


Desde que a IA generativa começou a atrair o interesse do público, a área de pesquisa em visão computacional aprofundou seu interesse no desenvolvimento de modelos de IA capazes de compreender e replicar leis físicas. No entanto, o desafio de ensinar sistemas de aprendizado de máquina a simular fenômenos como gravidade e dinâmica de líquidos tem sido um foco significativo dos esforços de pesquisa nos últimos cinco anos.
Com a ascensão dos modelos de difusão latente (LDMs) que dominaram a cena de IA generativa em 2022, os pesquisadores passaram a se concentrar cada vez mais na capacidade limitada da arquitetura LDM para entender e reproduzir fenômenos físicos. Agora, essa questão ganhou ainda mais destaque com o desenvolvimento marcante do modelo de vídeo gerativo da OpenAI, Sora, e com o lançamento recente e (provavelmente) mais significativo dos modelos de vídeo de código aberto Hunyuan Video e Wan 2.1.
Refletindo Mal
A maior parte da pesquisa voltada para melhorar a compreensão da física nos LDMs focou em áreas como simulação de marcha, física de partículas e outros aspectos do movimento newtoniano. Estas áreas têm atraído atenção porque imprecisões em comportamentos físicos básicos poderiam prejudicar imediatamente a autenticidade do vídeo gerado pela IA.
No entanto, uma pequena, mas crescente, linha de pesquisa concentra-se em uma das maiores fraquezas do LDM – sua incapacidade relativa de produzir reflexões precisas.

Do artigo de janeiro de 2025 ‘Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections’, exemplos de ‘falha de reflexão’ versus a abordagem dos pesquisadores. Fonte: https://arxiv.org/pdf/2409.14677
Esse problema também foi um desafio durante a era de CGI e continua a ser na área de jogos eletrônicos, onde algoritmos de ray tracing simulam o caminho da luz à medida que interage com superfícies. O ray tracing calcula como raios de luz virtuais ricocheteiam ou passam por objetos para criar reflexões, refrações e sombras realistas.
No entanto, como cada novo ricochete aumenta significativamente o custo computacional, aplicações em tempo real precisam equilibrar latência e precisão limitando o número de ricochetes de raios de luz permitidos.
![Uma representação de um feixe de luz virtual calculado em um cenário tradicional 3D (ou seja, CGI), usando tecnologias e princípios desenvolvidos pela primeira vez na década de 1960 e que culminaram entre 1982-93 (período entre Tron [1982] e Jurassic Park [1993]). Fonte: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://11o.info/wp-content/uploads/2025/04/1745854842_258_Corrigindo-a-Compreensao-Limitada-de-Modelos-de-Difusao-sobre-Espelhos.jpg)
Uma representação de um feixe de luz virtual calculado em um cenário tradicional 3D (ou seja, CGI), usando tecnologias e princípios desenvolvidos pela primeira vez na década de 1960 e que culminaram entre 1982-93. Fonte: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Por exemplo, a representação de um bule de cerâmica em frente a um espelho pode envolver um processo de ray tracing onde raios de luz ricocheteiam repetidamente entre superfícies refletivas, criando um quase loop infinito com pouco benefício prático para a imagem final. Na maioria dos casos, uma profundidade de reflexão de dois a três ricochetes já excede o que o espectador pode perceber. Um único ricochete resultaria em um espelho preto, uma vez que a luz deve completar pelo menos duas viagens para formar uma reflexão visível.
Cada ricochete adicional aumenta drasticamente o custo computacional, geralmente dobrando os tempos de renderização, tornando o manejo mais rápido das reflexões uma das oportunidades mais significativas para melhorar a qualidade da renderização baseada em ray tracing.
Naturalmente, as reflexões ocorrem e são essenciais para o fotorrealismo em cenários menos óbvios – como a superfície refletiva de uma rua da cidade ou um campo de batalha após a chuva; a reflexão da rua oposta em uma vitrine ou porta de vidro; ou nos óculos de personagens representados, onde objetos e ambientes podem ser requeridos para aparecer.

Uma simulação de reflexão dupla alcançada por meio de composição tradicional para uma cena icônica em ‘The Matrix’ (1999).
Problemas de Imagem
Por essa razão, frameworks que eram populares antes do advento dos modelos de difusão, como os Campos de Radiação Neural (NeRF), e alguns desafios mais recentes, como o Gaussian Splatting, também enfrentaram dificuldades em executar reflexões de maneira natural.
O projeto REF2-NeRF (mostrado abaixo) propôs um método de modelagem baseado em NeRF para cenas contendo uma vitrine de vidro. Nesse método, a refração e a reflexão foram modeladas usando elementos que dependem e não dependem da perspectiva do observador. Essa abordagem permitiu que os pesquisadores estimassem as superfícies onde a refração ocorria, especificamente superfícies de vidro, e possibilitou a separação e modelagem de componentes de luz direta e refletida.

Exemplos do artigo Ref2Nerf. Fonte: https://arxiv.org/pdf/2311.17116
Outras soluções para reflexões voltadas ao NeRF dos últimos 4-5 anos incluem NeRFReN, Reflecting Reality, e o projeto de 2024 da Meta, Planar Reflection-Aware Neural Radiance Fields projeto.
Para a GSplat, artigos como Mirror-3DGS, Reflective Gaussian Splatting, e RefGaussian ofereceram soluções para o problema da reflexão, enquanto o projeto de 2023 Nero propôs um método exclusivo de incorporação de qualidades reflexivas em representações neurais.
MirrorVerse
Conseguir que um modelo de difusão respeite a lógica de reflexão é indiscutivelmente mais difícil do que com abordagens não semânticas estruturalmente explícitas, como Gaussian Splatting e NeRF. Em modelos de difusão, uma regra desse tipo só pode ser incorporada de forma confiável se os dados de treinamento contiverem muitos exemplos variados em uma ampla gama de cenários, tornando-a altamente dependente da distribuição e qualidade do conjunto de dados original.
Tradicionalmente, adicionar comportamentos específicos desse tipo é uma tarefa para um LoRA ou o ajuste fino do modelo base; mas essas não são soluções ideais, uma vez que um LoRA tende a enviesar a saída para seus próprios dados de treinamento, mesmo sem solicitação, enquanto ajustes finos – além de serem caros – podem desviar um modelo principal irrevogavelmente da corrente principal, gerando uma série de ferramentas customizadas que nunca funcionarão com qualquer outro tipo do modelo, incluindo o original.
Em geral, melhorar os modelos de difusão requer que os dados de treinamento prestem mais atenção à física da reflexão. No entanto, muitas outras áreas também necessitam de semelhante atenção especial. No contexto de conjuntos de dados em grande escala, onde a curadoria customizada é custosa e difícil, abordar todas as fraquezas dessa forma é impraticável.
Embora, soluções para o problema de reflexão do LDM surjam ocasionalmente. Um esforço recente, da Índia, é o projeto MirrorVerse , que oferece um conjunto de dados melhorado e um método de treinamento capaz de aprimorar o estado da arte nesse desafio particular na pesquisa em difusão.

À direita, os resultados do MirrorVerse confrontados com duas abordagens anteriores (duas colunas centrais). Fonte: https://arxiv.org/pdf/2504.15397
Como podemos ver no exemplo acima (a imagem característica no PDF do novo estudo), o MirrorVerse melhora as ofertas recentes que abordam o mesmo problema, mas está longe de ser perfeito.
No canto superior direito da imagem, vemos que os jarros de cerâmica estão um pouco à direita de onde deveriam estar, e na imagem abaixo, que tecnicamente não deveria apresentar uma reflexão da xícara, uma reflexão imprecisa foi forçada na área da direita, contrariando a lógica dos ângulos refletivos naturais.
Portanto, olharemos para o novo método não tanto porque ele pode representar o estado da arte atual em reflexão baseada em difusão, mas igualmente para ilustrar a extensão em que isso pode provar ser um problema intratável para modelos de difusão latente, tanto estáticos quanto em vídeo, uma vez que os exemplos de dados necessários de refletividade provavelmente estão entrelaçados com ações e cenários particulares.
Portanto, essa função específica dos LDMs pode continuar a não atender a abordagens específicas estruturais como NeRF, GSplat e também CGI tradicional.
O novo artigo é intitulado MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World, e vem de três pesquisadores do Vision and AI Lab, IISc Bangalore, e do Samsung R&D Institute em Bangalore. O artigo possui uma página de projeto associada, bem como um conjunto de dados no Hugging Face, com código-fonte disponibilizado no GitHub.
Método
Os pesquisadores observam desde o início a dificuldade que modelos como Stable Diffusion e Flux têm em respeitar prompts de base reflexiva, ilustrando a questão habilidosamente:

Do artigo: Modelos atuais de texto para imagem, SD3.5 e Flux, apresentando desafios significativos na produção de reflexões consistentes e geometricamente precisas.
Os pesquisadores desenvolveram MirrorFusion 2.0, um modelo generativo baseado em difusão que visa melhorar o fotorrealismo e a precisão geométrica de reflexões em espelhos em imagens sintéticas. O treinamento do modelo foi baseado no novo conjunto de dados dos pesquisadores, intitulado MirrorGen2, projetado para abordar as fraquezas de generalização observadas em abordagens anteriores.
O MirrorGen2 expande as metodologias anteriores introduzindo posicionamento aleatório de objetos, rotações aleatórias, e anclagem explícita de objetos, com o objetivo de garantir que as reflexões permaneçam plausíveis em uma gama mais ampla de poses e colocações de objetos em relação à superfície do espelho.
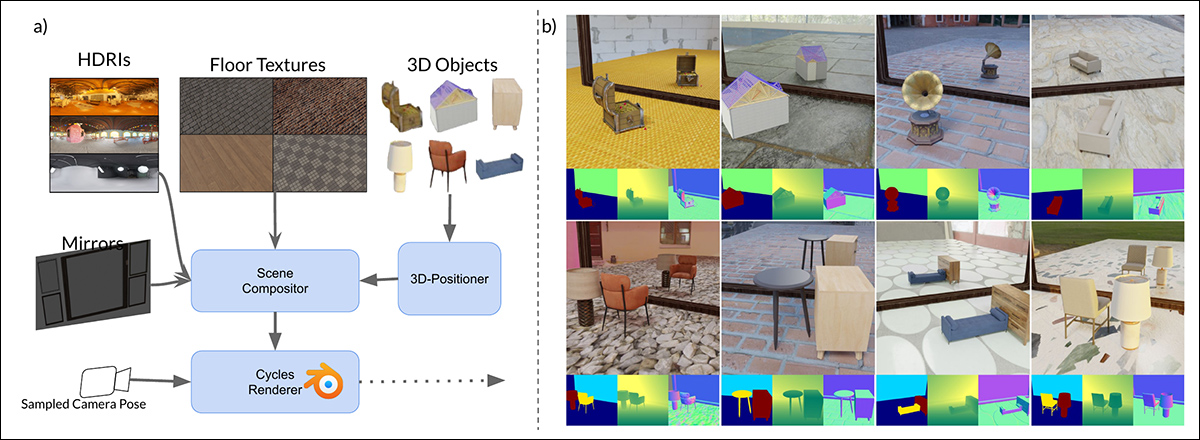
Esquema para a geração de dados sintéticos no MirrorVerse: o pipeline de geração de conjunto de dados aplicou aumentos chave ao posicionar, rotacionar e ancorar objetos dentro da cena usando o 3D-Positioner. Os objetos também são emparelhados em combinações semanticamente consistentes para simular relacionamentos espaciais complexos e oclusões.
Para reforçar ainda mais a capacidade do modelo de lidar com arranjos espaciais complexos, o pipeline do MirrorGen2 incorpora cenas de objetos emparelhados, permitindo que o sistema represente melhor oclusões e interações entre múltiplos elementos em configurações reflexivas.
O artigo afirma:
‘As categorias são emparelhadas manualmente para garantir coerência semântica – por exemplo, emparelhando uma cadeira com uma mesa. Durante a renderização, após posicionar e rotacionar o [objeto] principal, um [objeto] adicional da categoria emparelhada é amostrado e arranjado para evitar sobreposição, garantindo regiões espaciais distintas dentro da cena.’
No que diz respeito à ancoragem explícita de objetos, os autores garantiram que os objetos gerados estivessem ‘ancorados’ ao solo nos dados sintéticos de saída, ao invés de ‘flutuarem’ de maneira inadequada, o que pode ocorrer quando dados sintéticos são gerados em escala ou com métodos altamente automatizados.
Uma vez que a inovação no conjunto de dados é central para a novidade do artigo, procederemos mais cedo do que o habitual a esta seção da cobertura.
Dados e Testes
SynMirrorV2
O conjunto de dados SynMirrorV2 dos pesquisadores foi concebido para melhorar a diversidade e o realismo dos dados de treinamento sobre reflexões em espelhos, apresentando objetos 3D coletados dos conjuntos de dados Objaverse e Amazon Berkeley Objects (ABO), com essas seleções posteriormente refinadas por meio do OBJECT 3DIT, além do processo de filtragem do V1 do projeto MirrorFusion, para eliminar ativos de baixa qualidade. Isso resultou em um pool refinado de 66.062 objetos.

Exemplos do conjunto de dados Objaverse, usado na criação do conjunto de dados curado para o novo sistema. Fonte: https://arxiv.org/pdf/2212.08051
A construção de cenas envolveu colocar esses objetos sobre pisos texturizados a partir de CC-Textures e fundos HDRI do repositório CGI PolyHaven, utilizando espelhos retangulares altos ou de parede inteira. A iluminação foi padronizada com uma luz de área posicionada acima e atrás dos objetos, em um ângulo de quarenta e cinco graus. Os objetos foram escalados para se adequar a um cubo unitário e posicionados usando uma interseção precomputada do espelho e do frustum de câmeras, garantindo visibilidade.
Rotinações aleatórias foram aplicadas ao longo do eixo y, e uma técnica de ancoragem foi utilizada para evitar ‘artefatos flutuantes’.
Para simular cenas mais complexas, o conjunto de dados também incorporou múltiplos objetos arranjados segundo emparelhamentos semânticos coerentes baseados nas categorias ABO. Objetos secundários foram colocados para evitar sobreposições, criando 3.140 cenas de múltiplos objetos projetadas para capturar variadas oclusões e relações de profundidade.

Exemplos de visualizações renderizadas do conjunto de dados dos autores contendo múltiplos (mais de dois) objetos, com ilustrações de segmentação de objetos e visualizações de mapas de profundidade abaixo.
Processo de Treinamento
Reconhecendo que o realismo sintético por si só não era suficiente para uma robusta generalização para dados do mundo real, os pesquisadores desenvolveram um processo de aprendizado em três etapas para treinar o MirrorFusion 2.0.
Na Etapa 1, os autores inicializaram os pesos de ambos os ramos de condicionamento e geração com o checkpoint Stable Diffusion v1.5, e ajustaram o modelo no conjunto de dados de treinamento de um único objeto do SynMirrorV2. Diferente do projeto mencionado Reflecting Reality, os pesquisadores não congelaram o ramo de geração. Eles então treinaram o modelo por 40.000 iterações.
Na Etapa 2, o modelo foi ajustado para mais 10.000 iterações no conjunto de treinamento de múltiplos objetos do SynMirrorV2, a fim de ensinar o sistema a lidar com oclusões e arranjos espaciais mais complexos encontrados em cenas realistas.
Finalmente, na Etapa 3, mais 10.000 iterações de ajuste fino foram realizadas usando dados do mundo real do conjunto de dados MSD, utilizando mapas de profundidade gerados pelo estimator de profundidade monocular Matterport3D.

Exemplos do conjunto de dados MSD, com cenas do mundo real analisadas em mapas de profundidade e segmentação. Fonte: https://arxiv.org/pdf/1908.09101
Durante o treinamento, os prompts de texto foram omitidos por 20% do tempo de treinamento para incentivar o modelo a fazer uso ótimo das informações de profundidade disponíveis (ou seja, uma abordagem ‘mascarada’).
O treinamento ocorreu em quatro GPUs NVIDIA A100 em todas as etapas (o spec do VRAM não é fornecido, mas seria de 40GB ou 80GB por placa). Uma taxa de aprendizado de 1e-5 foi usada com um tamanho de lote de 4 por GPU, sob o otimizador AdamW.
Esse esquema de treinamento aumentou progressivamente a dificuldade das tarefas apresentadas ao modelo, começando com cenas sintéticas mais simples e avançando para composições mais desafiadoras, com a intenção de desenvolver uma transferibilidade robusta para o mundo real.
Testes
Os autores avaliaram o MirrorFusion 2.0 em comparação ao anterior estado da arte, MirrorFusion, que serviu como referência, e realizaram experimentos no conjunto de dados MirrorBenchV2, cobrindo tanto cenas de um único objeto quanto de múltiplos objetos.
Testes qualitativos adicionais foram executados em amostras do conjunto de dados MSD e do conjunto de objetos digitalizados do Google (GSO).
A avaliação utilizou 2.991 imagens de objetos únicos de categorias vistas e não vistas, e 300 cenas de dois objetos do ABO. O desempenho foi medido utilizando Peak Signal-to-Noise Ratio (PSNR); Structural Similarity Index (SSIM); e Learned Perceptual Image Patch Similarity (LPIPS) para avaliar a qualidade da reflexão na região do espelho mascarado. A similaridade CLIP foi usada para avaliar o alinhamento textual com os prompts de entrada.
Nos testes quantitativos, os autores geraram imagens usando quatro sementes para um prompt específico, selecionando a imagem resultante com a melhor pontuação SSIM. As duas tabelas de resultados relatadas para os testes quantitativos são mostradas abaixo.

Esquerda, resultados quantitativos para a qualidade de geração de reflexão de objeto único no split de objeto único do MirrorBenchV2. O MirrorFusion 2.0 superou a linha de base, com os melhores resultados destacados em negrito. À direita, resultados quantitativos para a qualidade de geração de reflexão de múltiplos objetos no split de múltiplos objetos do MirrorBenchV2. O MirrorFusion 2.0 treinado com múltiplos objetos superou a versão treinada sem eles, com os melhores resultados destacados em negrito.
Os autores comentam:
‘[Os resultados] mostram que nosso método supera o método básico e o ajuste fino em múltiplos objetos melhora os resultados em cenas complexas.’
A maior parte dos resultados, e aqueles enfatizados pelos autores, referem-se a testes qualitativos. Devido às dimensões dessas ilustrações, podemos reproduzir apenas parcialmente os exemplos do artigo.

Comparação no MirrorBenchV2: o modelo padrão não conseguiu manter reflexões precisas e consistência espacial, exibindo orientação incorreta da cadeira e reflexões distorcidas de múltiplos objetos, enquanto (os autores sustentam) o MirrorFusion 2.0 renderiza corretamente a cadeira e os sofás, com posição, orientação e estrutura precisas.
Desses resultados subjetivos, os pesquisadores opinam que o modelo padrão não conseguiu renderizar com precisão a orientação do objeto e as relações espaciais nas reflexões, frequentemente produzindo artefatos como rotação incorreta e objetos flutuantes. O MirrorFusion 2.0, treinado no SynMirrorV2, os autores sustentam, preserva a orientação e posicionamento corretos dos objetos em cenas de único e múltiplos objetos, resultando em reflexões mais realistas e coerentes.
Abaixo vemos resultados qualitativos sobre o conjunto de dados GSO mencionado:

Comparação no conjunto de dados GSO. O modelo padrão distorceu a estrutura do objeto e produziu reflexões incompletas e distorcidas, enquanto o MirrorFusion 2.0, os autores sustentam, preserva a integridade espacial e gera geometria, cor e detalhes precisos, mesmo em objetos fora da distribuição.
Aqui, os autores comentam:
‘O MirrorFusion 2.0 gera reflexões significativamente mais precisas e realistas. Por exemplo, na Fig. 5 (a – acima), o MirrorFusion 2.0 reflete corretamente as alças da gaveta (destacadas em verde), enquanto o modelo padrão produz uma reflexão implausível (destacada em vermelho).
‘Da mesma forma, para a “caneca branca-amarela” na Fig. 5 (b), o MirrorFusion 2.0 entrega uma geometria convincente com artefatos mínimos, enquanto o modelo padrão falha em capturar com precisão a geometria e a aparência do objeto.’
O teste qualitativo final foi realizado contra o conjunto de dados do mundo real MSD (resultados parciais mostrados abaixo):

Resultados de cena do mundo real comparando MirrorFusion, MirrorFusion 2.0, e MirrorFusion 2.0, ajustado no conjunto de dados MSD. O MirrorFusion 2.0, os autores sustentam, captura detalhes complexos da cena com mais precisão, incluindo objetos desordenados em uma mesa e a presença de múltiplos espelhos dentro de um ambiente tridimensional. Apenas resultados parciais são mostrados aqui, devido às dimensões dos resultados no artigo original.
Aqui, os autores observam que, embora o MirrorFusion 2.0 tenha apresentado um bom desempenho nos dados do MirrorBenchV2 e GSO, inicialmente teve dificuldades com cenas complexas do mundo real no conjunto de dados MSD. O ajuste fino do modelo em um subconjunto de MSD melhorou sua capacidade de lidar com ambientes desordenados e múltiplos espelhos, resultando em reflexões mais coerentes e detalhadas no conjunto de testes retido.
Além disso, um estudo com usuários foi conduzido, onde 84% dos usuários relataram ter preferido as gerações do MirrorFusion 2.0 em relação ao método padrão.
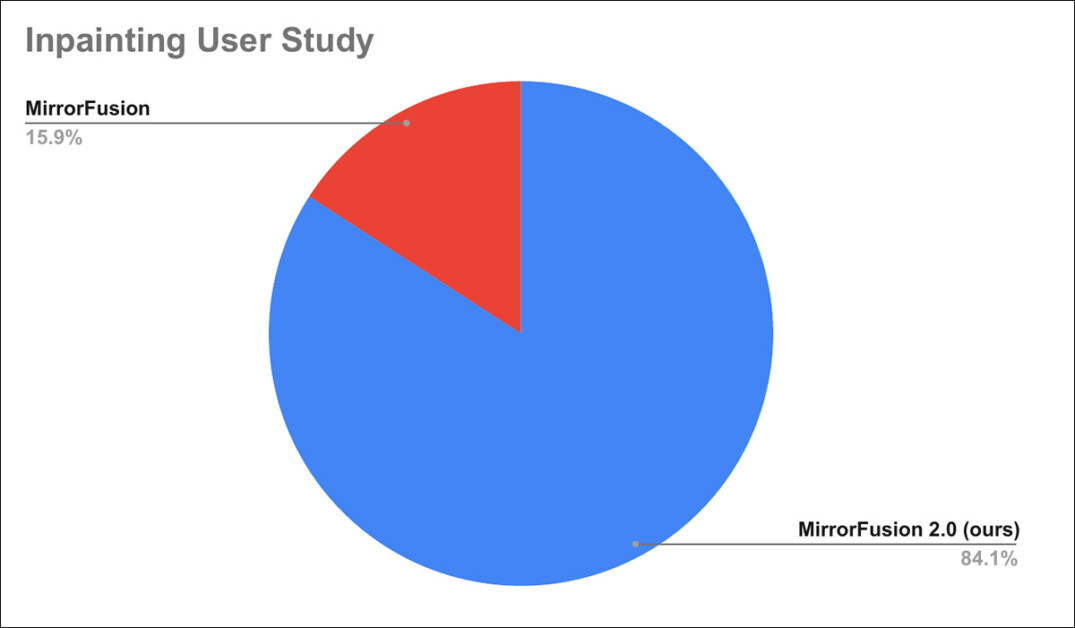
Resultados do estudo com usuários.
Como os detalhes do estudo com usuários foram relegados ao apêndice do artigo, encaminhamos o leitor para isso para as especificidades do estudo.
Conclusão
Embora vários dos resultados mostrados no artigo sejam melhorias impressionantes sobre o estado da arte, o estado da arte para essa busca particular é tão abominável que mesmo uma solução agregada não convincente pode prevalecer com um mínimo de esforço. A arquitetura fundamental de um modelo de difusão é tão hostil ao aprendizado e demonstração confiáveis da física consistente que o problema em si é verdadeiramente proposto, e aparentemente não está disposto a uma solução elegante.
Além disso, adicionar dados a modelos existentes já é o método padrão de remediar lacunas no desempenho dos LDMs, com todas as desvantagens listadas anteriormente. É razoável supor que se futuros conjuntos de dados em alta escala prestassem mais atenção à distribuição (e anotação) de pontos de dados relacionados à reflexão, poderíamos esperar que os modelos resultantes lidassem melhor com esse cenário.
Ainda assim, o mesmo se aplica a várias outras dificuldades na saída dos LDMs – quem pode dizer qual delas mais merece o esforço e o dinheiro envolvidos no tipo de solução que os autores do novo artigo propõem aqui?
Publicado pela primeira vez na segunda-feira, 28 de abril de 2025

Conteúdo relacionado

A RAG torna os LLMs menos seguros? Pesquisa da Bloomberg revela perigos ocultos.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre a cobertura líder da indústria em IA. Saiba Mais……

Hugging Face lança braço robótico impresso em 3D a partir de R$100
[the_ad id="145565"] A Hugging Face, a startup mais conhecida pela plataforma de IA de mesmo nome, está vendendo um braço robótico programável e imprimível em 3D que pode pegar…

O sucesso da DeepSeek demonstra por que a motivação é fundamental para a inovação em IA
[the_ad id="145565"] Participe de nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre reportagens de IA líderes da indústria. Saiba…