anunciado em dezembro de 2024.
STAR explora uma ampla gama de composições de operadores, fundamentadas na teoria matemática de sistemas lineares variáveis em função da entrada, para otimizar múltiplos objetivos específicos de hardware, como latência, uso de memória e qualidade.
Benchmark direto em hardware de consumo
Para validar a prontidão real do Hyena Edge, a Liquid AI realizou testes diretamente no smartphone Samsung Galaxy S24 Ultra.
Os resultados mostraram que o Hyena Edge alcançou até 30% de latências de pré-filling e decodificação mais rápidas em comparação com seu contraparte Transformer++, com vantagens de velocidade aumentando em comprimentos de sequência mais longos.
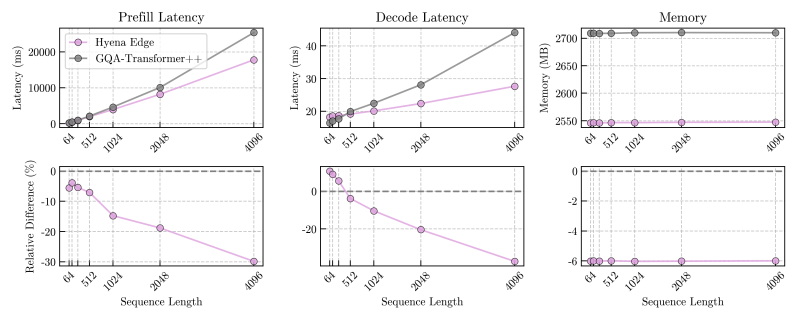
As latências de pré-filling em comprimentos de sequência curtos também superaram a linha de base do Transformer — uma métrica de desempenho crítica para aplicações responsivas em dispositivos.
Em termos de memória, o Hyena Edge utilizou consistentemente menos RAM durante a inferência em todos os comprimentos de sequência testados, posicionando-o como um forte candidato para ambientes com limitações de recursos.
Superando Transformers em benchmarks de linguagem
Hyena Edge foi treinado com 100 bilhões de tokens e avaliado em benchmarks padrão para pequenos modelos de linguagem, incluindo Wikitext, Lambada, PiQA, HellaSwag, Winogrande, ARC-fácil e ARC-desafio.
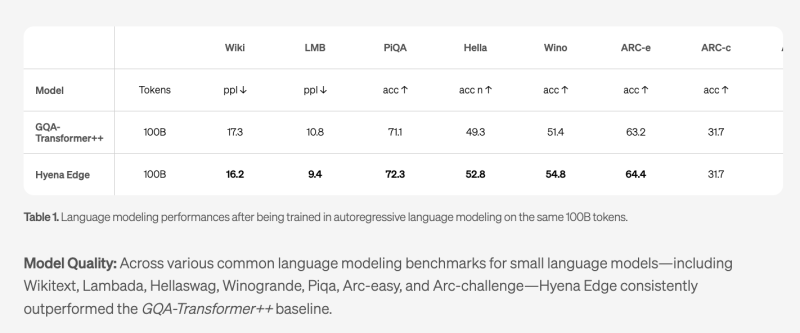
Em todos os benchmarks, o Hyena Edge igualou ou superou o desempenho do modelo GQA-Transformer++, com melhorias notáveis nos pontuações de perplexidade em Wikitext e Lambada, e taxas de precisão mais altas em PiQA, HellaSwag e Winogrande.
Esses resultados sugerem que os ganhos de eficiência do modelo não vêm à custa da qualidade preditiva — uma troca comum para muitas arquiteturas otimizadas para a borda.
Evolução do Hyena Edge: Um olhar sobre tendências de desempenho e operadores
Para aqueles que buscam uma análise mais aprofundada do processo de desenvolvimento do Hyena Edge, um recente vídeo explicativo oferece um resumo visual convincente da evolução do modelo.
O vídeo destaca como métricas-chave de desempenho — incluindo latência de pré-filling, latência de decodificação e consumo de memória — melhoraram ao longo de gerações sucessivas de refinamento arquitetônico.
Ele também oferece uma rara visão dos bastidores de como a composição interna do Hyena Edge mudou durante o desenvolvimento. Os espectadores podem observar mudanças dinâmicas na distribuição de tipos de operadores, como mecanismos de Auto-Atenção (SA), várias variantes de Hyena e camadas SwiGLU.
Essas mudanças oferecem insights sobre os princípios de design arquitetônico que ajudaram o modelo a alcançar seu nível atual de eficiência e precisão.
Ao visualizar as trocas e dinâmicas de operadores ao longo do tempo, o vídeo fornece um contexto valioso para compreender as inovações arquitetônicas que fundamentam o desempenho do Hyena Edge.
Planos de código aberto e uma visão mais ampla
A Liquid AI afirmou que planeja disponibilizar uma série de modelos de fundação Liquid, incluindo o Hyena Edge, nos próximos meses. O objetivo da empresa é construir sistemas de IA gerais capazes e eficientes que possam escalar de centros de dados na nuvem até dispositivos pessoais de borda.
A estreia do Hyena Edge também destaca o crescente potencial de arquiteturas alternativas para desafiar os Transformers em configurações práticas. Com dispositivos móveis cada vez mais exigindo executar cargas de trabalho científicas complexas nativamente, modelos como o Hyena Edge podem estabelecer um novo padrão para o que a IA otimizada para a borda pode alcançar.
O sucesso do Hyena Edge — tanto em métricas de desempenho bruto quanto em demonstrar design de arquitetura automatizado — posiciona a Liquid AI como um dos emergentes players a serem observados na evolução do cenário de modelos de IA.


Conteúdo relacionado

O Google transfere notícias do Android para um evento virtual antes de sua conferência para desenvolvedores I/O
[the_ad id="145565"] As notícias sobre o Android estão sendo relegadas a um evento secundário na conferência anual de desenvolvedores do Google, Google I/O, no próximo mês. Na…

Corrigindo a Compreensão Limitada de Modelos de Difusão sobre Espelhos e Reflexos
[the_ad id="145565"] Desde que a IA generativa começou a atrair o interesse do público, a área de pesquisa em visão computacional aprofundou seu interesse no desenvolvimento de…

Lightrun capta US$ 70 milhões utilizando IA para depurar código em produção.
[the_ad id="145565"] A programação baseada em IA se popularizou rapidamente, prometendo tornar o trabalho dos desenvolvedores mais ágil e fácil. Contudo, isso também resultou…